 ALLPCB
ALLPCB


Overview
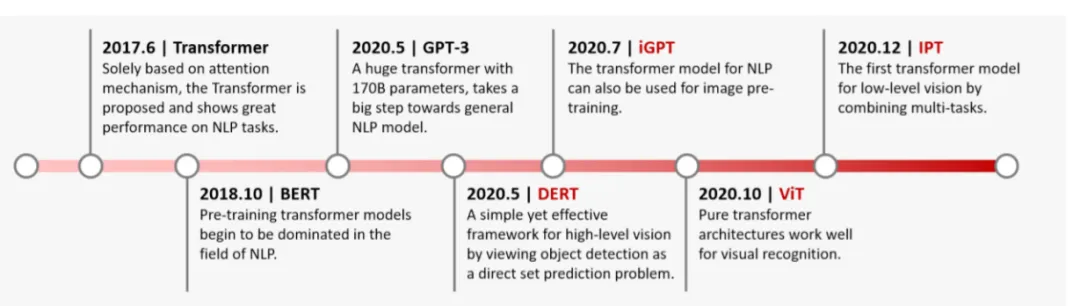
Transformer is a class of deep neural networks based on self-attention, originally developed for natural language understanding. Compared with convolutional and recurrent networks, Transformer has stronger representation learning capability and has been applied to visual tasks. Vision Transformer based representation learning networks have achieved strong results in image classification, video understanding, and other low- and high-level vision tasks. This article briefly introduces the basic principles of vision Transformers and Transformer structures used for object detection.
Vision Transformer architecture
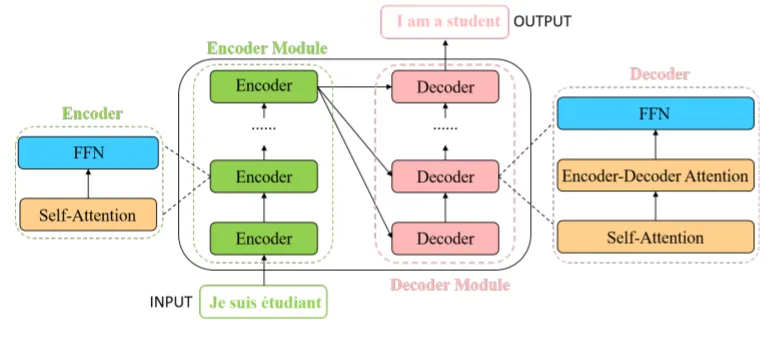
The general structure of a vision Transformer includes encoder and decoder parts. Each encoder layer contains a multi-head self-attention module and a position-wise feed-forward network (FFN). Each decoder layer contains three parts: multi-head self-attention, encoder-decoder cross-attention, and a position-wise feed-forward network.
Applications in object detection
Transformers have been widely used for object detection. Based on network structure, these approaches can be grouped into three categories: multi-scale fusion (neck-based), head-based, and framework-based methods.
1) Multi-scale fusion
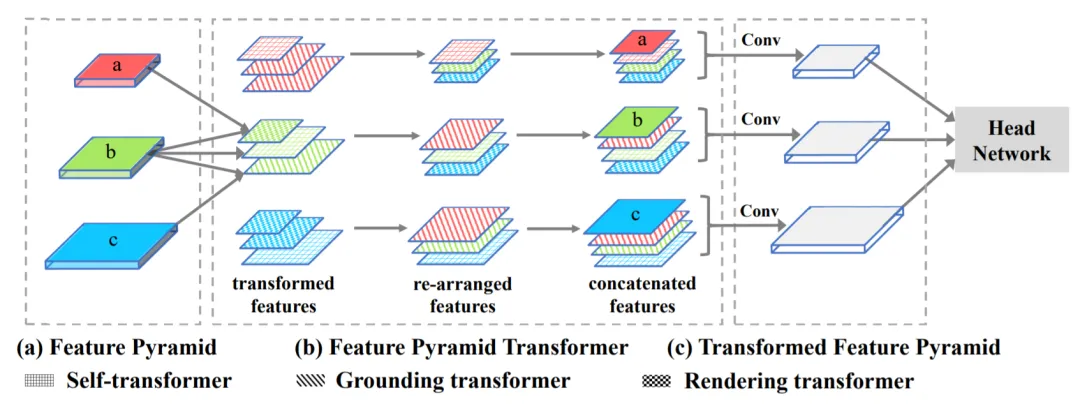
Inspired by multi-scale feature fusion networks such as feature pyramid networks used with convolutional backbones, researchers proposed the feature pyramid Transformer (FPT) to exploit cross-space and cross-scale feature interactions. FPT addresses the inability of convolutional networks to learn cross-scale feature interactions. The FPT network consists of three Transformer types called Self-Transformer, Grounding-Transformer, and Rendering-Transformer, which encode information for the feature pyramid's self-level, top-down, and bottom-up paths respectively, using self-attention to enhance feature fusion.
