ALLPCB
ALLPCB


Overview
When developing embedded systems software, you will often see various forms of alignment in code. Many developers follow alignment rules without fully understanding why they are necessary or what problems misalignment can cause. This article summarizes the main reasons for memory alignment.
CPU Architecture and MMU Requirements
Some RISC instruction set CPUs do not support unaligned memory accesses for variables, for example MIPS, PowerPC, and certain DSPs. An unaligned access on those architectures triggers an unaligned exception.
The ARM instruction set began supporting unaligned memory accesses from ARMv6 (ARM11). Older ARM9 CPUs do not support unaligned accesses. ARM architecture features have evolved over iterations.

Although modern ARMv7 and ARMv8 Cortex-A series CPUs support unaligned memory accesses, many SoCs contain heterogeneous processors that must coordinate. A main ARM64 CPU running Linux or Android may support unaligned access, but co-processors of other architectures or older cores (for example MIPS, ARM7, Cortex-R/M series, or 8051 microcontroller cores) may share the same physical memory in different regions and run their own firmware. When partitioning address space, alignment must be considered because some co-processors may not support unaligned accesses. Firmware written for those co-processors must also be aware of whether the CPU supports unaligned memory accesses.
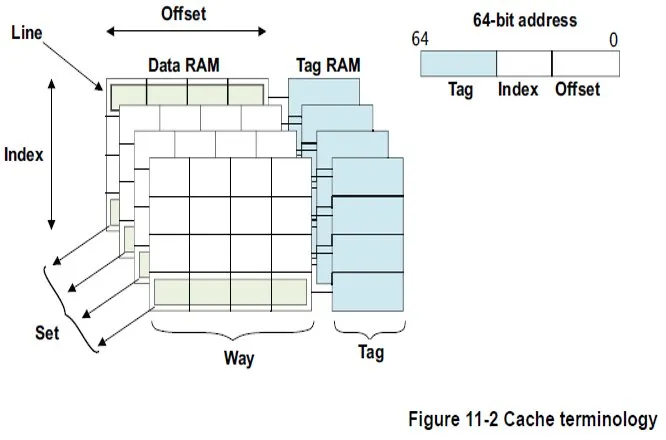
The MMU virtual address management in ARM also imposes alignment requirements. The following diagrams show the MMU translation tables and their indexing relationships.

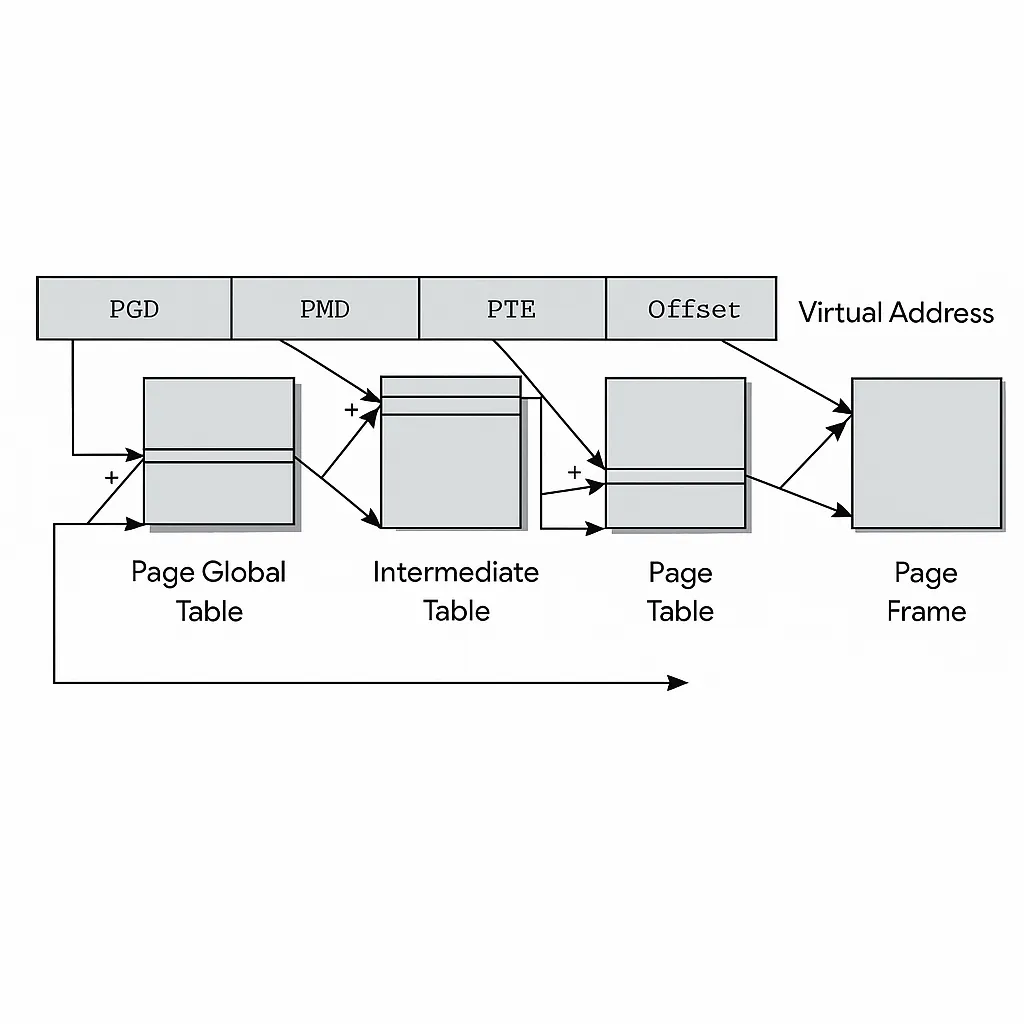
ARM MMU alignment requirements
For ARM 32-bit architecture, the L1 translation table base address must be aligned to a 16 KB boundary. The L2 translation table address must be aligned to a 1 KB boundary.
