ALLPCB
ALLPCB


Overview
When tuning network application performance on Linux, it is common to adjust TCP-related kernel parameters, especially those related to buffers and queues. Many articles list which parameters to change, but their meanings are often confused or forgotten. This article organizes the relevant parameters from the server perspective across three paths: connection establishment, packet reception, and packet sending.
1. Connection establishment
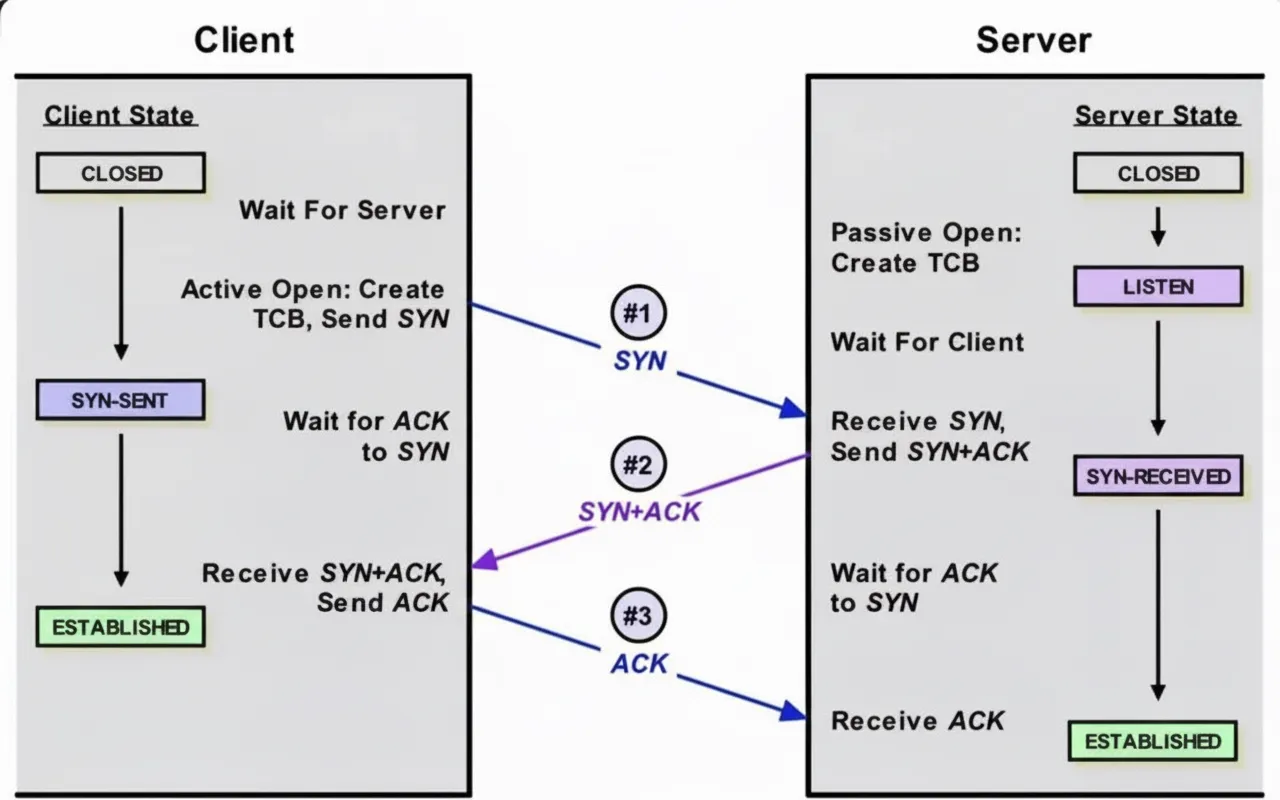
During connection setup the client sends a SYN, the server replies with SYN+ACK and records the connection in the half-open (SYN_RECV) queue. When the client returns the ACK completing the three-way handshake, the connection moves to the accept queue in ESTABLISHED state, waiting for the application to call accept(). Two kernel queues are involved:
- Half-open (SYN) queue: stores SYN_RECV connections. Its length is controlled by net.ipv4.tcp_max_syn_backlog.
- Accept queue: stores ESTABLISHED connections waiting for accept(). Its length is min(net.core.somaxconn, backlog). The backlog value comes from the listen call: int listen(int sockfd, int backlog); if the backlog provided to listen is larger than net.core.somaxconn, the accept queue length is limited to net.core.somaxconn.
