ALLPCB
ALLPCB


Overview
This article presents BEV-MAE, an efficient pretraining algorithm for 3D point cloud perception that leverages large amounts of unlabeled LiDAR data to reduce reliance on labeled point clouds. BEV-MAE first applies a bird's-eye-view (BEV) guided masking strategy to the 3D point cloud input; the masked points are replaced by a shared learnable token. The modified point cloud is then passed through a 3D encoder and a lightweight decoder. The decoder reconstructs the masked points and predicts point density in masked regions. On the Waymo autonomous driving dataset, BEV-MAE achieves notable 3D detection accuracy gains with low pretraining cost. Using TransFusion-L as the detector backbone, BEV-MAE also yields state-of-the-art single-modality LiDAR 3D detection results on nuScenes.
Research background
3D object detection is a core task for autonomous driving. Recent progress in LiDAR-based 3D detection has been driven by larger labeled datasets and models. However, most LiDAR-based detectors are trained from scratch, which has two drawbacks. First, training from scratch relies heavily on large amounts of labeled data: accurate 3D bounding boxes and class labels require substantial manual effort and are costly and time-consuming (for example, annotating an object on the KITTI dataset takes roughly 114 seconds). Second, autonomous vehicles can collect large volumes of unlabeled point clouds during operation, but the training-from-scratch paradigm does not make effective use of this unlabeled data.
Method
The authors propose a self-supervised pretraining method tailored to autonomous driving scenes: BEV-MAE, a bird's-eye-view masked autoencoder framework for pretraining 3D detectors used in driving scenarios. The overall pipeline is shown below:
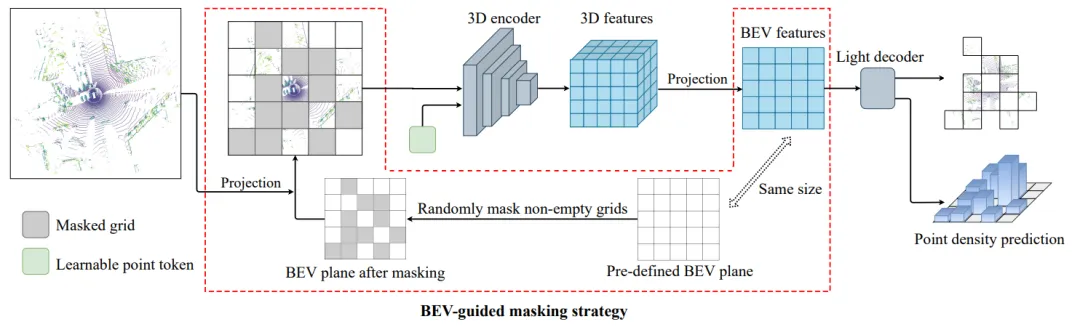
BEV-MAE first applies a BEV-guided masking strategy to the input 3D point cloud. Masked points are replaced by a shared learnable token. The processed point cloud is fed to a 3D encoder followed by a lightweight decoder. The decoder reconstructs the masked points and predicts point density for masked regions.
a. BEV-guided masking strategy
In LiDAR-based 3D detection, point clouds are commonly partitioned into regular voxels. A simple masking strategy would mask voxel patches similar to image patch masking. However, such voxel masking does not explicitly align with BEV feature representations commonly used in 3D detectors.
To address this, the authors propose a BEV-guided masking scheme that masks points based on their positions on the BEV plane.
Concretely, suppose the encoded BEV feature resolution is 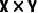 . A grid of size is predefined on the BEV plane. Points are projected into the corresponding BEV grid cells according to their coordinates. A subset of non-empty BEV cells is randomly selected as masked cells, and the remaining cells are treated as visible. All points projecting into visible cells form the masked-input point cloud fed to the network.
