ALLPCB
ALLPCB


Introduction
In a multitasking environment, embedded systems typically run more tasks than there are processors. This requires the operating system to dynamically assign processors to ready tasks according to some algorithm. Processor scheduling is essentially allocation of processor resources. The scheduling algorithm directly affects system runtime behavior, such as responsiveness, throughput, and resource utilization, and is an essential part of the operating system.
The introduction of multicore processors enables tasks on embedded platforms to execute in parallel on different cores, increasing computational capacity while introducing new scheduling challenges. In a single-core system the scheduler needs only to scan the ready list and select the highest-priority task. In a multicore system, the scheduler must also decide which CPU core will run each task. This article proposes a core-set based multicore scheduling method built on a semipartitioned real-time OS scheduler. The method preserves the original OS scheduling mechanism while allowing tasks to run on a specified subset of cores (a core set). Compared with a policy where a task is bound to a single core or allowed on all cores, the core-set approach lets tasks run on a local set of cores and can mitigate load imbalance inherent in semipartitioned scheduling.
1 Multicore Embedded Real-Time Scheduling
Multiprocessor scheduling is commonly classified into global scheduling and partitioned scheduling. Global scheduling allows tasks to migrate freely among cores; partitioned scheduling binds each task to a fixed core. Global scheduling can improve processor utilization but incurs additional system overhead. Partitioned scheduling has lower migration cost and higher cache hit rates because tasks remain on a fixed core, but it can waste processor capacity when some cores are idle. To balance these trade-offs, semipartitioned scheduling combines features of both approaches: some tasks are partitioned to specific cores while others are scheduled globally. This hybrid strategy can improve load balance and better utilize idle processors.