To mitigate SYN flooding (clients sending SYNs without completing the handshake), Linux supports SYN cookies, controlled by net.ipv4.tcp_syncookies. When enabled, connection information is encoded into the initial sequence number returned in the SYN+ACK. The server avoids storing the half-open connection; when the client completes the handshake with the ACK, the server reconstructs the connection state from the encoded sequence number to finish setup.
2. Packet reception
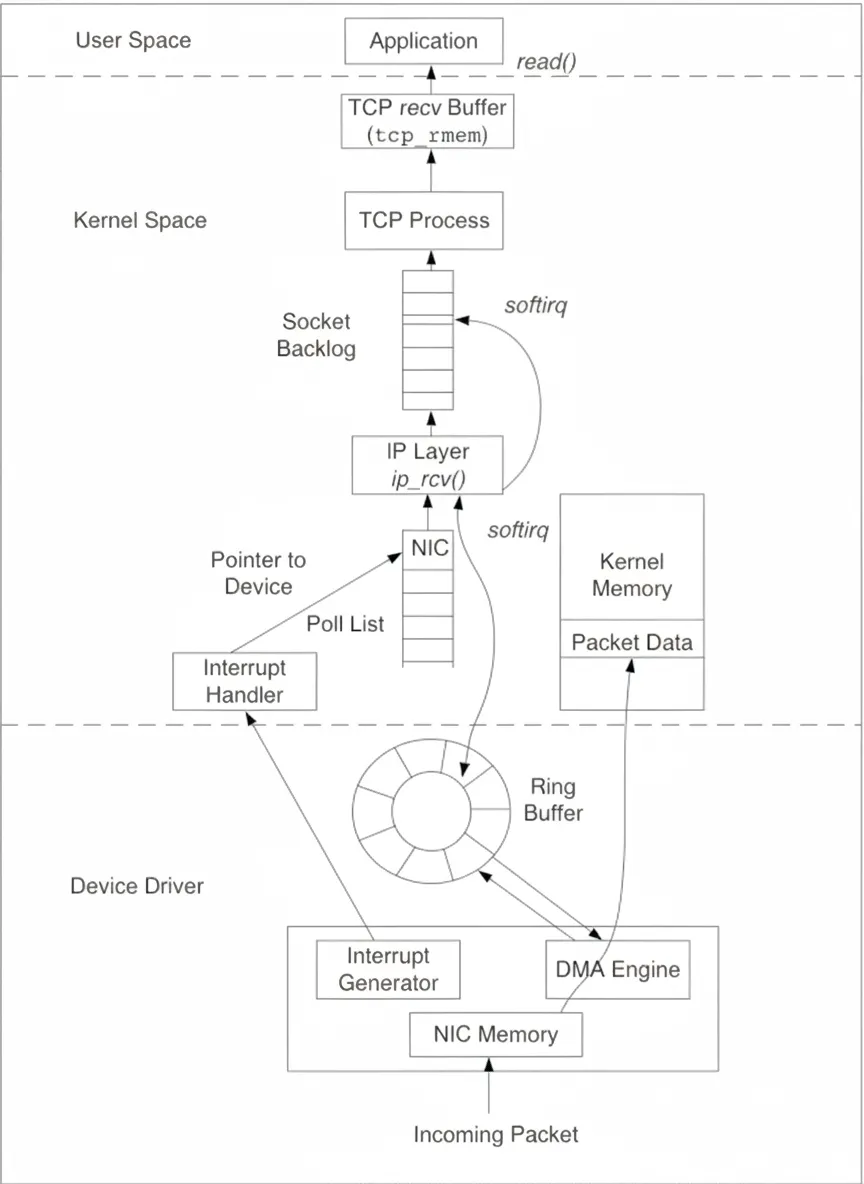
Packet reception flows from the NIC driver, through kernel space, and finally to user-space applications. The kernel represents packets using the sk_buff data structure (socket kernel buffers). When a new packet arrives, the NIC uses DMA to place packet data into kernel memory and writes descriptors into a Ring Buffer. The Ring Buffer contains descriptors that point to sk_buff structures rather than the packet payload itself. If the Ring Buffer is full, additional incoming packets are dropped. After successful reception, the NIC raises an interrupt and the kernel passes the packet to the IP layer. After IP processing the packet is queued for TCP. TCP updates its state machine and eventually places payload into the socket receive buffer. Note that TCP ACKs indicate the operating system kernel has received the packet, but do not guarantee the application has processed it; application-level acknowledgement may still be needed in some protocols.
