 ALLPCB
ALLPCB


2023 marked the arrival of artificial intelligence 2.0, with large models and generative AI as milestones that shifted development from isolated innovations to scalable deployment. These technologies deeply enable enterprise workflows and are driving differentiation and maturation across the industrial chain. The new generation of AI infrastructure for industry users adopts a "large center + nodes" model to build regional compute networks, promoting regional economic integration and intelligent development through coordinated construction and operation. Model as a Service (MaaS) has become central, offering large-model services via cloud platforms to accelerate AI application deployment and reduce the cost of adopting large-model services, enabling deeper integration of AI across industries.
1. Three Waves of Change Triggered by AI Infrastructure
The first wave in 2023 was a "knowledge productivity revolution" centered on large language models, transforming knowledge engineering much like the printing revolution did in the Middle Ages. Large language models learn at high speed and, in human-machine collaborative modes, significantly improve the speed and accuracy of knowledge acquisition, search, and dissemination.
The second wave is a "software revolution." Intelligent programming assistants such as SenseTime's code assistant have improved development efficiency by over 50% by covering the software development lifecycle. China has the second-largest population of programmers worldwide, and Chinese has become an effective development language for some models. Large language models also support serial multi-software workflows and coordinated multi-model combinations, applied in AI agents, Mixture of Experts architectures, comprehensive intelligent customer service, and more. A new generation of AI-native software applications is emerging, shaping the thinking of younger developers toward model-based innovation and MaaS-driven tools.
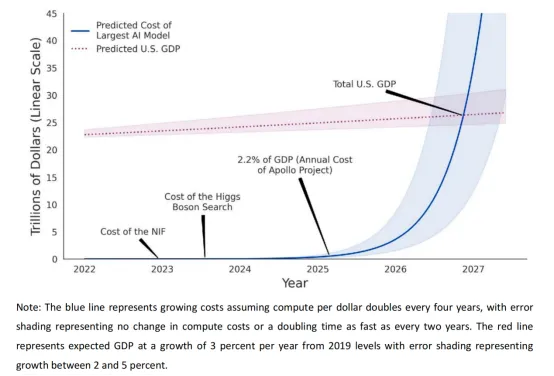
The third wave is an "AI compute revolution." As model scales expand, demand for AI compute grows exponentially, challenging linear-growth regional infrastructure. This tension is driving engineering innovations in AI compute infrastructure to reduce cost and improve efficiency. AI is becoming a general-purpose infrastructure that empowers many industries, while the "battle of many models" is evolving into industry specialization. Reports indicate large-model compute demand can double every 1-2 months, showing exponential growth beyond traditional architectures. Short-term market effects have emerged, such as AI chip capacity bottlenecks and price rises. With large-scale infrastructure investment and technical innovation, core challenges like training cost, GPU supply, and communication bottlenecks are expected to be addressed in the coming years, lowering overall AI compute costs and enabling widespread generative AI applications.
2. Large Models and Generative AI Propel AI 2.0
AI 2.0 is dominated by generative AI, shifting from prior detection and rule-following modes to enabling human-like creative processes via large-model training, moving systems from "classifiers" to "generators." Forecasts suggest generative AI will account for 42% of global AI spending by 2027, reaching $180 billion with a high compound growth rate. Large models form the foundation of generative AI; the Chinese market has released over 300 large models. Recognition of generative AI's disruptive potential is growing: Gartner predicts that by 2026, over 80% of enterprises will use generative AI APIs or models, or have deployed generative AI in production, a marked increase from early 2023. Generative AI is moving from discussion to practice and promises substantial value creation. McKinsey estimates generative AI could add about $7 trillion to the global economy, increasing AI's overall economic impact by roughly 50%, with China contributing around $2 trillion, nearly one third of the global total.
1. Generative AI Accelerates Industry-Scale Adoption
Generative AI is moving quickly from isolated innovations to deployment across business processes to enhance competitive advantage. Surveys indicate one third of enterprises regularly use generative AI in at least one business function. Companies are reallocating ICT budgets into generative AI to capture measurable returns. According to IDC research, 24% of enterprises in China have already invested in generative AI, 69% are screening potential use cases or conducting proofs of concept, and an estimated 40% of Chinese enterprises will adopt generative AI by 2026, potentially doubling revenue growth compared to competitors when developing digital products and services collaboratively.
Enterprises are adjusting AI strategies to accommodate the rapid rise of generative AI, shifting from long-range fragmented plans typical of AI 1.0 to short-term, action-oriented strategies that increasingly cover core business functions. Use cases are moving from predictive analytics and automation to content generation and creative tasks. As generative AI becomes a productivity tool, training employees to use these tools responsibly is a growing priority.
Generative AI enables collaborative innovation between employees and AI, extending human expertise and creativity while improving efficiency. It makes exploring more solution possibilities faster and cheaper, potentially unlocking more value. Gartner expects over 100 million people to work alongside synthetic virtual colleagues by 2026.