For ARM 64-bit architecture, bits VA[28:21] must be aligned to a 64 KB granule, and bits VA[20:16] must be aligned to a 4 KB granule.
ARM memory ordering defines different memory types with different support for unaligned accesses. Only Normal memory supports unaligned accesses. Strongly-ordered and Device memory do not support unaligned accesses. The memory type rules are summarized in the following diagram.
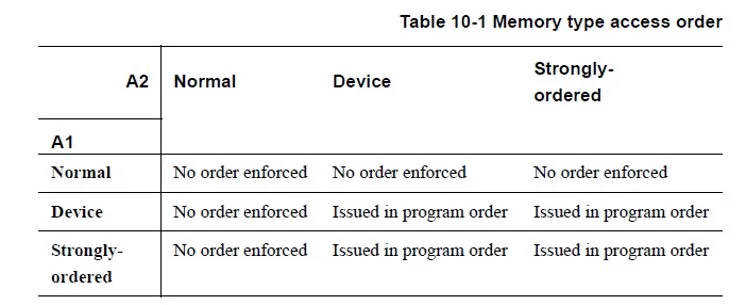
Only Normal memory supports unaligned memory access.
Strongly-ordered and Device memory do not support unaligned memory access.
Impact on Atomic Operations
Even though modern ARMv7 and ARMv8 CPUs support unaligned accesses, such accesses do not guarantee atomicity. The diagrams below illustrate memory layouts for aligned and unaligned variables.
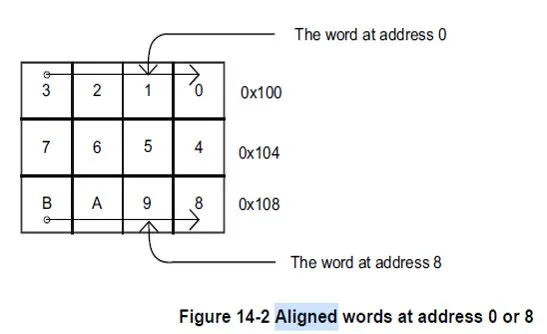
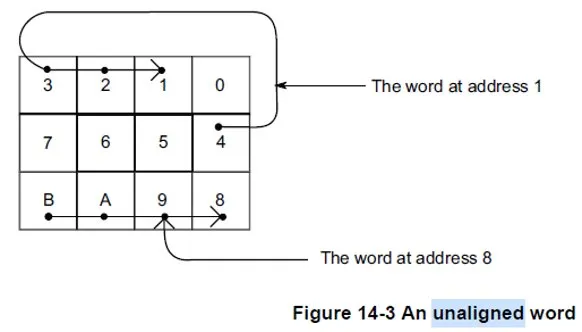
An aligned variable can be loaded into a general-purpose CPU register in a single operation, so reads and writes can be atomic. Unaligned variable accesses may require two separate memory operations, and thus cannot guarantee atomicity. If two memory operations are interrupted by asynchronous events, the variable may be partially updated, breaking atomicity.
ARM NEON Requirements
Modern ARM CPUs commonly include a NEON co-processor used for SIMD parallel vector acceleration in floating-point and multimedia workloads. The basic principle of NEON SIMD vector processing is shown below.