2.1 Bonding modes
When a host has multiple NICs, Linux can bond them into a single virtual interface. Bonding can increase throughput and provide redundancy. Linux supports several bonding modes; see the kernel document "Linux Ethernet Bonding Driver HOWTO" for details. Common modes:
- Mode 0 (balance-rr): round-robin, provides load balancing and fault tolerance.
- Mode 1 (active-backup): active/backup, only one slave is active and others are backup.
- Mode 2 (balance-xor): XOR-based selection using source and destination MAC addresses.
- Mode 3 (broadcast): send packets on all slaves.
- Mode 4 (802.3ad): IEEE 802.3ad dynamic link aggregation (LACP), groups links with same speed and duplex.
- Mode 5 (balance-tlb): adaptive transmit load balancing.
- Mode 6 (balance-alb): adaptive load balancing.
2.2 NIC multi-queue and interrupt affinity
Modern NICs support multiple queues. With multi-queue support, interrupts for each queue can be bound to different CPU cores to leverage multiple cores for packet processing. To check NIC multi-queue support use lspci -vvv and look for MSI-X Enable and Count > 1. To see whether multiple queues are active, inspect /proc/interrupts for entries like eth0-TxRx-0. Interrupt numbers listed in /proc/interrupts map to per-IRQ affinity files in /proc/irq/<IRQ>/smp_affinity. The affinity value is a hexadecimal bitmask where each bit represents a CPU core (for example 00000001 is CPU0, 00000002 is CPU1, 00000003 is CPU0 and CPU1).
If affinity is unbalanced, set it manually. Example commands:
echo "1" > /proc/irq/99/smp_affinity echo "2" > /proc/irq/100/smp_affinity echo "4" > /proc/irq/101/smp_affinity echo "8" > /proc/irq/102/smp_affinity echo "10" > /proc/irq/103/smp_affinity echo "20" > /proc/irq/104/smp_affinity echo "40" > /proc/irq/105/smp_affinity echo "80" > /proc/irq/106/smp_affinity
2.3 Ring Buffer
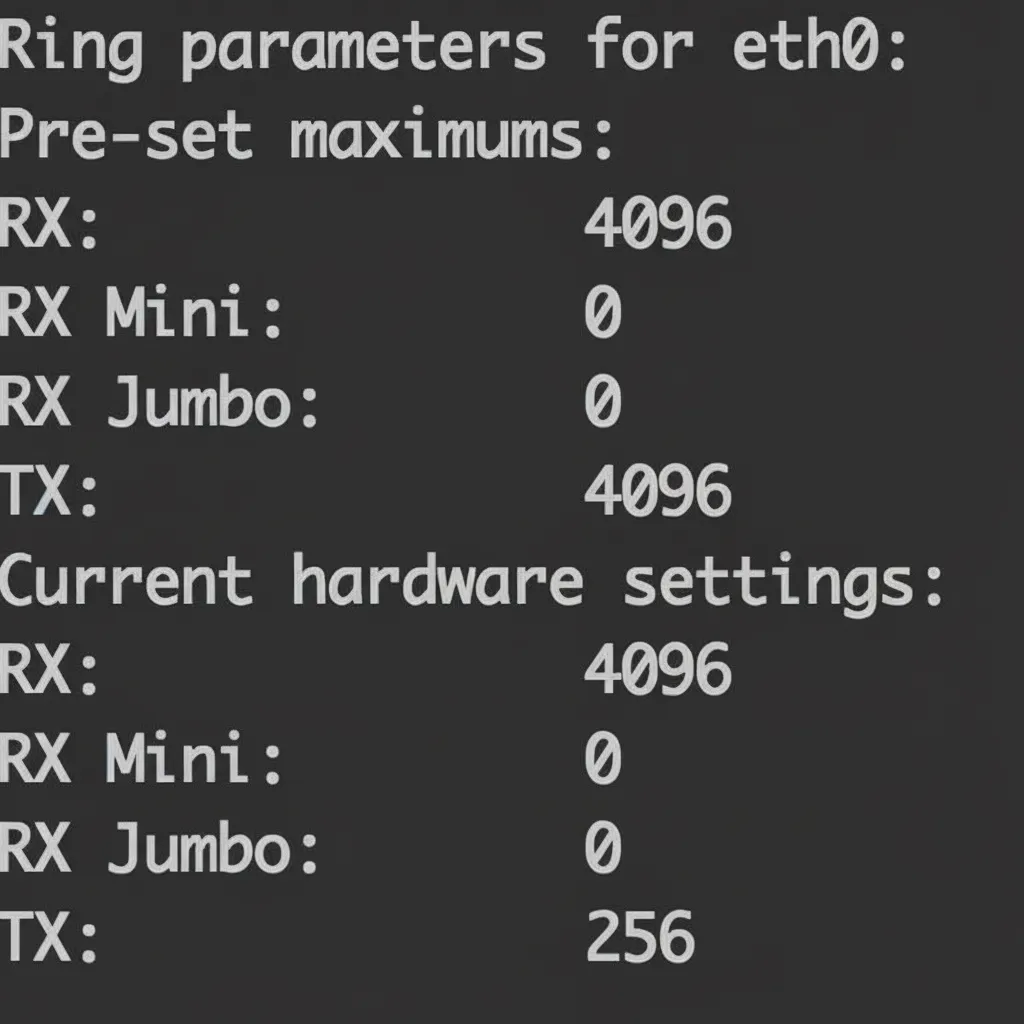
The Ring Buffer resides between the NIC and the IP layer and acts as a FIFO of descriptors to sk_buff structures. Use ethtool -g eth0 to view current ring buffer settings. The example shows RX ring size 4096 and TX ring size 256. Use ifconfig to monitor RX/TX statistics and queue behavior.
