 ALLPCB
ALLPCB


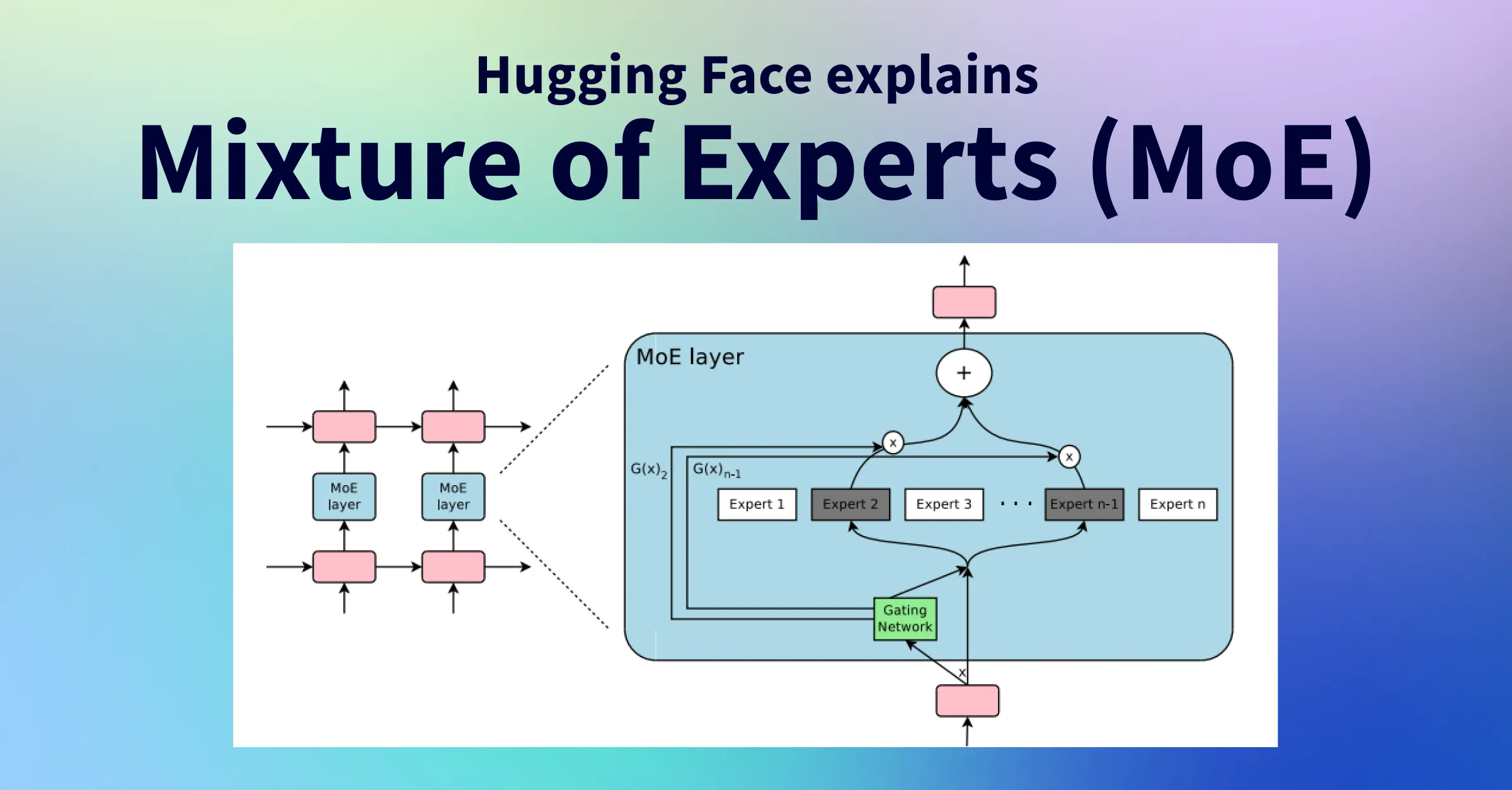
Overview
Mixture-of-Experts (MoE) models replace parts of a standard transformer with a sparse routing mechanism that selectively activates sub-networks, or experts. By routing different tokens to different experts, MoE models can scale parameter counts while keeping compute per token relatively low.
Core components
- Sparse MoE layer: These layers substitute the feed-forward network (FFN) layers in a conventional transformer. An MoE layer contains multiple "experts", each of which is an independent neural network. In practice, experts are often feed-forward networks, but they can also be more complex networks or even nested MoE layers, forming a hierarchical MoE.
- Gating network or router: This component decides which tokens are sent to which expert. For example, one token might be routed to the second expert while another token is routed to the first; a token can also be routed to multiple experts. Routing is a key aspect of MoE usage because the router is parameterized and trained alongside the rest of the network.
In summary, in an MoE model each FFN layer of a transformer is replaced by an MoE layer composed of a gating network and a number of experts.
Advantages and challenges
- Advantages: MoE architectures can enable much larger parameter counts for pretraining while keeping per-token computation sparse, which can reduce inference cost compared with dense models of similar parameter count.
- Training challenges: Although MoE can improve computational efficiency during pretraining, they often face generalization challenges during fine-tuning and can be prone to overfitting if not properly regularized.
- Inference and memory: At inference, only a subset of experts is active, improving throughput compared with a dense model of equivalent total parameters. However, all model parameters usually need to be loaded into memory, so MoE models can have high memory demands.
History and development
The idea of mixture-of-experts dates back to the 1991 paper Adaptive Mixture of Local Experts, which framed the approach as an ensemble of specialized networks supervised by a gating mechanism. During training, both experts and the gating network are optimized to improve their respective performance and routing decisions.
Between 2010 and 2015, two lines of research advanced MoE concepts:
- Component-level experts: Researchers explored treating MoE as a component within deeper networks, allowing MoE modules to be embedded at certain layers in a multi-layer architecture to increase model capacity efficiently.
- Conditional computation: Work investigated dynamically activating or deactivating network components based on input tokens, reducing redundant computation by conditioning which parts of the network run for a given input.
These lines of research converged in natural language processing applications. In 2017, Shazeer and colleagues applied sparse MoE techniques to large-scale LSTM models, demonstrating that sparsity could enable very large models while keeping inference fast. That work focused on machine translation and also highlighted practical challenges such as communication costs and training instability in distributed settings.
MoE techniques later enabled training models with hundreds of billions or trillions of parameters, including open-source efforts such as very large switch-style transformers. MoE has been explored beyond NLP into computer vision and other domains.
Recent attention and evaluations
MoE models have regained attention due to several recent developments. A Reddit post speculated that GPT-4 might be implemented as a collection of expert submodules, suggesting a cluster of MoE components. Separately, the company MistralAI released Mistral-8x7B-MoE, a model combining eight 7-billion-parameter models using MoE techniques.
Reported characteristics of Mistral-8x7B-MoE include the ability to handle long contexts (32K tokens), competitive performance across several European languages, strong code capabilities, and favorable benchmark scores after instruction fine-tuning. Some evaluations reported that a fine-tuned MoE variant exceeded the performance of certain dense Llama 2 models on specific benchmarks. These results suggest MoE can be effective in practice when engineering and training challenges are addressed.