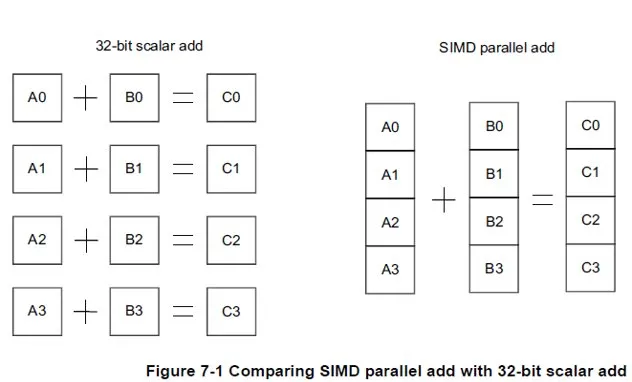
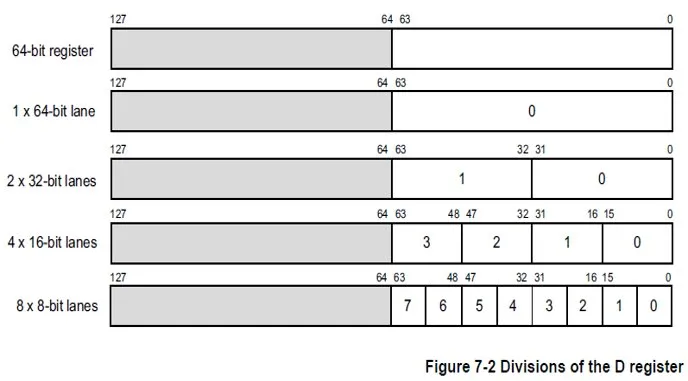
NEON supports unaligned memory accesses, but unaligned NEON access usually incurs a two-instruction-cycle penalty.
To use NEON efficiently, align variables according to the NEON register lane size. For example, align data on 8-bit boundaries for 8-bit lanes, 16-bit boundaries for 16-bit lanes, etc. NEON lane configurations are flexible as specified in architecture documentation.
Performance Impact
Although modern ARM CPUs support unaligned accesses, such accesses often cause noticeable performance degradation because they increase the number of load/store operations and hence instruction cycles.
Performance analysis tools can reveal the impact of unaligned accesses. For example, perf provides an alignment-faults event to count unaligned memory access events.
Cache Line Alignment
In addition to alignment based on CPU access width, cache line size must be considered during optimization. Cache line is the unit of data transfer between cache and memory; caches typically read or write entire cache lines at once.
Cache line length varies across ARM cores. When porting and optimizing software from one ARM platform to another, check whether cache line sizes differ and whether cache line alignment should be adjusted.
The cache line sizes of several ARMv7 reference CPUs are documented. ARMv8 64-bit reference CPUs (A53, A57, A72, A73) commonly have a 64-byte cache line, but vendor-customized ARM cores may differ. Refer to the relevant TRM for alignment and optimization.
The following example shows read/write performance jitter when cache line alignment is not handled. The test idea is to perform many read/write operations on arrays of varying sizes and measure time. When array size is smaller than the cache line size, read/write times remain stable. When array size crosses the cache line size, read/write time shows significant jitter.
#include"stdio.h"#include#includelongtimediff(clock_tt1,clock_tt2){longelapsed;elapsed=((double)t2-t1)/CLOCKS_PER_SEC*1000;returnelapsed;}intmain(intargc,char*argv[])#*******{intarray_size=atoi(argv[1]);intrepeat_times=1000000000;longarray[array_size];for(inti=0;iVariables that are not aligned to the same cache line can cause non-atomic cross-cache-line operations in multi-core SMP systems, introducing data corruption risks. The following test demonstrates this issue using a 68-byte struct when the system cache line size is 64 bytes. A structure with 60 bytes of padding followed by an 8-byte variable may place parts of that variable in different cache lines, so updates are not atomic. Multiple threads repeatedly apply bitwise inversion to a global variable value.v. Intuitively, the final value should be all zeros or all ones, but the actual result can be a mixture of bits due to non-atomic cross-cache-line updates.
#include#include#include#includeusingnamespacestd;staticconstint64_tMAX_THREAD_NUM=128;staticint64_tn=0;staticint64_tloop_count=0;#pragmapack(1)structdata{int32_tpad[15];int64_tv;};#pragmapack()staticdatavalue__attribute__((aligned(64)));staticint64_tcounter[MAX_THREAD_NUM];voidworker(int*cnt){for(int64_ti=0;i< loop_count; ++i) {const int64_t t = value.v;if (t != 0L && t != ~0L) {*cnt += 1;}value.v = ~t;asm volatile("" ::: "memory");}}int main(int argc, char *argv[]){pthread_t threads[MAX_THREAD_NUM];/* Check arguments to program*/if(argc != 3) {fprintf(stderr, "USAGE: %s\n",argv[0]);exit(1);}/*Parseargument*/n=min(atol(argv[1]),MAX_THREAD_NUM);loop_count=atol(argv[2]);/*Don'tbotherwithformatchecking*//*Startthethreads*/for(int64_ti=0L;i< n; ++i) {pthread_create(&threads[i], NULL, (void* (*)(void*))worker, &counter[i]);}int64_t count = 0L;for (int64_t i = 0L; i < n; ++i) {pthread_join(threads[i], NULL);count += counter[i];}printf("data size: %lu\n", sizeof(value));printf("data addr: %lX\n", (unsigned long)&value.v);printf("final: %016lX\n", value.v);return 0;}