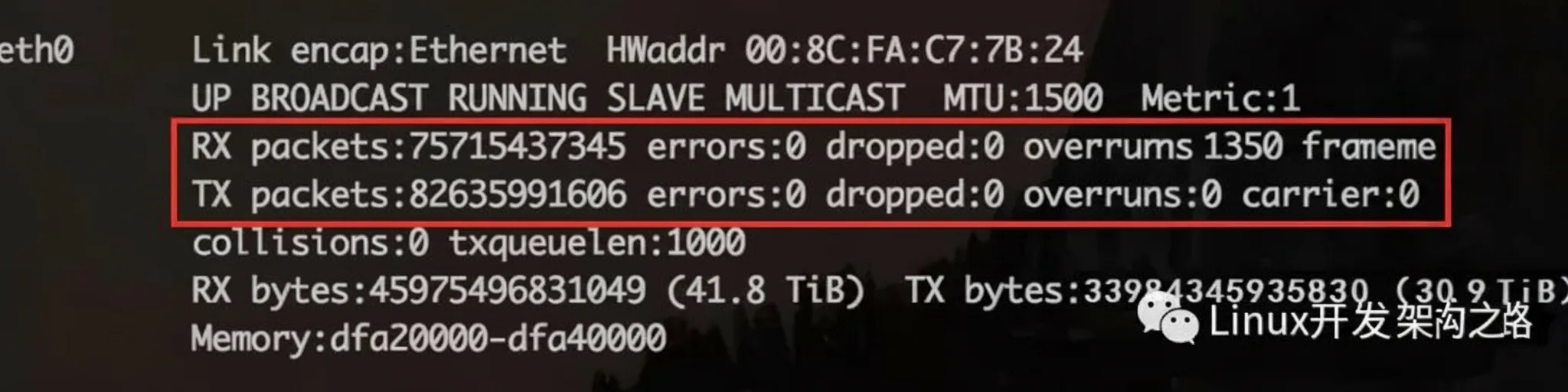
Key counters:
- RX errors: total receive errors.
- RX dropped: packets that reached the Ring Buffer but were dropped during copy to kernel memory due to insufficient resources.
- RX overruns: packets dropped in the NIC before entering the Ring Buffer, often caused by the CPU not servicing interrupts quickly enough or uneven interrupt distribution.
If dropped counts increase persistently, consider increasing the Ring Buffer size with ethtool -G.
2.4 Input packet queue
When incoming packet rate exceeds kernel TCP processing rate, packets are buffered in the input queue prior to TCP. The length of this queue is controlled by net.core.netdev_max_backlog.
2.5 Receive buffer (recvBuffer)
The socket receive buffer is critical for TCP performance. The bandwidth-delay product (BDP) equals bandwidth multiplied by RTT and represents the maximum unacknowledged data in flight. To achieve maximum throughput, set the receive buffer at least as large as the BDP: recvBuffer >= bandwidth * RTT. For example, with 100 Mbps bandwidth and 100 ms RTT:
BDP = 100 Mbps * 100 ms = (100 / 8) * (100 / 1000) = 1.25 MB
Since Linux 2.6.17 the receive buffer auto-tuning is enabled. When net.ipv4.tcp_moderate_rcvbuf is 1, auto-tuning adjusts the per-connection receive buffer between the minimum and maximum values specified by the three-value array net.ipv4.tcp_rmem (min, default, max). The dynamic tuning mechanism tries to balance performance and resource usage, so in many cases manual fixed sizing is not recommended. Set the tcp_rmem maximum to the BDP when dynamic tuning is enabled.
