ALLPCB
ALLPCB


Abstract
Most NeRF research focuses on novel view synthesis for images, while LiDAR has been less explored. Dynamic scenes that require synthesis across new spatial and temporal viewpoints pose significant challenges due to LiDAR point clouds' sparsity, discontinuity, and occlusion. Large motions of dynamic objects further complicate alignment and reconstruction. Traditional LiDAR-based 3D reconstruction aggregates multiple sparse point-cloud frames in world coordinates and converts them to explicit surface representations such as triangle meshes. New-view LiDAR is then rendered by ray-mesh intersection. For large-scale complex scenes, high-quality surface reconstruction is difficult and can introduce geometric errors. Explicit reconstruction methods are also limited to static scenes and do not accurately model LiDAR intensity or ray drop characteristics.
Image+LiDAR methods such as NeRF-LiDAR integrate image and point-cloud modalities for LiDAR synthesis, while LiDAR-only approaches like LiDAR-NeRF and NFL explore reconstruction and generation without RGB input. Many prior methods directly apply image NVS pipelines to LiDAR point clouds, but the fundamental differences between LiDAR and 2D images create challenges for high-quality LiDAR NVS:
- Prior methods assume static scenes and ignore dynamics common in autonomous driving;
- The large scale and high sparsity of LiDAR point clouds demand more expressive representations;
- Modeling intensity and ray drop characteristics is necessary for realistic synthesis.