2. Industrial Chain Matures and Infrastructure Becomes Fundamental
As enterprises rapidly deploy large models and generative AI into deeper industry applications, the AI industry chain is maturing and differentiating. New roles and links appear across upstream and downstream segments, requiring new infrastructure to support diverse business needs and standards.
1) Intelligent compute becomes central
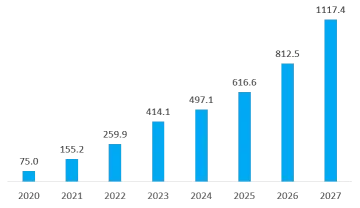
Enterprises prefer AI-ready data centers or GPU clusters for large-model training to shorten deployment time and avoid large capex. Intelligent compute optimized for large-model training is the main driver of compute growth. Forecasts show China's intelligent compute capacity could reach 1117.4 EFLOPS (FP16) by 2027, with a compound annual growth rate of 33.9% from 2022 to 2027, while general compute grows at 16.6% annually in the same period.
2) Development paradigm shifts to large-model-centered workflows
AI 1.0 development relied on detailed, complex code to express logic, which became costly and less accurate as scenarios fragmented. AI 2.0 leverages reinforcement learning, base models, and human feedback to enter a scalable development phase. Fine-tuning base models to business logic, combined with prompt engineering, enables quicker, lower-cost, and higher-accuracy coverage of broader scenarios, ushering in a pervasive, fast-growing AI era.
3) Generative AI enters a broad expansion phase
As base models mature, generative AI applications are exploding. Early text and image apps like ChatGPT and Midjourney expanded user bases rapidly. Subsequently, audio generation, video generation, multimodal generation, and industry-focused tools (code generation, Copilot, digital humans, marketing tools, chat assistants, etc.) emerged. In 2023 OpenAI launched GPTs and planned a GPT Store to let users create customized applications combining instructions, external knowledge, and capabilities without coding. This personalization and commercialization model broadens generative AI development beyond a few vendors to many developers.
3. New Requirements for AI Infrastructure in AI 2.0
AI 2.0 imposes new demands across compute, algorithm platforms, data, and engineering systems. Traditional CPU-centered cloud infrastructure designed for the mobile internet era cannot meet the needs of large-model training and the surge in generative AI applications.
1. Traditional compute cannot meet new demands
Large-model training and generative AI greatly increase demand for GPUs and heterogeneous computing; CPU compute alone is insufficient. This raises requirements for GPU cluster efficiency and stability. Compute is not solved by simple scaling; it needs system-level engineering optimization while managing substantial capital investment. Balancing system stability and high efficiency is a key challenge.
1) Explosive growth in GPU-centric AI compute demand
Training a 175B-parameter GPT-3 model required about 3640 PFlop-days, using 1024 A100 GPUs for 34 days. As parameter counts grow, training demand continues to increase. Over the past four years, model parameter counts grew at roughly 400% CAGR, and compute demand increased by over 150,000x, far exceeding Moore's Law. For instance, GPT-4 reportedly has roughly 500x the parameters of GPT-3, needing 20k-30k A100 GPUs and about a month to train. Inference concurrency for generative AI applications will further raise compute needs, potentially exceeding training-phase demand.
2) High performance and efficiency are essential
Distributed training across multi-node, multi-GPU clusters is necessary to support large models, but large clusters do not equal high effective compute. Distributed training faces efficiency losses due to network communication and data caching issues. For models at the hundreds of billions to trillions of parameters, communication can account for up to 50% of training time; poor interconnects limit cluster scaling. Clusters require high-speed, reliable networking, and software-level optimizations. Load imbalance can cause network congestion, impacting synchronization across dozens or hundreds of GPU nodes. Checkpointing large models can also reduce GPU utilization; for example, with a file system write speed of 15 GB/s, a GPT-3 checkpoint can take 2.5 minutes, wasting resources. Supporting large-model training therefore demands hardware improvements and software design optimizations.
3) Exclusive, large-scale, long-duration training raises stability requirements
Large-model training across large GPU clusters takes long periods; a single node failure can halt training, and diagnosing fault causes and locations can be slow. For example, Meta reported OPT-17B training ideally would take 33 days on 1,000 80GB A100 GPUs, but actually took 90 days with 112 failures, mostly hardware-related, requiring many manual and automatic restarts. Node failures lengthen training time and waste compute. Ensuring cluster stability is therefore critical, requiring capabilities such as real-time fault monitoring, checkpoint resume, automatic isolation of faulty nodes, fast localization, and rapid recovery.
2. Data quality and efficiency determine high-quality model development
Model performance and alignment depend on high-quality data, but data acquisition, cleaning, and labeling are more challenging at scale. Efficient AI data pipelines are needed to meet large-model era demands. Training and applications may involve user privacy and sensitive data, so effective data governance is required to protect privacy and ensure security.