1.1 Global scheduling
In global scheduling, tasks may run on any core. The OS dynamically assigns ready tasks to available cores based on priority and core availability. Global scheduling is often implemented with a single global ready queue that holds all ready tasks; when a core becomes idle, the scheduler selects the highest-priority task from the global ready queue.
Under multicore global scheduling, per-core execution order changes from the single-core serial sequence to parallel execution. Lower-priority tasks can run concurrently with higher-priority tasks on different cores. Figure 1 illustrates global scheduling on a four-core system: tasks 1, 2, and 3, though of different priorities, can run simultaneously on different cores; when core 3 becomes idle, the scheduler dispatches a lower-priority task onto it. For independent tasks, global scheduling makes effective use of idle cores and can automatically balance load across the system.
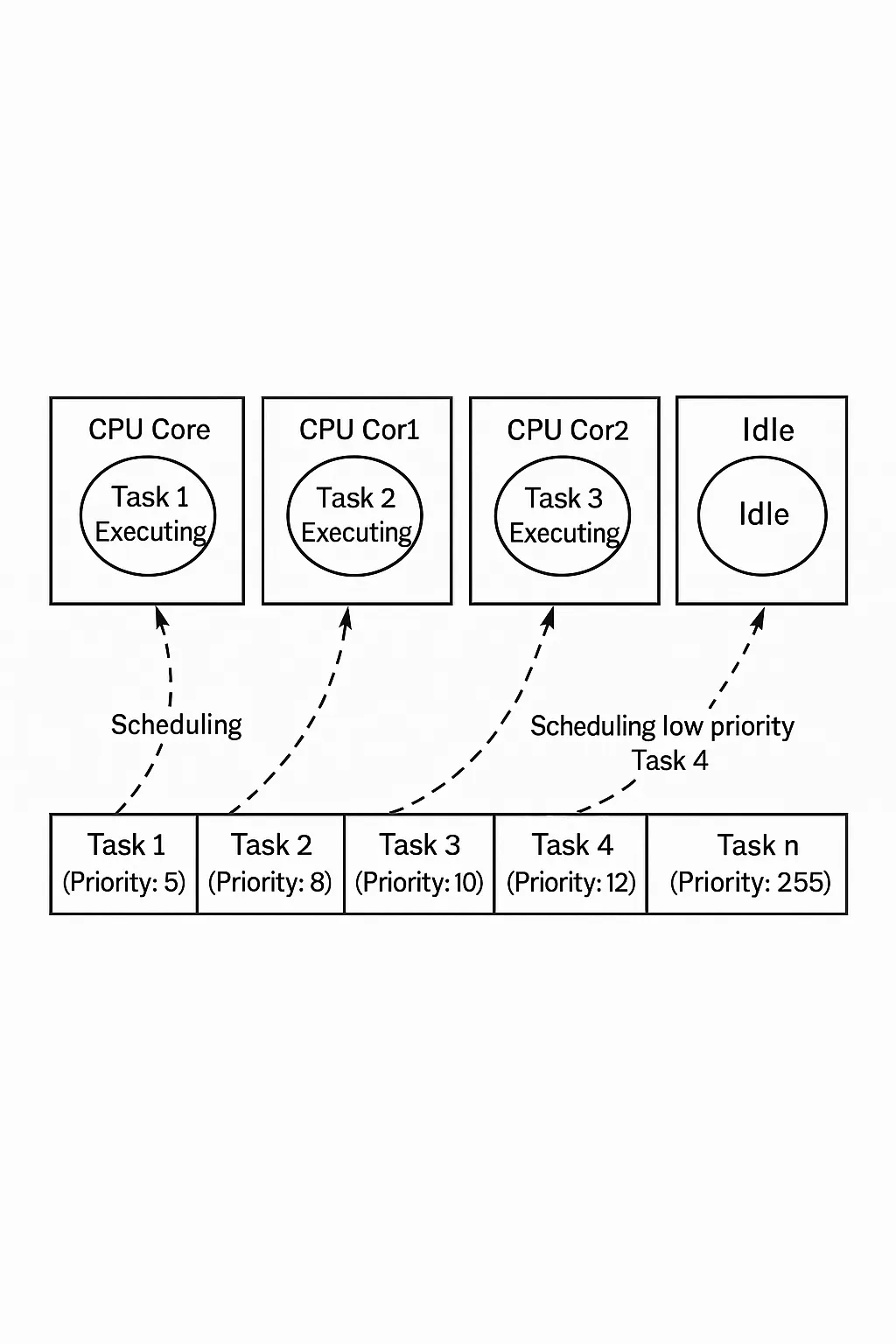
Figure 1: Multicore global scheduling
However, multicore global scheduling has unavoidable drawbacks:
- No fixed execution order: Parallel execution changes the original sequential relations among tasks, requiring careful orchestration of scheduling to preserve timing or logical constraints.
- Lower cache hit rate: Each core has its own cache storing task data; migrating a task to another core reduces cache locality and can significantly degrade performance.
- Contention on the global ready list: The single global ready list is shared across cores. Only one core can access it at a time, and contention increases with core count, raising context-switching overhead.
1.2 Partitioned scheduling
To address the above issues, some multicore embedded real-time OSes use partitioned scheduling. Each task is bound to a specific core (affinity), and tasks only run on their assigned cores. The system maintains a separate ready queue per core; the core schedules tasks only from its private queue. Figure 2 shows the partitioned scheduling idea: each core has a private ready queue containing tasks with affinity to that core.