If net.ipv4.tcp_moderate_rcvbuf is 0 or an application sets SO_RCVBUF, dynamic tuning is disabled. The default receive buffer then comes from net.core.rmem_default unless tcp_rmem is set, which overrides the default. When tuning is disabled, consider setting the default buffer to the BDP. Note that buffers also need space for socket metadata; net.ipv4.tcp_adv_win_scale affects how much extra space is reserved. For example, with tcp_adv_win_scale = 1 half of the buffer is reserved for overhead, so the effective payload capacity differs accordingly.
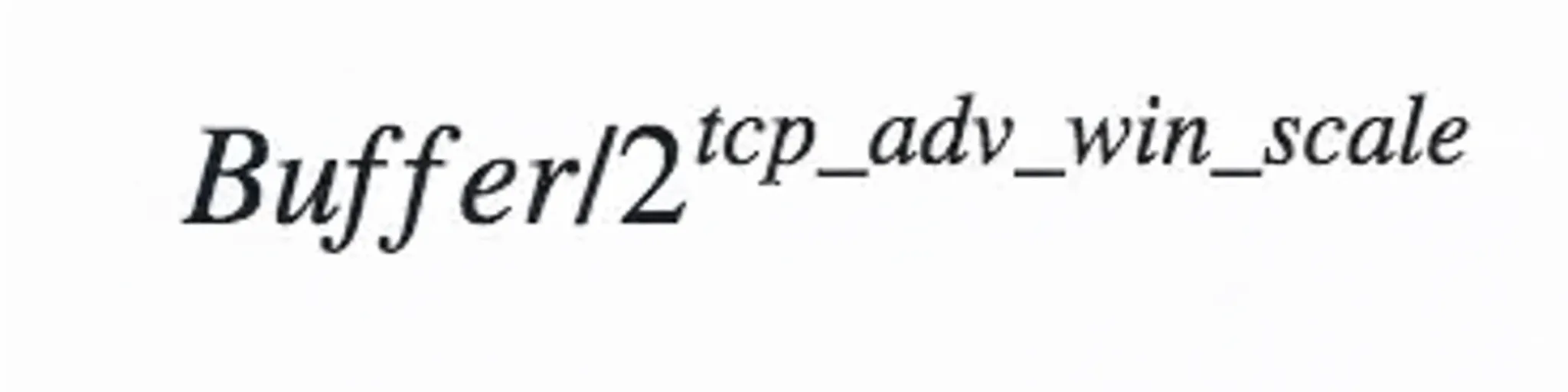
3. Packet sending
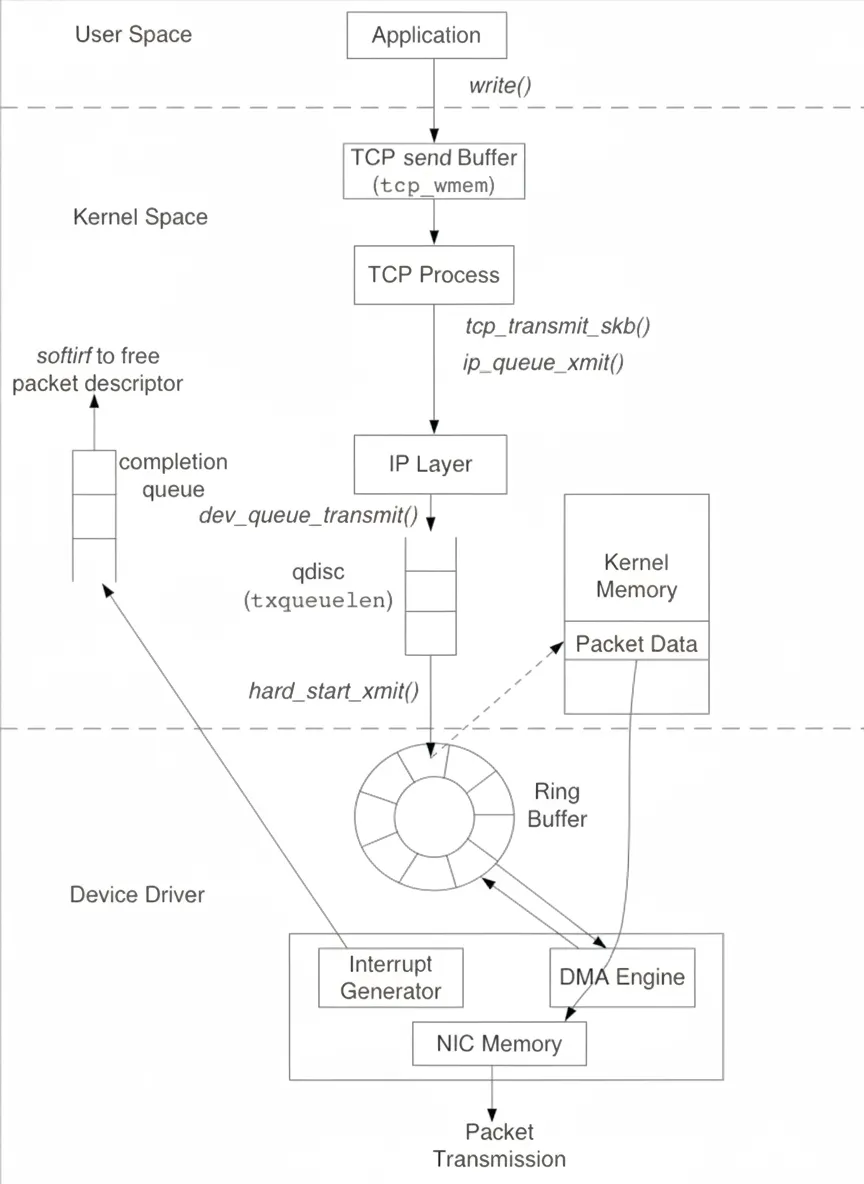
