ALLPCB
ALLPCB


Overview
This article describes a method to recover full-body motion from sparse upper-body tracking signals (head and hands) provided by a VR headset and controllers. Most standalone VR headset avatar systems lack lower-body tracking because head and hand tracking alone do not provide reliable cues for legs, feet, or pelvis position. As a result, many consumer avatars omit the lower half of the body.
The industry has explored various solutions. For example, prior research proposed a headset-only full-body avatar approach using AI without optical markers. In another paper, researchers from Meta present AGRoL, a conditional diffusion model that generates smooth full-body motion from sparse upper-body tracking signals (head and dual-hand controllers). The model uses a compact MLP architecture and a novel motion data modulation scheme to accurately and smoothly predict whole-body motion, including challenging lower-body motion.
Full-body tracking is important for AR/VR applications because humans are the primary agents in those environments. While typical systems can accurately track the upper body, full-body tracking enables more immersive experiences by reconstructing leg and pelvis motion from limited signals. In typical AR/VR setups, only the head and hands are tracked via inertial measurement units embedded in the headset and controllers. The ideal goal is to recover high-fidelity full-body motion using the standard three inputs provided by most headsets: head and two hands.
Predicting full-body pose, especially the lower body, from head and hand positions and orientations is inherently underconstrained. To address this, many methods use generative models. Diffusion models have shown strong results for conditional generation in image and video domains, motivating the use of diffusion for motion synthesis from sparse tracking signals. However, applying diffusion models to motion synthesis is challenging due to differences in data representation between skeleton joint features and images.
In "Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model," the authors introduce Avatars Grow Legs (AGRoL), a diffusion architecture specifically designed for conditional motion synthesis. The approach is built on a compact MLP architecture. Although a well-designed MLP can match state-of-the-art performance, its predictions can contain jitter artifacts.
To generate smooth, realistic full-body motion from sparse tracking signals, the researchers designed a lightweight diffusion model powered by the MLP backbone. They observed that the MLP was relatively insensitive to conventional time-step embeddings used in diffusion models, which hindered denoising and produced jitter. To address this, they propose a new strategy that injects time-step embeddings repeatedly before each MLP block during the diffusion process. This approach substantially reduces jitter and improves robustness to missing tracking signals. Experiments on the AMASS dataset show that AGRoL outperforms existing methods in full-body motion prediction.
Problem Formulation
The task is to predict full-body motion given sparse tracking signals, i.e., the orientation and translation of the headset and two hand controllers. Given N observed joint feature sequences:
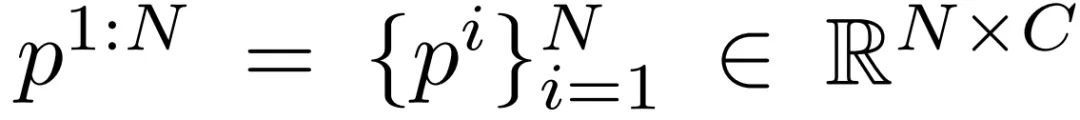
The goal is to predict N frames of full-body pose:
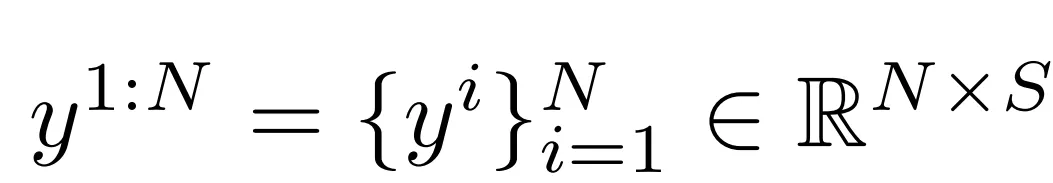
Here C and S denote the input and output joint feature dimensions respectively. The authors use the SMPL body model to represent human pose, retaining only the first 22 SMPL joints and ignoring hand articulations. y1:N denotes the global orientation of the pelvis and the relative rotations of each joint for N frames.