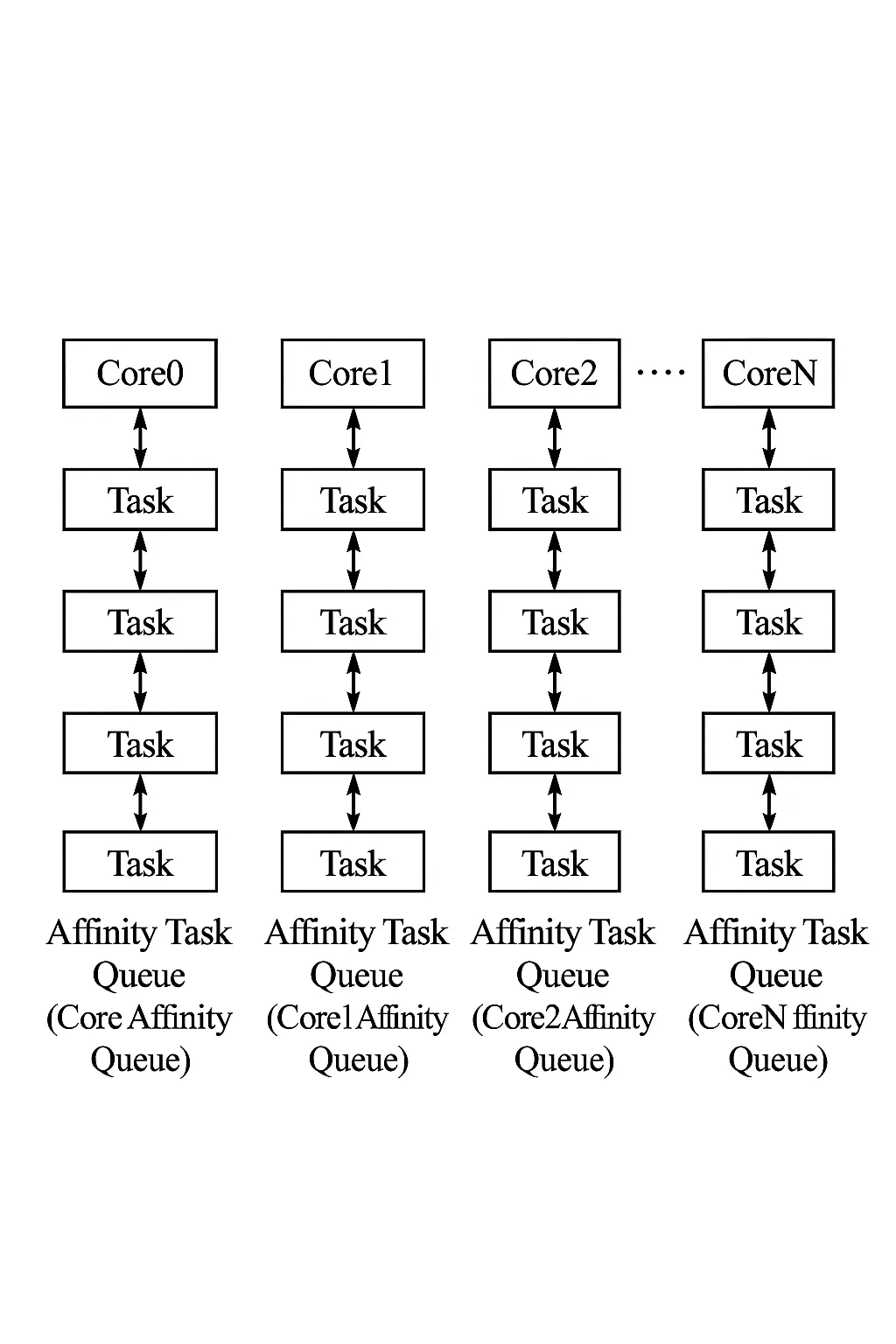
Figure 2: Partitioned scheduling
Partitioned scheduling improves determinism compared with global scheduling and reduces scheduling cost since tasks do not migrate across cores. Cache hit rates remain similar to single-core operation. Main drawbacks compared with global scheduling are:
- Increased inter-core communication: When tasks bound to different cores interact frequently, cross-core communication and interrupts can become frequent, impacting task execution.
- Lower overall processor utilization: Binding tasks to fixed cores can leave some cores idle while others are busy, reducing overall utilization.
