ALLPCB
ALLPCB


Overview
Researchers from ETH Zurich and Meta Reality Labs proposed a method that uses sparse motion sensors to estimate and track full-body pose.

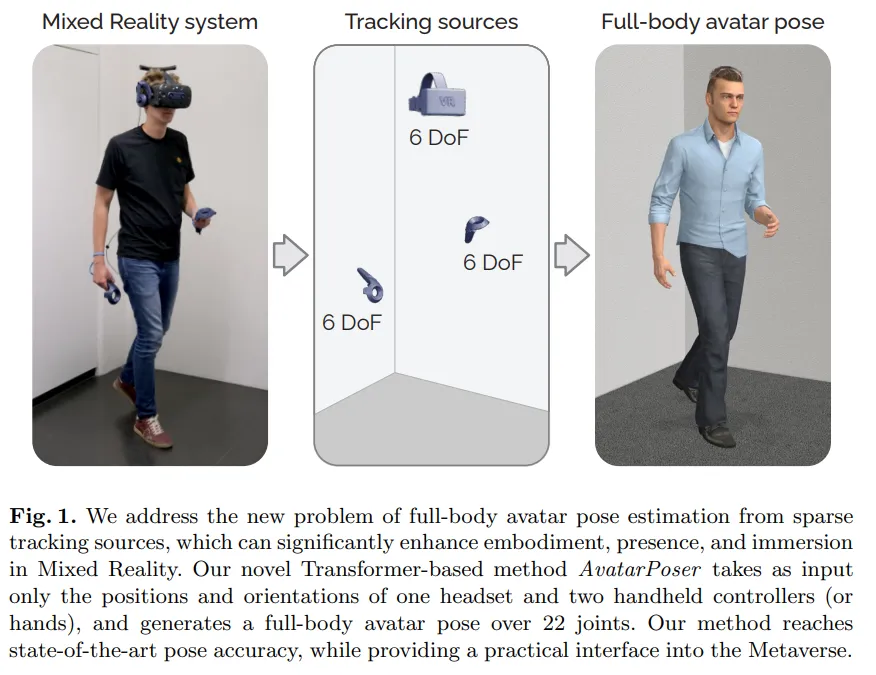
At Meta Connect, a virtual avatar with full legs drew attention from the machine learning and VR communities. Realistic and expressive avatars are important for immersion in virtual environments.

To address the limitations of upper-body-only avatars, researchers from ETH Zurich and Reality Labs at Meta presented AvatarPoser, a solution that estimates and tracks full-body pose from sparse motion sensor input. The work was accepted at ECCV 2022, and the paper and code have been released.

Research background
Current mixed-reality head-mounted displays and handheld controllers track the user's head and hand poses to enable interaction in AR and VR scenes. Although this provides sufficient input for many interactions, virtual avatars are typically limited to the upper body, which reduces immersion and can be problematic in collaborative settings. Prior work added extra trackers or sensors on the waist or legs to estimate full-body pose from sparse inputs, but this increases device complexity and reduces portability.
AvatarPoser is the first deep learning–based method to predict full-body pose in world coordinates using only the motion input from the user's head and hands. The approach uses a Transformer encoder to extract deep features from the input signals and decouples global body motion from local joint motion to guide pose estimation. The authors also combine the Transformer with inverse kinematics (IK) to refine arm joint positions to match the observed hand positions. In evaluations on the large motion-capture dataset AMASS, AvatarPoser achieved top results. Its fast inference speed supports real-time operation and provides a practical interface for whole-avatar representation and control in metaverse applications.
Related work
The paper compares AvatarPoser with prior methods including Final IK, LoBSTr (Eurographics 2021), CoolMoves (IMWUT 2021), and VAE-HMD (ICCV 2021). Final IK is a physics-based commercial solution that typically produces neutral lower-body poses, often resulting in unrealistic motion. LoBSTr uses a GRU model to predict the lower body from head, hand, and waist tracking signals and computes the upper body via an IK solver, but it requires an additional waist tracker. CoolMoves was the first method to estimate full-body pose using only headset and controller inputs, but its KNN-based approach can only interpolate within a small dataset and requires known motion types. VAE-HMD is a recent VAE-based method that generates plausible and diverse body poses from sparse inputs; however, it uses information relative to the waist, effectively relying on waist position as a fourth input. Overall, sparse-sensor full-body tracking methods face three main limitations:
- Most commercial solutions use inverse kinematics (IK) for full-body estimation. IK often yields static, unnatural motion, especially for joints far from known joint positions in the kinematic chain.
- Although the goal is to use only head and hand inputs, existing deep learning methods often implicitly rely on waist pose information. Most portable mixed-reality systems cannot track the waist, making full-body estimation harder.