To address these limitations, this work proposes LiDAR4D and identifies three key insights for improving LiDAR NVS. To handle dynamic objects, geometric constraints derived from point clouds are introduced and multi-frame dynamic features are aggregated for temporal consistency. For compact large-scale reconstruction, a coarse-to-fine hybrid representation combines multi-plane and grid features to reconstruct smooth geometry and high-frequency intensity. Global optimization is used to preserve cross-region patterns when refining ray drop probability. LiDAR4D therefore enables geometry-aware, temporally consistent reconstruction in large-scale dynamic scenes.
Qualitative Results
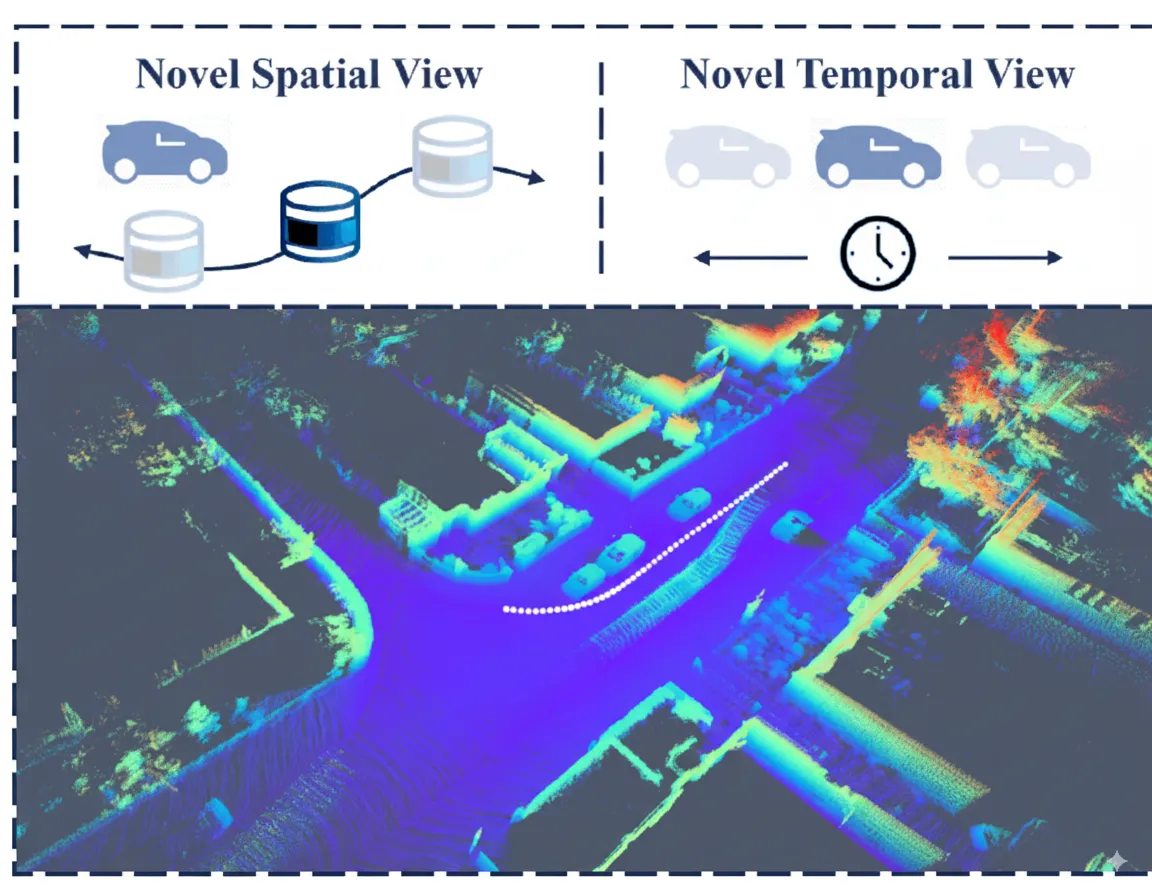
Dynamic scenes of LiDAR point clouds in autonomous driving. Large-scale vehicle motion poses major challenges for dynamic reconstruction and space-time view synthesis. White points indicate the ego-vehicle trajectory.
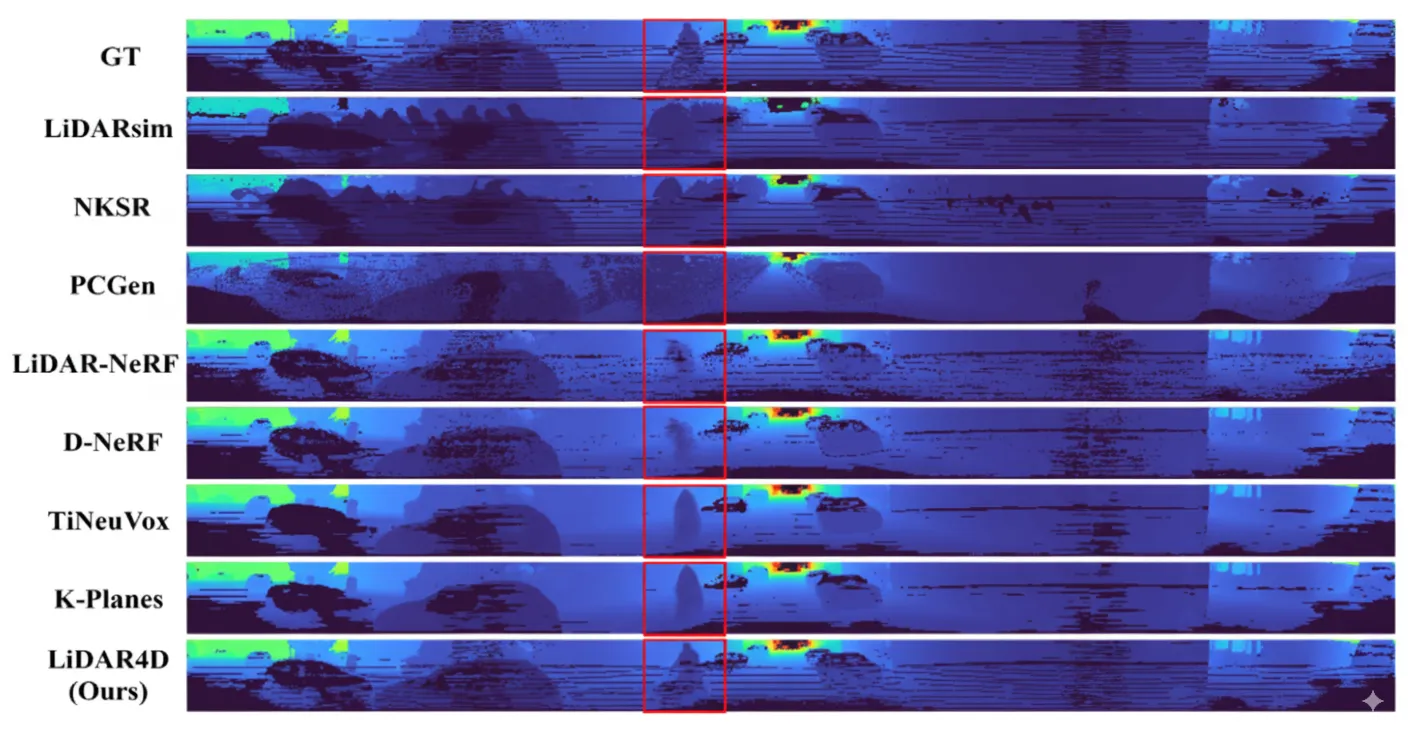
Qualitative novel-view LiDAR synthesis on KITTI-360. LiDAR-NeRF fails to reconstruct dynamic vehicles. By contrast, LiDAR4D generates more accurate geometry for moving cars, even at larger distances in sparse point clouds.

Qualitative comparison of LiDAR depth reconstruction and synthesis.
Key Contributions
- LiDAR4D: a differentiable LiDAR-only framework for novel space-time view synthesis that reconstructs dynamic driving scenes and generates realistic LiDAR point clouds end to end.
- A 4D hybrid neural representation and motion priors derived from point clouds to enable geometry-aware, temporally consistent large-scale reconstruction.
- Comprehensive experiments demonstrating state-of-the-art performance on challenging dynamic scene reconstruction and novel-view synthesis tasks.
Method Overview
