ALLPCB
ALLPCB


Summary
This article uses convolutional neural networks (CNNs) to classify large-scale motion data collected from wearable sensors and compares different methods of converting the sensor time series into 2D image-like inputs. The best configuration achieved 92.1% accuracy on a 50-class gym exercise classification task.
Why CNN instead of RNN
CNNs were chosen instead of recurrent neural networks, which are commonly used for sequential data, because individual exercise repetitions (for example, a single dumbbell lift) are short, typically under 4 seconds, and do not require long-term memory during training.
Dataset
The dataset comes from PUSH, a forearm-worn wearable device for measuring athletes' movements. It contains 49,194 sets composed of 449,260 repetition exercises collected from 1,441 male and 307 female athletes. Each repetition is treated as one sequence.
Preprocessing
Because the CNN input length is fixed, all sequences were fixed to a length of 784 samples. Sequences longer than 784 samples were truncated to 784 samples, and shorter sequences were zero-padded.
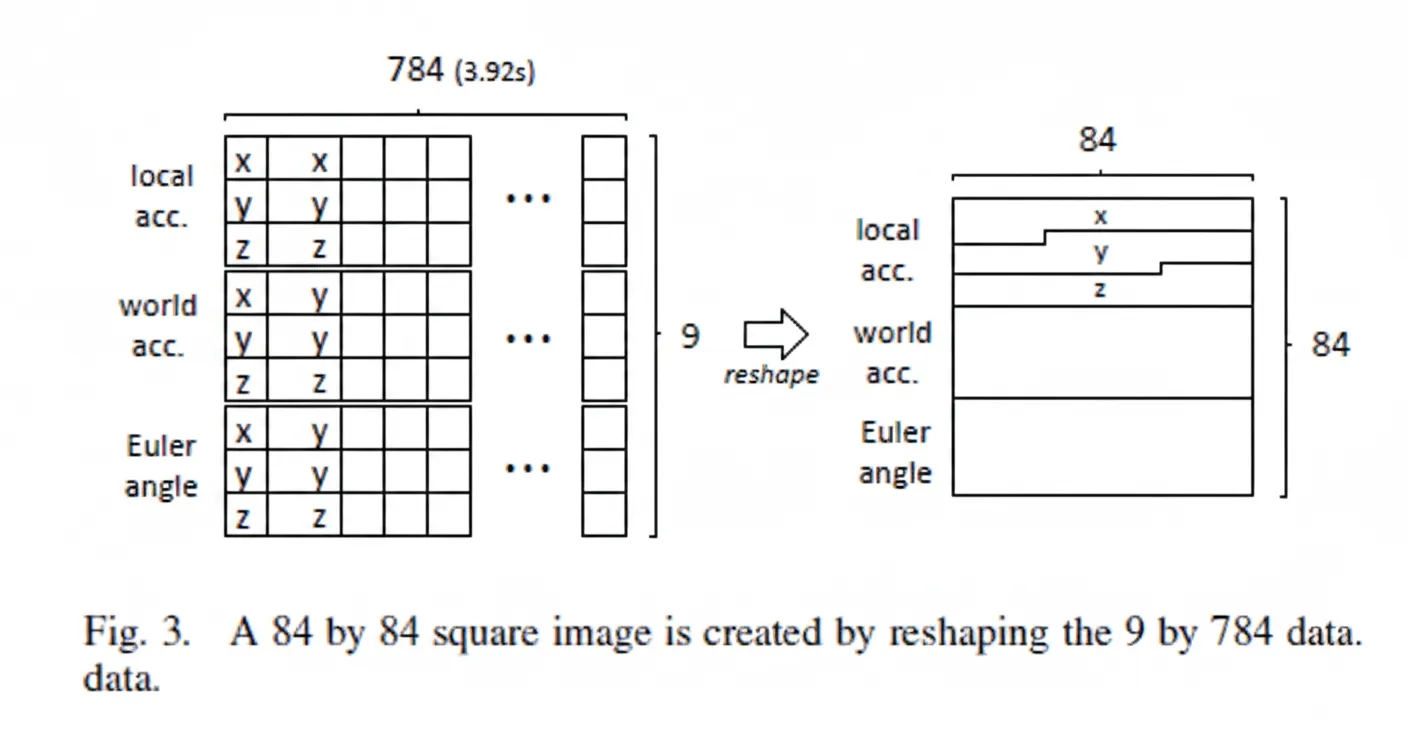
The device is mounted on the upper arm and measures acceleration and orientation using an onboard accelerometer and gyroscope. Each time series has nine features: Acc x, Acc y, Acc z in the local frame; Acc x, Acc y, Acc z in the world frame; and EulerAngle x, EulerAngle y, EulerAngle z in the world frame. Data were sampled at 200 Hz.
Converting Time Series to 2D Inputs
There are three approaches to convert the 9x784 time series into 2D inputs. Different image formats change which elements become adjacent under convolution, which can cause convolutions between unrelated features.
1. Rectangular 9x784 image
The raw 9x784 time series is treated as a rectangular 2D image with 9 rows and 784 columns.
2. Three-channel 3x784x3 tensor
The three feature groups (local accelerations, world accelerations, and Euler angles) are treated like RGB channels to create a 3x784x3 tensor so convolutions operate separately on each group.
3. Reshaped 84x84 square
The 9x784 time series is reshaped into an 84x84 square matrix. An example is shown below.
Effect of 2D Layout on Convolutions
For the 9x784 layout, with stride 1 convolutions (referred to as 9x784 full), elements located on the top row, such as Acc_x_local, do not convolve with elements on the bottom row, such as Euler_Angle_z, until deeper layers. Features placed in intermediate rows, for example Acc_z_world on row 6 and Euler_Angle_x on row 7, will have many convolution opportunities because they are adjacent.
For the 3x784x3 layout, convolution is applied separately across the three channels, preventing cross-group convolutions between different feature groups.
To avoid unwanted cross-group convolutions in the 9x784 layout, convolution strides can be adjusted so that kernels do not span across groups. This configuration is referred to as 9x784 disjointed. The example below illustrates the difference.

In the left example, a vertical stride of 1 causes convolution across different groups. In the right example, a vertical stride of 3 prevents convolutions across groups by keeping kernels within each group.
Experimental Result
Experiments show that treating the distinct feature groups (local acceleration, world acceleration, Euler angle) as separate image channels (3x784x3) yields better performance than using the square 84x84 image or the rectangular 9x784 image.