2) Head-based
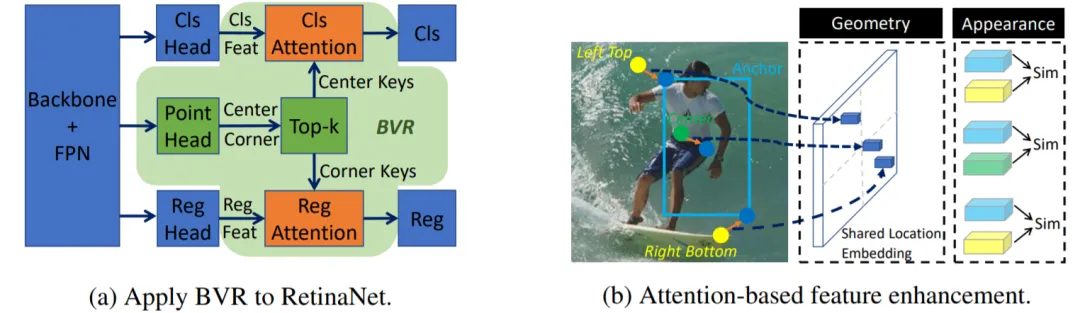
For object detection algorithms, the design of the prediction head is critical. Traditional detectors typically use a single visual representation such as bounding boxes or corners to predict final results. Introducing Transformer structure into detection, Bridging Visual Representations (BVR) combines heterogeneous representations into a single representation via multi-head attention. Concretely, the primary representation is used as the query while auxiliary representations serve as keys. Using attention, the primary representation is enhanced with information bridged from the auxiliary representations, which benefits final detection performance.
3) Framework-based
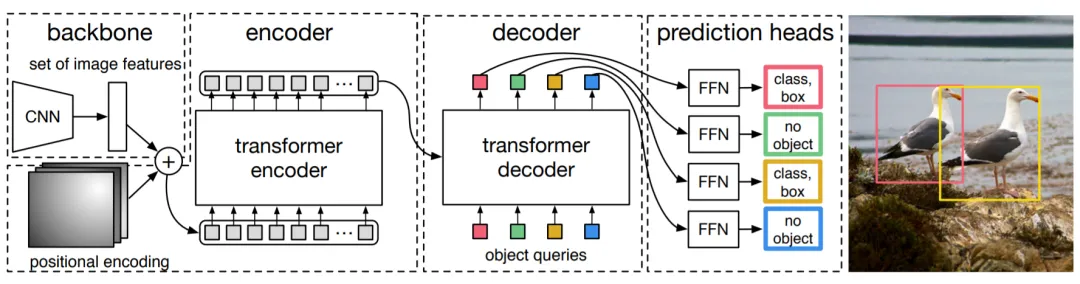
Unlike the previous two approaches that use Transformer modules to enhance specific parts of traditional detectors, DETR treats object detection as a set prediction problem and builds an end-to-end detector using an encoder-decoder Transformer. DETR starts from a CNN backbone to extract features from the input image. To supplement features with positional information, fixed positional encodings are added to flattened features before feeding them into the encoder-decoder transformer. Unlike the original Transformer that generates predictions sequentially, DETR decodes multiple objects simultaneously. DETR introduced a new Transformer design for detection, inspiring subsequent research, but it has drawbacks such as long training time and difficulty detecting small objects accurately.
