ALLPCB
ALLPCB


Overview
With the arrival of augmented reality (AR) and autonomous driving, 3D data volumes are growing rapidly. Algorithms that process 3D data will be applied to applications such as robotic navigation and AR-based user interfaces. Motivated by this trend, researchers at Matroid proposed FusionNet, a framework for classifying 3D CAD objects on the Princeton ModelNet benchmark.
From 2D CNNs to 3D CNNs
The core of FusionNet is a novel 3D convolutional neural network (Convolutional Neural Networks, CNN) applied to 3D objects. Traditional 2D CNNs for image classification are composed of multiple hidden layers, where the first layer applies a sliding 2D window across the image to perform convolution. Subsequent hidden layers learn progressively higher-level features, and the final layer maps to output classes. For example, the ModelNet40 challenge contains 40 classes, so the final layer has 40 neurons, each corresponding to a class such as "cat" or "vehicle". The class with the strongest activation determines the predicted label.
That model assumes inputs are images, i.e., 2D data. How can we extend this to three dimensions? One approach is to render 2D projections of the 3D object from multiple viewpoints and run standard 2D CNNs on those projections. Many top submissions to the Princeton ModelNet Challenge follow this multi-view projection strategy. FusionNet uses multi-view 2D projections as well, but its key innovation is the addition of a 3D CNN that operates directly on volumetric data, eliminating the need for projection.
Volumetric Representation
Instead of sliding a 2D window, we slide a 3D window through space. In this volumetric representation, objects are discretized into a 30×30×30 voxel grid. A voxel is assigned a value of 1 if any part of the object occupies that 1×1×1 cell, and 0 otherwise. Unlike prior work, FusionNet learns object features using both multi-view pixel-based representations and voxel-based volumetric representations. Combining the two representations yields better 3D CAD object classification performance than using either one alone. Examples follow.

Figure 1. Two representations. Left: 2D projections of bathtub, barstool, toilet, and wardrobe. Right: the same objects after voxelization. Image courtesy of Reza Zadeh.
FusionNet: Combining Voxel and Multi-View Networks
We built two voxel-based convolutional neural networks (V-CNN I and V-CNN II) and one multi-view pixel-based network (MV-CNN). The figure below shows how these networks are combined to produce the final classification. Standard 2D CNNs learn local spatial features from images, while the voxel-based networks learn volumetric features.
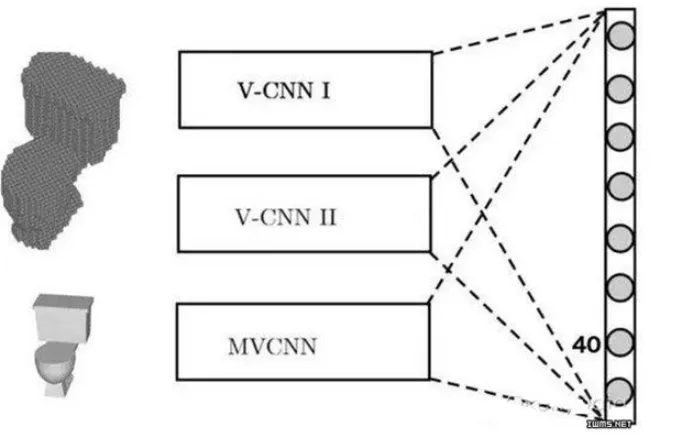
Figure 2. FusionNet is a mixture of three neural networks: V-CNN I, V-CNN II, and MV-CNN. The MV-CNN is based on the AlexNet architecture and was pre-trained on ImageNet. The three networks are fused at the scoring layer by computing a linear combination of their scores to determine the final predicted class. The first two networks take voxelized CAD models as input, while the third uses 2D projections. Image courtesy of Reza Zadeh.
Network Details and Training
The MV-CNN uses a standard pre-trained model (AlexNet) as its base and is warm-started by pretraining on the large-scale 2D image dataset ImageNet. Pretraining means many features useful for 2D image classification do not need to be trained from scratch. One of the voxel networks used, V-CNN I, is shown below.
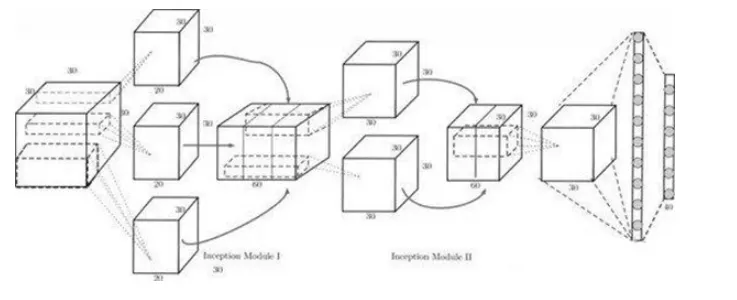
Figure 3. V-CNN I architecture. This design is inspired by GoogLeNet and uses Inception modules. The Inception module concatenates outputs from kernels of different sizes, helping the network learn multi-scale features while enabling parameter sharing in subsequent convolutional layers.
Summary
In summary, FusionNet fuses three networks: one based on multi-view pixel representations and two based on voxelized volumetric representations. The approach leverages the strengths of each network type to improve classifier performance. Each network component observes objects from multiple viewpoints before classification. Although observing objects from many angles intuitively provides more information than a single view, effectively integrating that information to improve accuracy is nontrivial. FusionNet uses 20 multi-view pixel features and 60 voxel-based CAD features to classify objects. FusionNet outperformed the previous top entry on the Princeton ModelNet 40-class leaderboard, demonstrating its effectiveness.