MLP-Based Network
The network consists of four commonly used deep learning components: fully connected layers, SiLU activations, 1D convolutional layers with kernel size 1, and layer normalization. Note that a 1D convolution with kernel size 1 can be viewed as a fully connected operation across a specific dimension. The architecture details are shown in the diagram below.
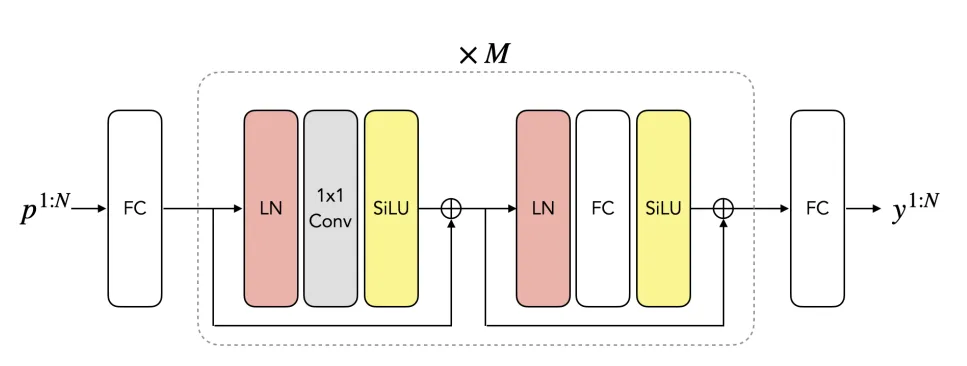
Each MLP block contains a convolutional layer and a fully connected layer responsible for fusing temporal and spatial information respectively. The authors use skip connections with pre-layer normalization. Inputs p1:N are first projected into a higher-dimensional latent space via a linear layer. The final layer projects from latent space to the full-body output space at the scale of y1:N.
Diffusion Model and Time-Step Injection
Diffusion models learn to reverse Gaussian noise added by a Markov chain to recover data samples from noise. Time-step t embeddings are typically provided to the network as additional inputs. A common approach is to concatenate the time embedding with the input, similar to positional embeddings used in transformer-based methods. However, because the backbone is an MLP, the authors found the model to be insensitive to conventional time-step embeddings, which hindered learning the denoising process and led to severe jitter in predicted motion.
To address this, the authors propose a strategy that repeatedly injects time-step embeddings before each MLP block. The pipeline is illustrated below.
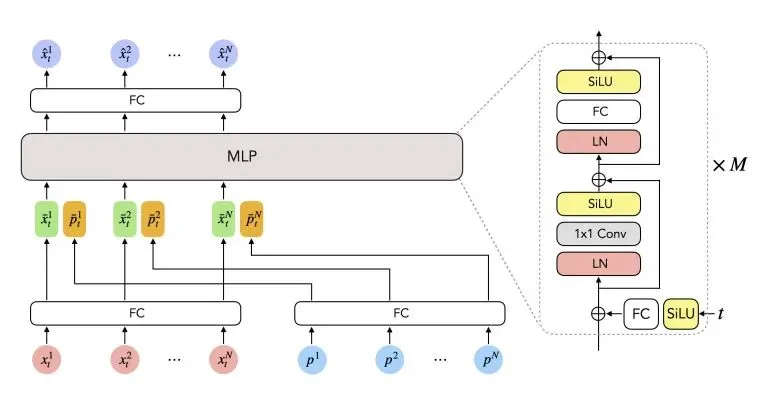
Time embeddings are projected through a fully connected layer and a SiLU activation to match the input feature dimension. For each block, the model predicts scale and shift factors for the time embedding, and the resulting features are added to the intermediate activations. This repeated injection largely mitigates jitter and enables synthesis of smooth motions.
Training and Evaluation
The authors train and evaluate their model on the AMASS motion capture dataset using the SMPL human model as pose representation. The model predicts the global orientation of the root joint and relative rotations of the other joints.