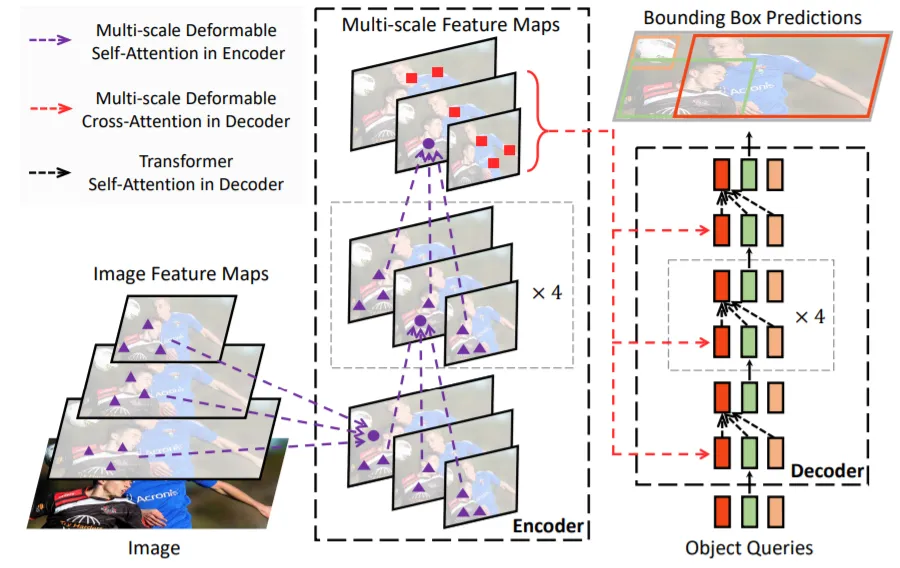
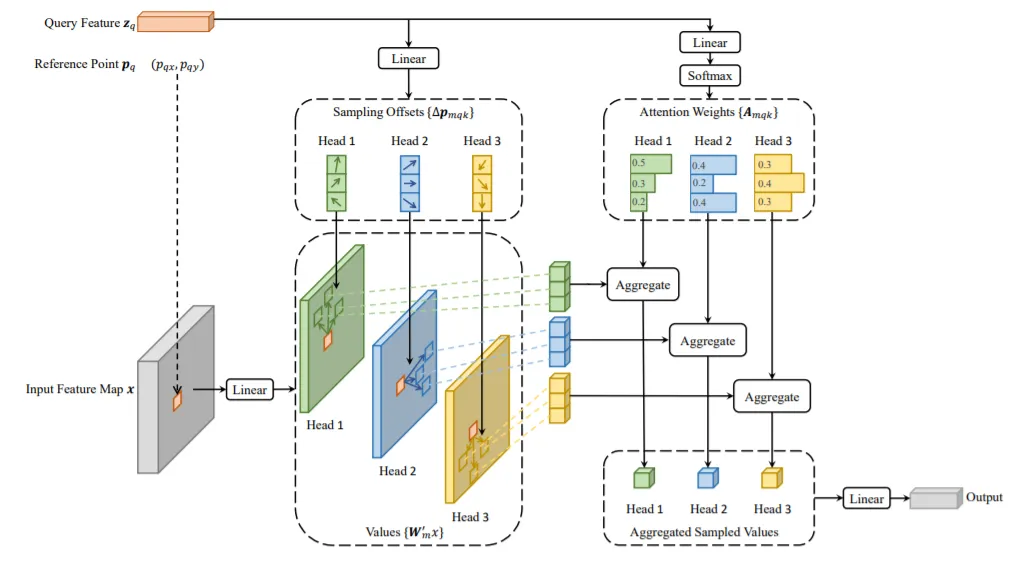
To address DETR's limitations, Deformable DETR uses a deformable attention module that attends to a small set of key sampling locations around reference points, significantly reducing the computational cost of standard multi-head attention and enabling faster convergence. The deformable attention module also facilitates multi-scale feature fusion, making Deformable DETR about 10 times cheaper to train and 1.6 times faster at inference compared with the original DETR.
Summary
Compared with convolutional networks, Transformers have advantages in capturing spatial and temporal relationships, and have become a prominent topic in computer vision research, achieving strong results across multiple visual tasks. Current vision Transformer research mainly focuses on single tasks, while in natural language processing Transformers have demonstrated the ability to perform multiple tasks within a unified model. Multi-task vision Transformer models merit further study. In addition, existing models are generally complex and have high training and storage costs. Developing vision Transformer models suitable for deployment on resource-constrained devices will be an important direction for future research.