For large-scale autonomous driving scenes, LiDAR4D uses a 4D hybrid representation that fuses low-resolution multi-plane features with high-resolution hash grid features in a coarse-to-fine manner for efficient reconstruction. Multi-level spatio-temporal features aggregated by a flow MLP are fed into a neural LiDAR field to predict density, intensity, and ray drop probability. Differentiable rendering is then used to synthesize novel space-time LiDAR views. Geometric constraints derived from point clouds enforce temporal consistency, and a global optimization refines ray drop probabilities to produce realistic outputs.
Experiments
The authors evaluate LiDAR4D on diverse dynamic scenes from KITTI-360 and NuScenes. LiDAR4D outperforms prior NeRF-based implicit methods and explicit reconstruction baselines. Compared to LiDAR-NeRF, LiDAR4D achieves CD error reductions of 24.3% on KITTI-360 and 24.2% on NuScenes. Similar improvements are observed on other depth and intensity metrics.
Limitations and Conclusion
Despite strong empirical results, challenges remain for distant vehicle motion and occlusions in point clouds. Reconstruction of dynamic objects still lags behind that of static objects, and separating foreground from background can be difficult. Quantitative NVS evaluation on real-world datasets is limited to ego-vehicle trajectories, which constrains decoupling of novel spatial and temporal view synthesis.
Overall, this paper revisits limitations of existing LiDAR NVS methods and proposes a framework addressing dynamic reconstruction, large-scale scene representation, and realistic synthesis. LiDAR4D demonstrates geometry-aware, temporally consistent reconstruction of large-scale dynamic point-cloud scenes and produces novel space-time LiDAR views that better match the real distribution. The authors suggest further work on integrating LiDAR point clouds with neural radiance fields and exploring additional approaches to dynamic scene reconstruction and synthesis.