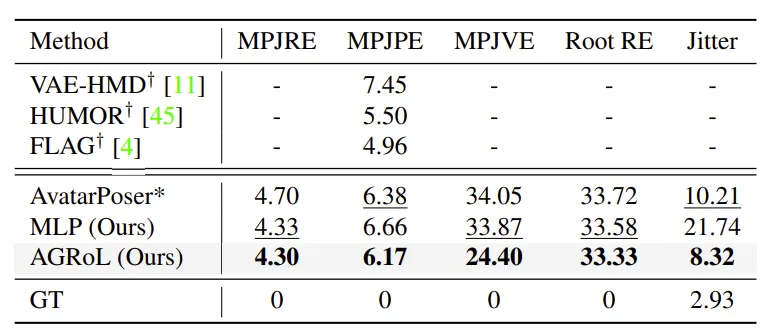
The MLP backbone alone can surpass most previous approaches and achieves results comparable to state-of-the-art methods, demonstrating its effectiveness. With the diffusion process, AGRoL further improves MLP performance and outperforms prior methods. AGRoL also significantly reduces jitter error, producing smoother generated motions compared to alternatives.
Qualitative Results

The figure above shows a qualitative comparison on AMASS test sequences between AGRoL (bottom) and AvatarPoser (top). Visualizations include predicted skeletons and body meshes. Green skeletons show AGRoL predictions, red skeletons show AvatarPoser predictions, and blue skeletons show ground truth. AGRoL predictions align more closely with ground truth than AvatarPoser in these examples.
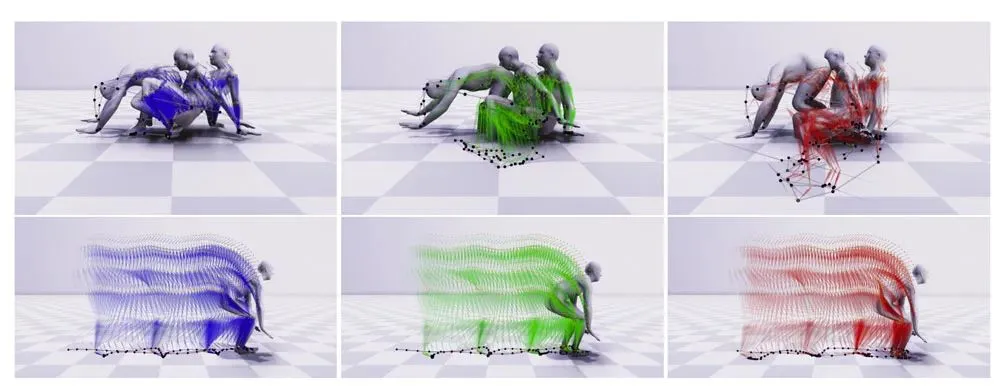
The motion trajectory visualization shows ground truth motion (blue skeleton), AGRoL prediction (green skeleton), and AvatarPoser prediction (red skeleton). Light purple vectors indicate joint velocity vectors. Visualizing trajectories helps assess jitter and foot sliding issues. Smooth motion exhibits regular pose trajectories and stable changes in joint velocity vectors. Trajectory density varies with walking speed and becomes denser when the subject slows down.
Conclusion
AGRoL is a conditional diffusion model tailored for full-body motion synthesis from sparse IMU tracking signals. It is a compact and efficient MLP diffusion model. To achieve progressive denoising and smooth motion sequences, the authors introduce a per-block time-step injection scheme that adds diffusion time embeddings before each intermediate network block. This strategy enables AGRoL to reach state-of-the-art performance on full-body motion synthesis without requiring additional auxiliary losses used by other methods.
Experiments demonstrate that the lightweight diffusion model AGRoL can generate realistic, smooth motion while supporting real-time inference speeds suitable for online applications. Compared with existing methods, AGRoL is more robust to missing tracking signals.
Reference
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model