1.3 Semipartitioned scheduling
Semipartitioned scheduling combines global and partitioned approaches. Most tasks are pre-assigned to specific cores using partitioned scheduling, while a subset of tasks is scheduled globally across cores. Semipartitioned scheduling uses N+1 ready queues for an N-core system: one global ready queue plus one per-core ready queue. The scheduler is preemptive and priority-based; a core selects the highest-priority task among its private ready queue and the global ready queue. This approach helps utilize idle cores and improve load balance, partially addressing the limitations of purely global or partitioned schemes.
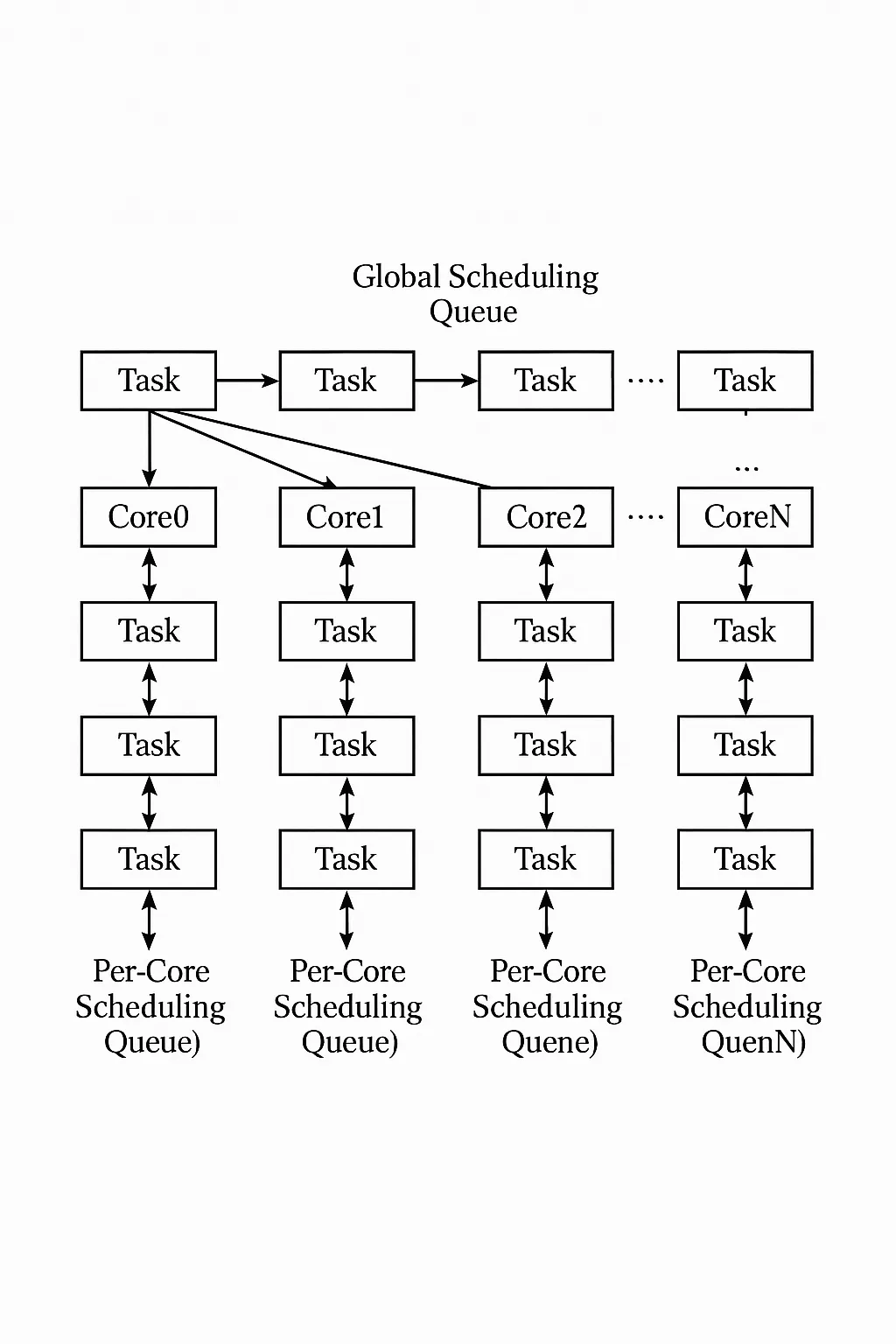
Figure 3: Semipartitioned scheduling
2 Core-set Based Multicore Real-Time Scheduling
Although semipartitioned scheduling reduces cross-core migration while leveraging idle cores, it can still suffer load imbalance. For example, in aerospace and other domains with strong determinism requirements, most tasks may be bound to specific cores, which can lead to uneven task distributions and underutilized cores. Moreover, when many tasks reside in the global ready list, cache locality can degrade and system performance can suffer.
