 ALLPCB
ALLPCB



Summary
Large language models (LLMs) demonstrate strong text understanding and generation capabilities. However, they can learn incorrect facts from training corpora and retain knowledge that becomes outdated. Directly fine-tuning on data that contains updated facts can be ineffective due to conflicts between old and new knowledge. This article summarizes a parameter-based fine-tuning paradigm called F-Learning (forgetting before learning), which first erases targeted old knowledge and then injects new knowledge. Experiments on two public datasets show that F-Learning improves knowledge-update performance for both full-model fine-tuning and parameter-efficient fine-tuning (LoRA). The study also finds that subtracting LoRA parameters to forget old knowledge can approximate or even exceed subtracting full-model parameter deltas while costing less compute.
Paper and Link
Paper: Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models
Link: https://arxiv.org/pdf/2311.08011.pdf
Background
LLMs have strong natural language understanding and generation abilities. Despite their learning capacity, they may store incorrect facts from training data, and many real-world facts change over time. For example, the answer to "Who is the US president?" differs between 2020 and 2024. Therefore, LLMs require mechanisms to update or correct outdated or erroneous knowledge during use. Existing model-editing and knowledge-update methods often add extra parameters, external memory, or knowledge bases, and the editing process can be more complex than direct fine-tuning on updated data.
Direct fine-tuning remains the most common approach to inject new facts. Drawing on human learning intuition: when new information conflicts with established beliefs, learning can be difficult unless the original incorrect belief is forgotten. Analogously, removing the model's representation of the old knowledge before fine-tuning on new data could reduce interference and simplify learning.
Motivated by this, F-Learning is proposed. The process first fine-tunes the base model on the old knowledge, computes the parameter delta that encodes that knowledge, subtracts a scaled version of that delta from the base model to "forget" the old knowledge, and then fine-tunes the resulting model on the new knowledge.
Method Overview
Unlike approaches that add external knowledge stores or extra parameters, F-Learning operates directly on model parameters and applies to both full-model fine-tuning and parameter-efficient fine-tuning methods. It has two stages: forgetting old knowledge and learning new knowledge.
Forgetting Old Knowledge
Assume supervised fine-tuning (SFT) on a dataset injects or activates knowledge by changing model parameters. Define the parameter increment as the knowledge parameter. For a base model with parameters θ and a dataset D, the knowledge parameter is the difference between the fine-tuned parameters and the original parameters.
![]()
Concretely, fine-tune the base model on a dataset containing the old knowledge to obtain parameters θ_old_ft, then compute the knowledge parameter Δ_old = θ_old_ft ? θ. To forget the old knowledge, subtract a scaled version of Δ_old from θ, producing a new parameter set:
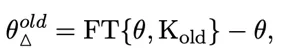
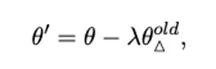
Here lambda is a hyperparameter controlling the forgetting proportion. The forgetting step assumes the model has sufficiently learned the old knowledge; otherwise, forgetting is unnecessary.
Learning New Knowledge
After the forgetting step, the model is fine-tuned on the dataset containing new knowledge. Let FT denote supervised fine-tuning. The learning step updates parameters starting from the forgotten model to obtain the new model parameters that incorporate the updated knowledge.
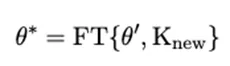
Experiments
Experiments use the ZsRE and COUNTERFACT datasets with three evaluation metrics: Reliability, Generality, and Locality. These metrics respectively measure update accuracy, generalization to paraphrases or contexts, and impact on unrelated knowledge. The baseline is direct supervised fine-tuning of the original model on the new knowledge.
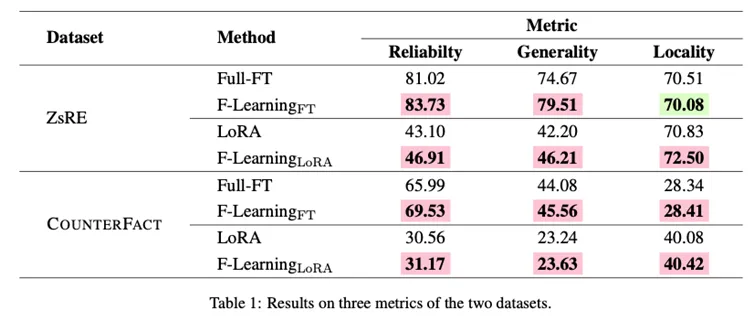
The base model is LLaMA2-7B. Since the experiments focus on replacing old facts with new ones, the model is first fine-tuned on the old-knowledge dataset for 3 epochs. For the F-Learning runs in Table 1, lambda values are {0.3, 0.7, 0.1, 1.5}. All experiments use a learning rate of 5e-5 and 3 epochs. During evaluation the sampling temperature is set to 0 to ensure deterministic outputs. Hardware: four A100-80G GPUs.
Results show that after the initial forgetting step, both full-model fine-tuning and LoRA show substantial improvement in learning new facts. For example, compared to direct full-model fine-tuning, F-Learning (full fine-tuning) increases Reliability and Generality by 2.71 and 4.84 points on ZsRE, while Locality decreases by only 0.43 points. Similar gains are observed for F-Learning with LoRA. Compared with LoRA alone, F-Learning with LoRA improves Reliability, Generality, and Locality by 3.81, 4.01, and 1.67 points on ZsRE. On COUNTERFACT, F-Learning with LoRA improves Reliability, Generality, and Locality by 3.54, 1.48, and 0.07 points over direct full-model fine-tuning. Overall, full-model fine-tuning still shows stronger raw learning capacity than LoRA, and F-Learning provides improvements over both.
LoRA Forgetting Followed by Full-Model Learning
In the previous setup, forgetting and learning used the same fine-tuning method (either full-model or LoRA). However, subtracting full-model parameter deltas to forget old knowledge can sometimes damage core model functionality and degrade evaluation metrics. Because LoRA modifies a much smaller parameter subspace, subtracting LoRA deltas affects the base model less. The authors therefore test a hybrid: forget old knowledge by subtracting LoRA parameter deltas, then learn new knowledge by full-model fine-tuning.
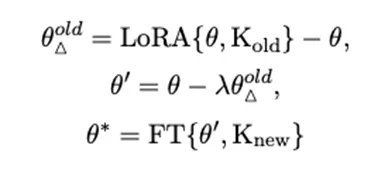
Using the same experimental settings, Table 2 reports results. For those runs, lambda values used in F-Learning are {0.3, 3, 0.1, 3}. The results indicate that forgetting via LoRA and then learning via full-model fine-tuning can outperform direct full-model fine-tuning. For example, compared with F-Learning full fine-tuning, the hybrid F-Learning LoRA→FT increases Reliability and Generality on COUNTERFACT by 9.20 and 6.11 points. On ZsRE, the hybrid is roughly 1–2 points lower in some metrics but still provides advantages for full-model fine-tuning and room for improvement. Locality improves by about 1 point on both datasets. The authors attribute this to smaller parameter perturbations when using LoRA for forgetting, which reduces collateral damage to unrelated knowledge. Empirically, subtracting LoRA parameter deltas can approximate subtracting full-model deltas while offering large savings in time and compute.
Conclusions
Main contributions:
- Introduce a knowledge-update fine-tuning paradigm for LLMs called F-Learning (forgetting before learning).
- Show experimentally that F-Learning improves knowledge-update performance for both full-model and parameter-efficient fine-tuning methods.
- Demonstrate that subtracting LoRA parameter deltas to forget old knowledge can approximate the effect of subtracting full-model deltas, with lower compute cost.