- Even with waist tracking, prior methods often produce jitter and sliding artifacts in lower-body animation, frequently caused by unintended motion of waist-mounted trackers that do not move like the actual waist joint.
Method
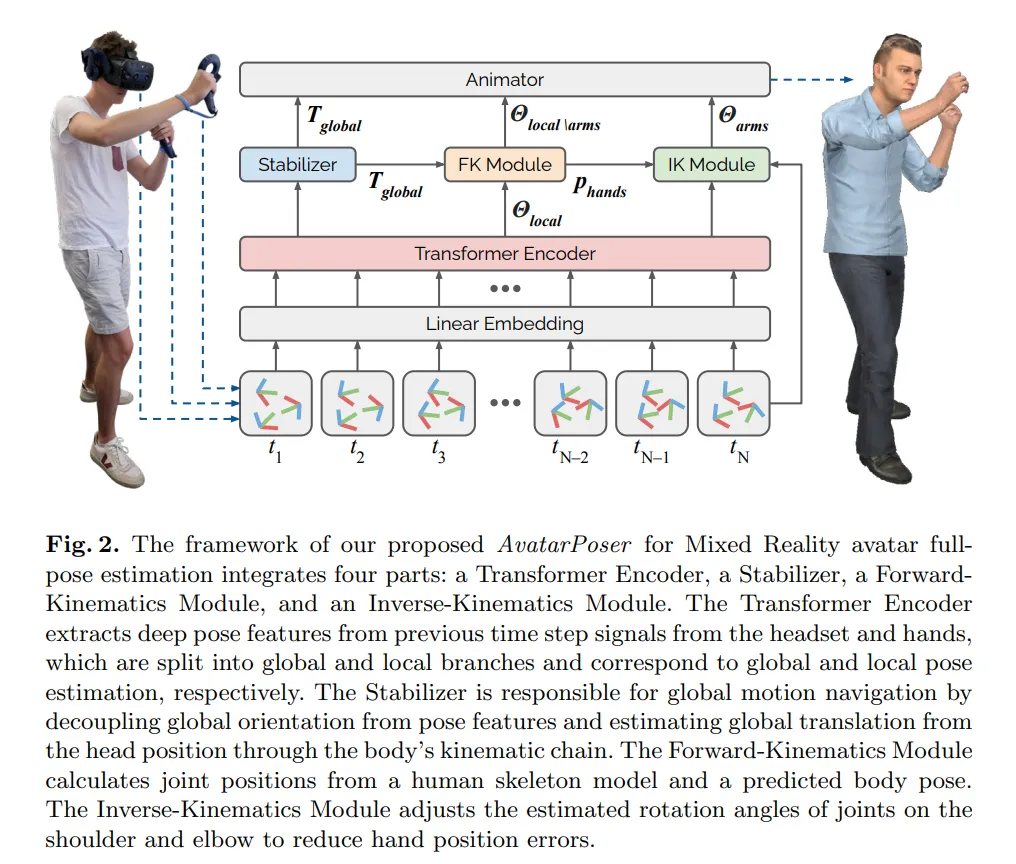
Figure 2 in the paper shows the AvatarPoser architecture. It is a temporal network that takes the 6D signals from the previous N-1 frames and the current Nth frame from sparse trackers as input, and predicts the global orientation of the body as well as local rotations of each joint relative to its parent. AvatarPoser has four components: a Transformer encoder, a stabilizer, a forward kinematics (FK) module, and an inverse kinematics (IK) module. Each component addresses a specific subtask.
Transformer encoder: The method builds on the Transformer due to its efficiency, scalability, and long-range modeling capabilities. Given the input signals, a linear embedding first projects features to 256 dimensions. The Transformer encoder extracts deep pose features from previous time steps of the headset and hand inputs. These features are shared by the stabilizer for global motion prediction and by a 2-layer multilayer perceptron (MLP) for local pose estimation. The Transformer uses 8 heads and 3 self-attention layers.