This article extends semipartitioned scheduling by adding a core-set attribute to tasks. A core set is a subset of cores on which a task is allowed to run. When configuring a task, if an affinity (specific core) is set, it must be one of the cores in the task's core set. If no affinity is set, the task is eligible for global scheduling, but the global scheduling is limited to the task's core set, effectively a local-global scheduling. If no core set is specified, the default core set is all cores.
Figure 4 illustrates semipartitioned scheduling with core sets. If task A has core set [0,1], then its affinity can only be core 0 or 1; if no affinity is specified, the task is globally scheduled but only within [0,1] rather than across all cores [0,1,2,3,...,N].
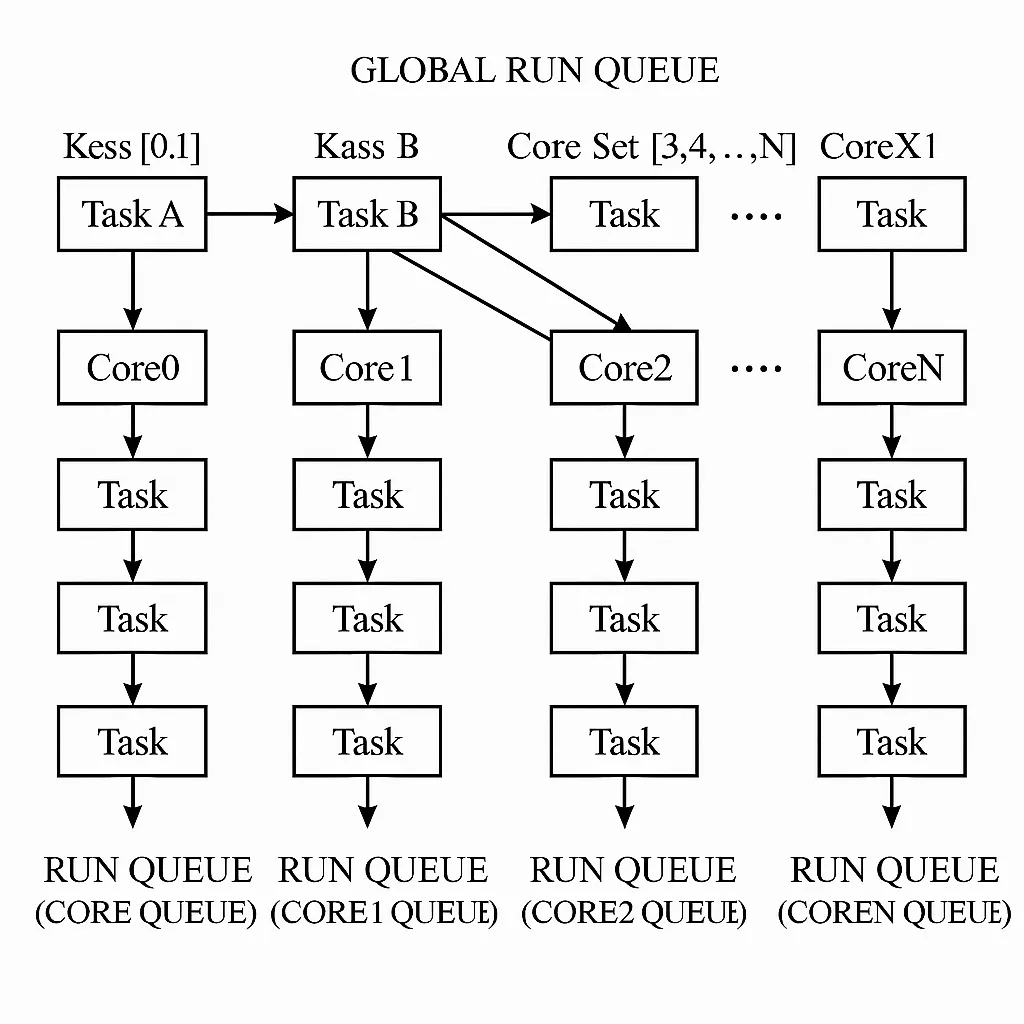
Figure 4: Core-set semipartitioned scheduling
When a core selects its next task, an additional filtering layer is applied to the global ready queue: tasks whose core set contains the current core are extracted into a separate list. The scheduler then finds the highest-priority task in this filtered list and compares it with the highest-priority task in the core's affinity queue; the higher-priority task is dispatched to the core. The core selection process is shown in Figure 5. For example, if core 2 is idle or needs rescheduling, the scheduler scans the global ready queue by priority: