ALLPCB
ALLPCB


Summary
This article summarizes RCBEVDet, a 3D object detection architecture developed by a team at the Wang Xuan Institute of Computer Technology, Peking University, and collaborators. RCBEVDet fuses mmWave radar and surround-view camera bird's-eye view (BEV) features for autonomous driving perception. The design includes a radar-specific backbone (RadarBEVNet) for BEV feature extraction and a deformable cross-attention mechanism for robust fusion of radar and camera BEV features. The method improves 3D detection accuracy while maintaining real-time inference and shows robustness to modality signal loss and interference. The paper was accepted to CVPR 2024.
Paper overview
RCBEVDet is a 3D detection architecture that fuses mmWave radar and surround-view camera BEV features. It introduces RadarBEVNet, an efficient backbone tailored to mmWave radar for extracting BEV features from radar point clouds, and a deformable cross-attention module to fuse radar and camera BEV features robustly and efficiently. The architecture is compatible with mainstream surround-view camera 3D detectors and achieves a favorable speed-accuracy trade-off while improving multimodal robustness. Experiments on the nuScenes dataset demonstrate leading performance among radar-plus-multi-camera 3D detectors in both accuracy and inference efficiency.
Research background
Recent work has focused on using cost-effective multi-view cameras for 3D object detection in autonomous driving. Multi-view cameras capture color and texture and provide high-resolution semantic cues, but they alone struggle to provide accurate depth and are sensitive to weather and lighting. To improve safety and robustness, autonomous vehicles typically combine multiple sensor modalities such as surround-view cameras, lidar, and mmWave radar. mmWave radar is an economical sensor that offers reasonably accurate depth and velocity information and can produce reliable radar point clouds under various weather and lighting conditions. The radar-plus-camera multimodal configuration therefore provides a good balance of perception capability and cost. However, fusing 4D mmWave radar and multi-view camera data is challenging due to the large modality gap, and robust, high-precision multimodal fusion for tasks like 3D detection remains technically difficult.
Method
RCBEVDet fuses mmWave radar and multi-view camera BEV features for robust, high-accuracy 3D perception. The overall architecture is shown below:
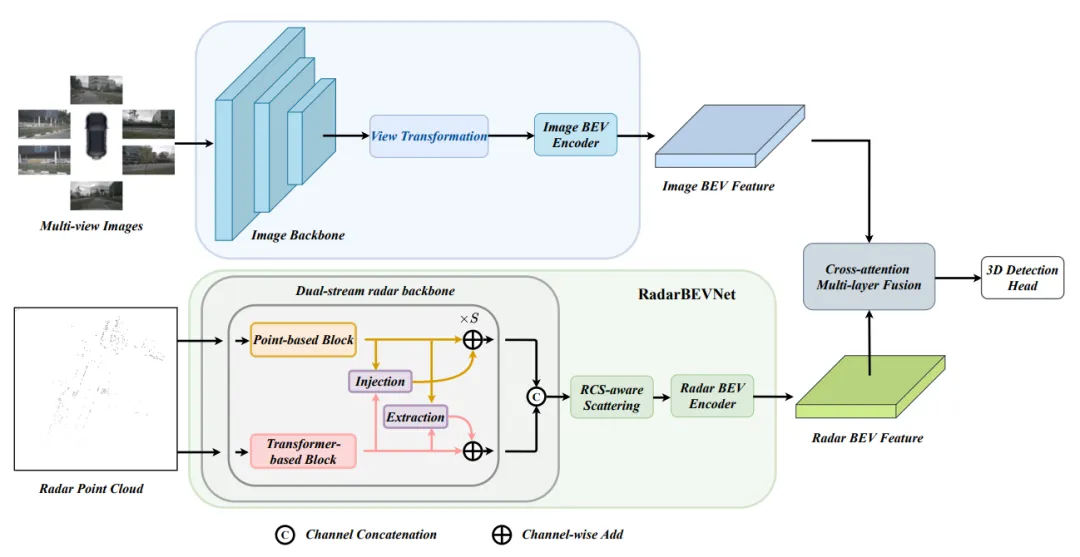
The design includes three key components: RadarBEVNet for radar BEV feature extraction, an RCS-guided voxelization strategy to densify radar features, and a deformable cross-attention fusion module to align and merge radar and camera BEV features.
1. RadarBEVNet
Given input mmWave radar point clouds, RadarBEVNet extracts features using two complementary representations: a point-based extractor for local point features and a transformer-based module for global point cloud context. These two representations interact via injection and extraction modules to produce comprehensive radar point cloud features that capture both local and global information.
2. RCS-guided voxelization
Radar cross section (RCS) is a radar-specific attribute that reflects an object's detectability; under similar conditions, larger objects tend to have stronger radar returns. RCBEVDet uses RCS as a prior for object size in a voxelization step, discretizing radar points into multiple voxel cells guided by RCS. This increases the effective density of radar features and simplifies subsequent feature aggregation.
3. Deformable cross-attention fusion module
Radar point clouds often deviate from true object locations. A deformable cross-attention mechanism is used to dynamically learn these position offsets, improving fusion robustness. The deformable formulation also reduces the computational cost compared with standard cross-attention, improving fusion efficiency.
Experiments
RCBEVDet was evaluated mainly on the nuScenes multimodal autonomous driving dataset. Using BEVDepth as the camera-only baseline, RCBEVDet achieves substantial and stable improvements in 3D detection performance with only modest additional inference latency, maintaining real-time operation and improving the overall speed-accuracy trade-off.
Conclusion
RCBEVDet presents a radar-and-surround-view-camera BEV fusion architecture for 3D object detection that improves accuracy and robustness while preserving real-time inference. Key contributions include a radar-tailored backbone (RadarBEVNet), RCS-guided voxelization to densify radar features, and a deformable cross-attention fusion module for efficient, robust multimodal alignment and fusion.