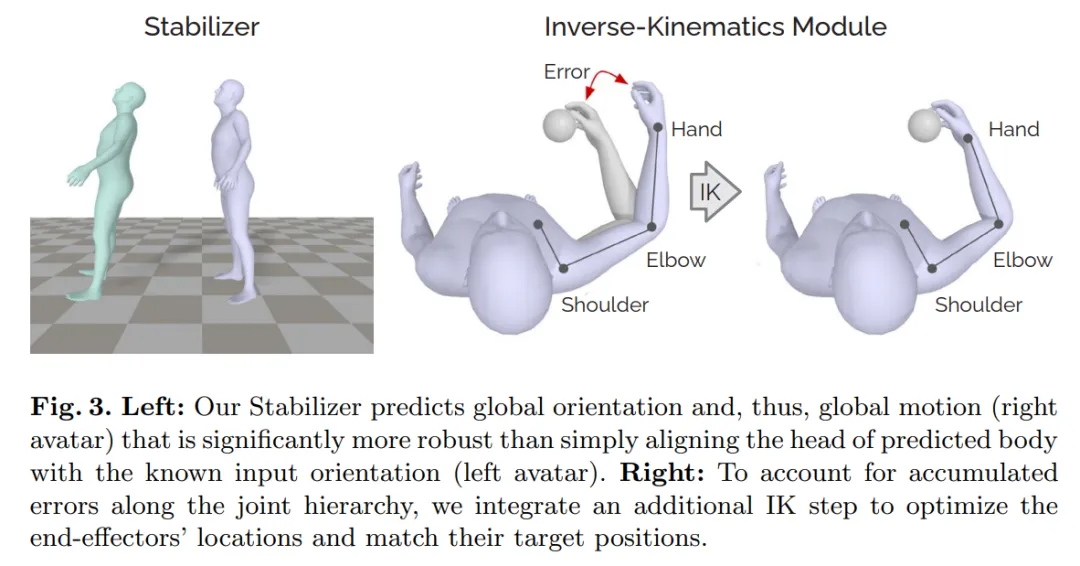
Stabilizer: The stabilizer is a 2-layer MLP that accepts the 256-dimensional pose feature from the Transformer and outputs the global motion direction (the pelvis rotation direction). The stabilizer decouples global direction from pose features and recovers global translation from the head position via the kinematic chain. Computing global direction directly from head pose can make the estimated global orientation overly sensitive to head rotation alone. For example, if a user only rotates their head while standing still, deriving global direction from the head rotation can produce large errors, causing the avatar to appear to float, as shown in the left of Figure 3.
Forward kinematics (FK) module: The FK module takes predicted local rotations and computes the positions of all joints for the given skeleton model. Rotation-based methods produce robust results without reprojecting to skeleton constraints, avoiding bone stretching or invalid configurations, but they can accumulate positional errors along the kinematic chain. Training without an FK module optimizes only joint rotation angles and does not consider the resulting joint positions during optimization.
Inverse kinematics (IK) module: A major issue with rotation-based pose estimation is that end-effector predictions can deviate from their true positions—even when end-effector positions are available as inputs, such as the hands in VR. Errors accumulate along the chain and even small positional errors at the hands can severely disrupt interaction with virtual interface elements. To address this, the authors use a separate IK module that adjusts arm joint rotations based on known hand positions. After the network outputs a pose, the IK module refines shoulder and elbow rotations to reduce hand position error, as illustrated in the right of Figure 3.
Experiments
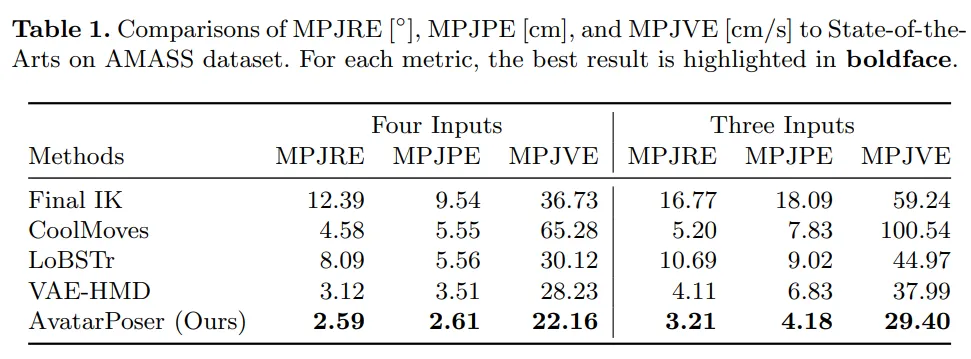
The authors evaluated configurations with three and four inputs. Metrics include mean per-joint rotation error (MPJRE), position error (MPJPE), and velocity error (MPJVE). Experiments show AvatarPoser achieved state-of-the-art performance in both settings.
Table 1 reports numerical results for MPJRE, MPJPE, and MPJVE with four and three inputs. AvatarPoser achieved the best results across all three metrics, outperforming other methods. VAE-HMD had the second-best MPJPE, followed by CoolMoves. Final IK produced the worst MPJPE and MPJRE because it optimizes end-effector positions and poses without considering other joints or motion smoothness. Consequently, LoBSTr, which relies on Final IK for upper-body estimation, also performed poorly. The results demonstrate the value of data-driven learning from motion-capture datasets; the authors also show in an ablation study how combining IK with deep learning improves hand-position accuracy.