task A's core set does not include core 2 and is skipped; task B's core set includes core 2 and is added to the filtered list; scanning continues until the highest-priority eligible task is found. Then the highest-priority task from the filtered list is compared with the core 2 affinity queue's highest-priority task, and the one with higher priority is selected to run on core 2.
3 Core-set Based Scheduling Flow
The scheduling flow for the core-set based method is shown in Figure 6.
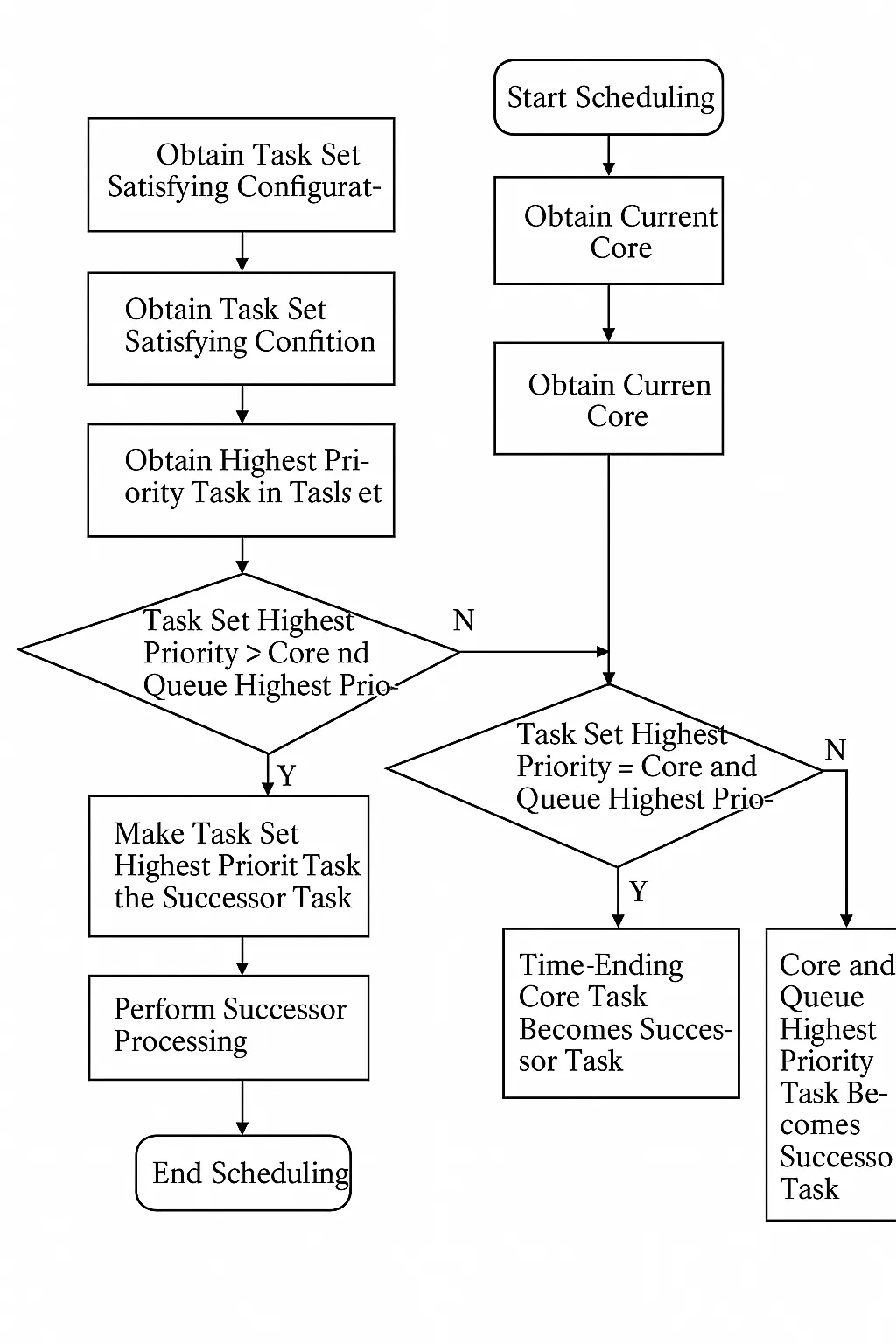
Figure 6: Flowchart of core-set based scheduling
Step 1: Scheduling is triggered by events such as end of interrupt service routines, tasks blocking while waiting for resources, or a higher-priority task becoming ready.
Step 2: Obtain the current core ID to access that core's affinity queue and to filter tasks that satisfy the core-set requirement.
Step 3: Traverse the core affinity ready queue to find the highest-priority task, PrivateHighestTask.
Step 4: Traverse the global ready queue and filter tasks whose core set includes the current core to form a candidate set.
Step 5: From the candidate set obtained in Step 4, select the highest-priority task, GlobalHighestTask.
Step 6: Compare priorities. If PrivateHighestTask has higher priority than GlobalHighestTask, proceed to Step 7; otherwise, go to Step 8.
Step 7: Set PrivateHighestTask as the successor task for the core and proceed to Step 11.
Step 8: If PrivateHighestTask and GlobalHighestTask have equal priority, proceed to Step 9; otherwise go to Step 10.
Step 9: Choose the one with the earlier ready time between PrivateHighestTask and GlobalHighestTask as the successor task, then proceed to Step 11.
Step 10: Set GlobalHighestTask as the successor task for the core and proceed to Step 11.
Step 11: The chosen successor task runs on the core.
Step 12: The scheduling instance completes and awaits the next scheduling trigger, returning to Step 1.
Conclusion
Semipartitioned scheduling uses a global run queue to improve load balance and increase processor utilization compared with purely partitioned scheduling. This article proposes a core-set enhancement to semipartitioned scheduling to address load imbalance. The core-set method restricts global scheduling to task-specific subsets of cores, improving locality and reducing contention while preserving the original scheduling behavior. The approach aims to maintain real-time properties and can support future multicore container configurations. Development and testing have been completed on FT1500-A; tasks run normally and core-set attributes are configurable so tasks run only within their specified core sets. The next step is experimental validation to compare this method's load balancing against standard semipartitioned scheduling.