Sending follows the reverse path: user space writes into the TCP send buffer, TCP forms packets and hands them to IP. IP places packets into the queuing discipline (QDisc). After successful enqueueing in QDisc, sk_buff descriptors are placed into the Ring Buffer for the NIC to DMA them out to the wire.
3.1 Send buffer (sendBuffer)
Send buffer auto-tuning is enabled by default and controlled by net.ipv4.tcp_wmem as a three-value array (min, default, max). If tcp_wmem is set it overrides net.core.wmem_default. The kernel automatically adjusts the send buffer between the min and max. If an application sets SO_SNDBUF via setsockopt(), auto-tuning is disabled and the value is capped by net.core.wmem_max.
3.2 QDisc (queuing discipline)
QDisc sits between the IP layer and the NIC Ring Buffer. Whereas the Ring Buffer is a simple FIFO implemented in the driver, QDisc implements higher-level traffic management such as classification, priority, and rate shaping. Use tc to configure QDisc. QDisc queue length is controlled by txqueuelen, which is per-interface and visible via ifconfig.
Adjust txqueuelen with:
ifconfig eth0 txqueuelen 2000
3.3 Ring Buffer (transmit)
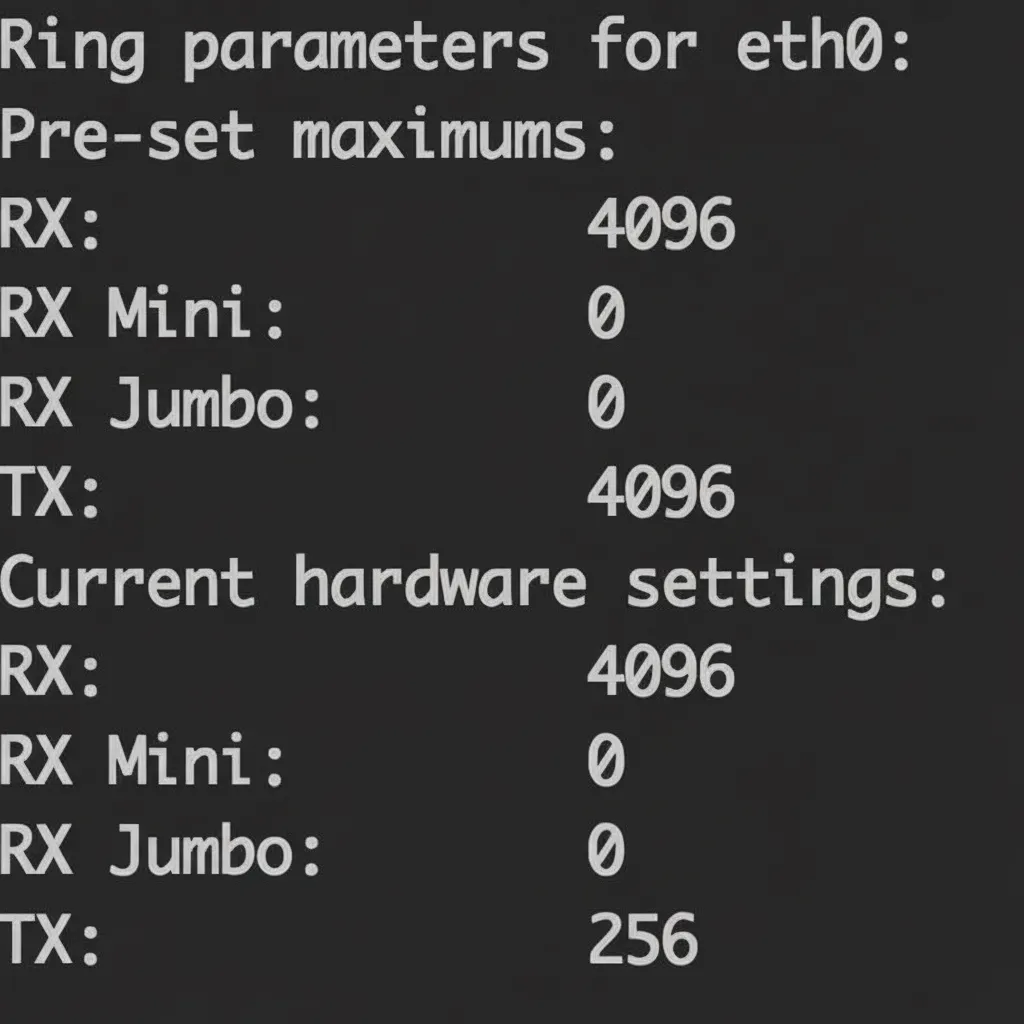
The transmit Ring Buffer length corresponds to the TX entry shown by ethtool -g. Adjust TX ring size with ethtool -G.
3.4 TCP segmentation and checksum offload
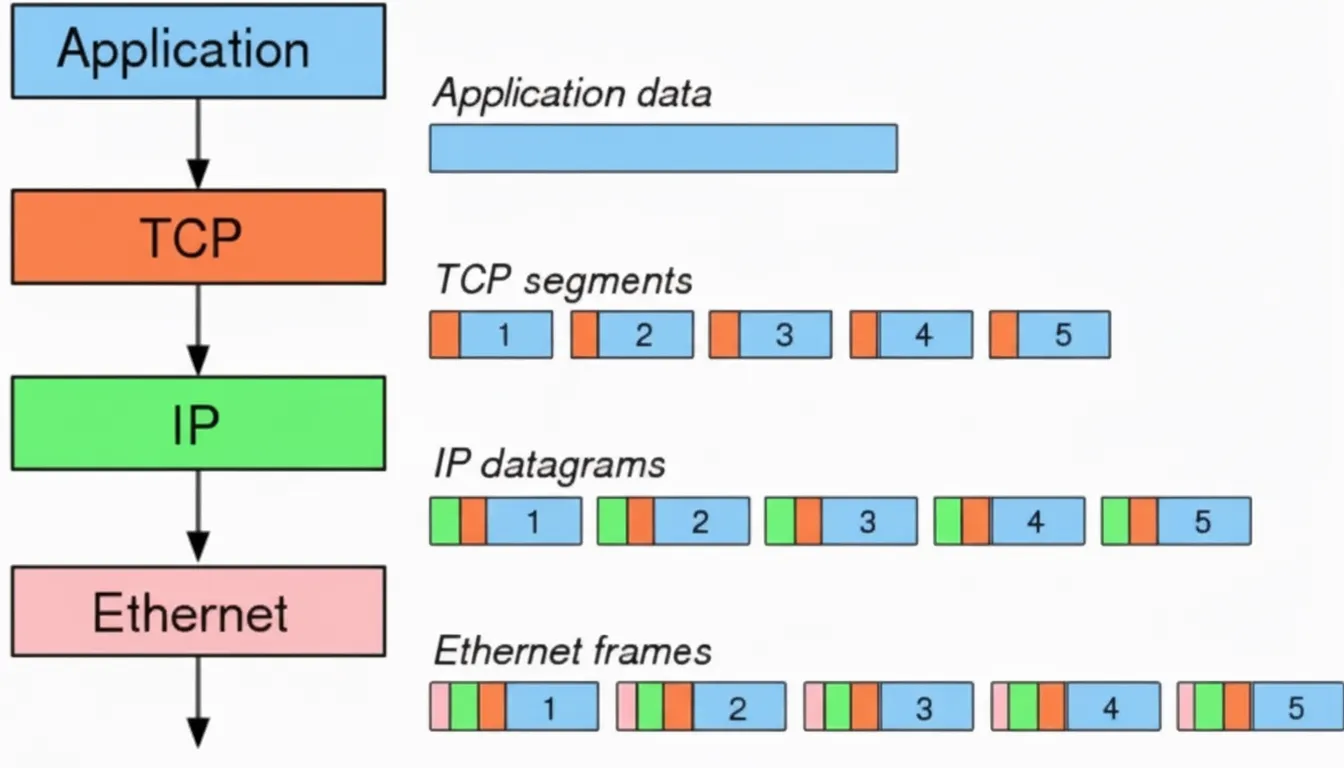
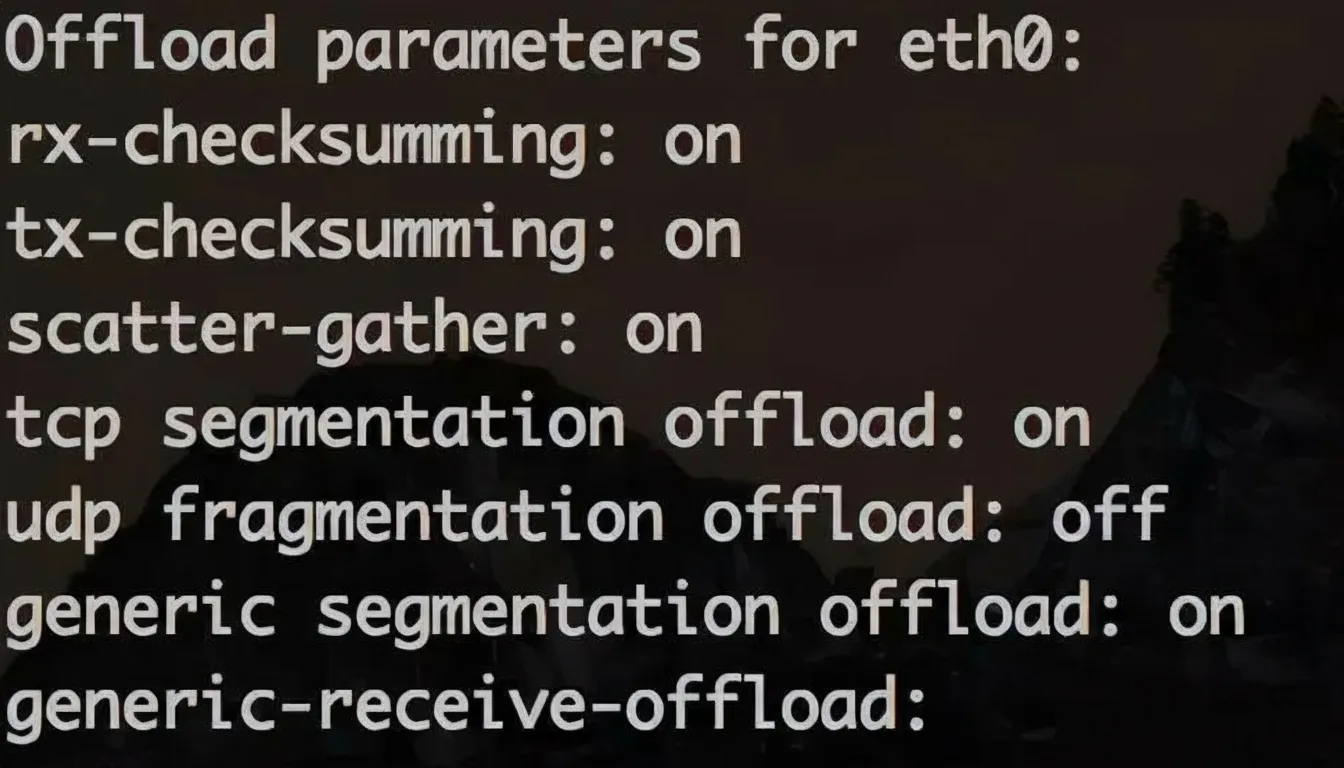
The OS can offload certain TCP/IP tasks to the NIC to save CPU resources, notably segmentation and checksum computation. For example, with an Ethernet MTU of 1500 bytes and a payload of 7300 bytes, the packet must be segmented into multiple MTU-sized frames. Offloading segmentation to the NIC saves CPU cycles during packet formation even though the wire still sees the same number of packets. Use ethtool -k eth0 to view offload capabilities and ethtool -K eth0 to change them. Example to disable TCP segmentation offload:
sudo ethtool -K eth0 tso off
3.5 Multi-queue and bonding on transmit
Multi-queue and bonding influence transmit-side scaling and are configured as described in the reception section.
End of summary.