. A grid of size is predefined on the BEV plane. Points are projected into the corresponding BEV grid cells according to their coordinates. A subset of non-empty BEV cells is randomly selected as masked cells, and the remaining cells are treated as visible. All points projecting into visible cells form the masked-input point cloud fed to the network.
b. Shared learnable token
Typical voxel-based 3D encoders use multiple sparse convolution operations that only process features near non-empty voxels. Masking out points reduces the receptive field of such encoders when masked point clouds are used as input. To mitigate this, the authors replace masked points with a shared learnable token. Specifically, the full set of point coordinates is used as the sparse convolution input index, while features for masked points are replaced by a shared learnable token in the first sparse convolution layer. Subsequent sparse convolution layers remain unchanged. The shared token only serves to propagate information across voxels to preserve the encoder receptive field size; it does not add any extra information (for example, masked-point coordinates are not exposed) so as to avoid making the reconstruction task easier.
c. Mask prediction tasks
BEV-MAE uses two supervised tasks during pretraining: point cloud reconstruction and density prediction. Each task uses an independent linear head for prediction.
For point reconstruction, BEV-MAE predicts coordinates of the masked points and uses the chamfer distance as the training loss, similar to prior work.
For density prediction, outdoor LiDAR point clouds in driving scenes exhibit sparsity that increases with distance from the sensor. Density therefore reflects positional information for points or objects, which is important for detection localization. The density prediction task helps the 3D encoder learn better localization ability.
Concretely, for each masked BEV cell, the ground-truth density is computed by counting points in the cell and dividing by the cell's occupied 3D volume. BEV-MAE predicts density using a linear head and supervises this task with Smooth-L1 loss.
Experiments
BEV-MAE is evaluated on two mainstream autonomous driving datasets: nuScenes and Waymo.
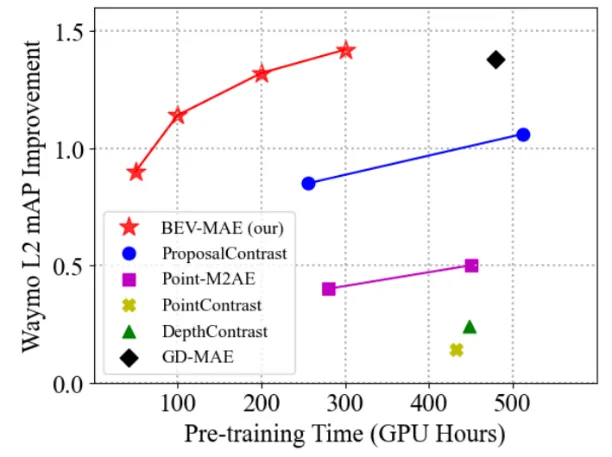
On Waymo, BEV-MAE achieves larger 3D detection performance improvements with lower pretraining cost, as shown below:
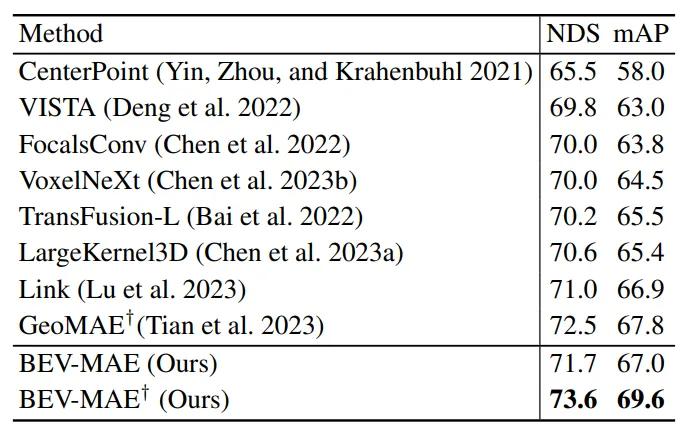
On nuScenes, using BEV-MAE for pretraining further improves the performance of strong point-cloud-only 3D detectors. With TransFusion-L as the base 3D detector and BEV-MAE pretraining, the approach achieves advanced single-modality LiDAR 3D detection results on nuScenes.
Conclusion
This work proposes BEV-MAE, a masked-model pretraining strategy for LiDAR perception. The method is effective in improving pretraining efficiency and downstream detection performance, reducing the need for labeled LiDAR data.