Building powerful and aligned large models requires high data quality and efficient processing. Source data often vary in quality and can include duplicates, invalid, fake, or sensitive records, directly affecting model performance and value. Preprocessing such as cleaning and labeling is necessary. Traditional manual data processing cannot meet the scale and cost-efficiency needs of large-model development; automated and intelligent data pipelines are required.
With increased use of generative AI, enterprises face heightened privacy and data security risks. Uploading code repositories or historical marketing data may expose user privacy or corporate secrets if not properly protected. During model training and interaction, efficient data governance and isolation mechanisms for uploaded data are urgent requirements. Data security is a critical criterion when selecting AI software providers.
3. Large models require new AI platform service models
Large models can help enterprises achieve business goals more efficiently, but most organizations lack the resources to build and maintain their own models due to high costs and specialist skill requirements. MaaS (Model as a Service) represents a new cloud service paradigm that offers large models as core AI infrastructure via cloud services, enabling developers and enterprises to conduct industrialized development more efficiently. Major vendors provide MaaS offerings.
MaaS accelerates AI application development and iteration by packaging pre-trained models with development tools and data management. Enterprises can invoke AI capabilities without building models from scratch, shortening time-to-market for new products, services, and business models. MaaS also lowers development costs and technical barriers, promoting deeper industry integration and higher AI penetration.
This service model fosters large-model ecosystems and scaled deployment. MaaS providers with strong technical capabilities and AI expertise open platforms and communities to attract enterprises and developers, creating diverse ecosystems that meet segmented AI demands and support large-scale application rollout.
4. Definition, Characteristics, and Value of Next-Generation AI Infrastructure
AI 2.0 requires rethinking infrastructure to support large-model training, inference, and large-scale generative AI deployment with finer-grained design and reconstruction. The next-generation AI infrastructure centers on large-model capability delivery, integrating compute resources, data services, and cloud services to maximize performance for large-model and generative AI applications. Key elements include data preparation and management, large-model training, inference, model capability invocation, and application deployment.
Vendors provide advisory services around large-model development to solve technical issues in training and usage. On the compute side, infrastructure offers comprehensive compute and storage products and services for training and inference, characterized by large compute capacity, high coordination, and strong scalability. This includes high-performance heterogeneous clusters, high-bandwidth compute networks, high-performance file storage, large-scale AI compute resources, and strong linear scalability with elastic cloud-native services.
The MaaS platform layer delivers complete service and toolchains for large-model applications, including base model libraries, production platforms, data management, and development tools. MaaS can offer prebuilt base models and APIs, one-stop development environments, AI-native application tools, and prebuilt high-quality datasets and data management services to meet diverse business needs, reducing user costs and accelerating industry adoption.
1. Main characteristics of next-generation AI infrastructure
1) Next-generation AI infrastructure is not simply AI-enabled traditional cloud; it differs in positioning and development paths. It targets industry users and provides a foundational AI platform for ultra-large model R&D, regional industry incubation, and application innovation. It supports sustainable operations that drive regional economic intelligence through localized deployment.
Intelligent compute centers adopt integrated build-and-operate models to maximize infrastructure value. They are physical carriers of AI infrastructure and comprehensive platforms offering public compute services, data sharing, ecosystem development, and industry innovation services. Planning should be industry-ecosystem oriented and emphasize support for regional industry and research scenarios. Sustainable operation helps local stakeholders absorb compute capacity, foster intelligent industry ecosystems, and cultivate AI talent.
For compute network layout, a "large center + nodes" model constructs cross-regional complementary, coordinated ultra-large-scale AI compute networks. Large centers host low-cost, massive compute clusters to meet training and deployment needs for trillion-parameter models, while nodes deployed in industry-strong regions meet integrated training and inference needs. Coordination between nodes and large centers enables cross-regional training and inference scheduling.
2. Social value created by next-generation AI infrastructure
Next-generation AI infrastructure lowers barriers to large-model development and application, creating social value in government service, industry innovation, and scientific research.
1) Improved government intelligence
Unified large-model capabilities can integrate fragmented government services to provide one-model services that enhance local governance. This supports efficient implementation of enterprise services and citizen services, enabling rapid insights from massive government data, analyzing policy implementation, and supporting policy formulation and execution. A unified citizen consultation interface powered by government models can identify citizen needs more accurately and improve service efficiency.
2) Industry innovation
The "large models + MaaS" approach fosters regional intelligence and accelerates industrial transformation. For example, agricultural remote-sensing models can upgrade and scale agricultural technology. AI infrastructure also supports industrial model development and application, enabling industrial-scale AI production.
3) Scientific research enablement
The "AI for Science" paradigm advances research. Large-model techniques have enabled breakthroughs such as protein structure prediction and longer-range, high-resolution weather forecasting. Large models support simulation and prediction in atomic motion, medical imaging, and astronomy, accelerating automation and intelligence in scientific experiments and promoting further breakthroughs in AI-enabled research.