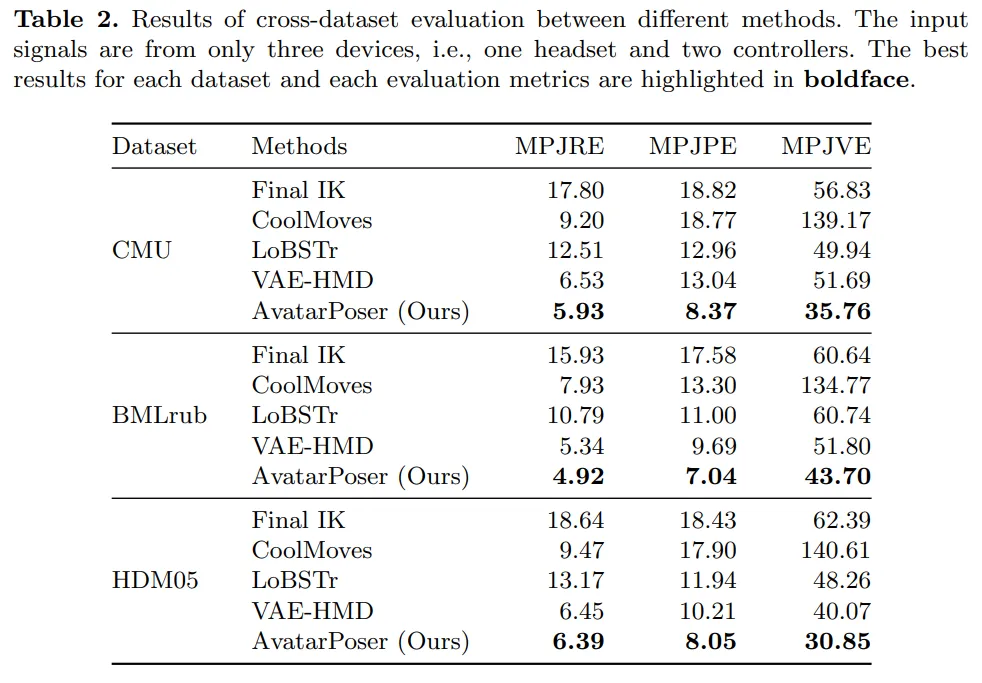
To evaluate generalization, the authors performed cross-dataset tests. They trained on two subsets and tested on another. Table 2 shows results on the CMU, BMLrub, and HDM05 datasets. AvatarPoser achieved the best results across all metrics and datasets.
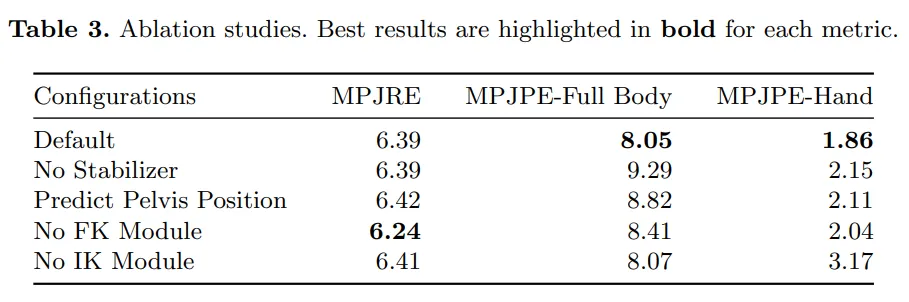
The authors conducted ablation studies on different submodules and report results in Table 3, using the same HDM05 test set as in Table 2. Metrics reported include MPJRE and MPJPE in centimeters. Besides whole-body joint position error, they computed average hand position error to show how the IK module improves hand localization.
The paper also includes qualitative videos for motions such as walking, exercising, and throwing, where errors are visualized in yellow. AvatarPoser produces notably smooth and accurate results.
AvatarPoser also performs well on consumer VR hardware despite being trained only on synthetic motion-capture data. The authors tested it on a VIVE Pro headset with two controllers. Results demonstrate stable performance across various motion types, including walking, sitting, standing, running, jumping, and crouching.
Conclusion
The paper presents AvatarPoser, a Transformer-based approach that estimates real human full-body pose using only motion signals from a mixed-reality headset and handheld controllers. By decoupling global motion from learned pose features and using that information to guide estimation, AvatarPoser achieves robust results without waist input. Combining learned prediction with model-based optimization balances full-body realism and accurate hand control. Extensive experiments on the AMASS dataset show state-of-the-art performance and suggest a practical solution for VR/AR applications.