 ALLPCB
ALLPCB


Abstract
Transformers are the backbone of large language models (LLMs). However, autoregressive generation remains memory- and compute-inefficient because the key-value (KV) cache stored in memory grows linearly with sequence length and batch size. This paper proposes Dynamic Memory Compression (DMC), an online method that compresses the KV cache during inference. Crucially, the model learns to apply different compression rates across heads and layers. By converting pretrained LLMs such as Llama 2 (7B, 13B, and 70B) into DMC Transformers and running on NVIDIA H100 GPUs, the authors report up to ~3.7x autoregressive inference throughput improvement. DMC requires further pretraining on an insignificant fraction of the original data and adds no extra parameters. The method preserves downstream performance while achieving up to 4x cache compression, outperforming Grouped Query Attention (GQA). GQA and DMC can also be combined for additional gains. Within a given memory budget, DMC enables longer context windows and larger batches.
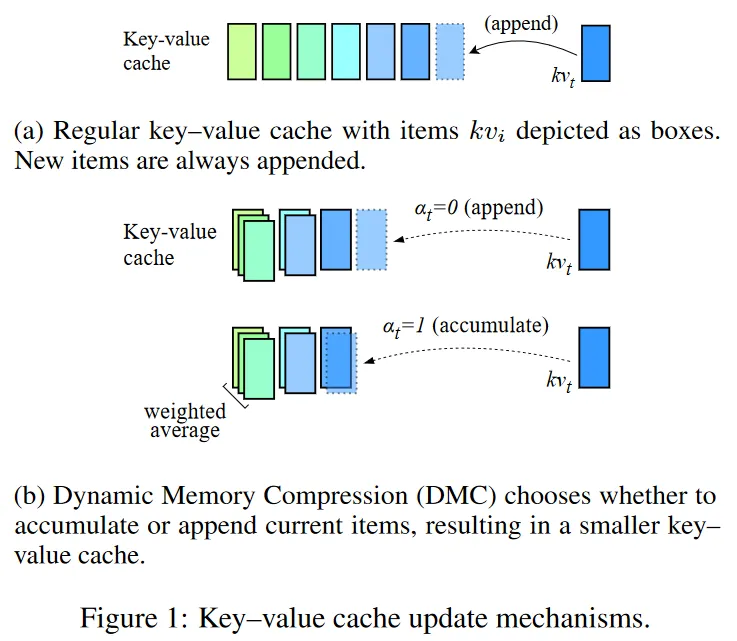
Problem addressed
This work targets the memory and generation efficiency challenges of LLMs during inference, specifically:
- Memory consumption: During autoregressive generation, Transformer models must store past tokens' key and value representations in memory. The KV cache size scales linearly with sequence length and batch size, causing memory use to grow rapidly for long sequences.
- Generation efficiency: The memory footprint limits achievable batch sizes and context lengths, reducing throughput for long-form generation or high-concurrency serving.
- Limits of prior approaches: Existing techniques such as Grouped Query Attention (GQA) reduce memory by sharing parameters across keys and values, but they often degrade downstream task performance.
DMC addresses these issues by enabling the model to compress the KV cache online during inference, learning per-head and per-layer compression strategies without adding additional parameters and with only modest further pretraining.
Related work
The paper situates DMC relative to several research areas and specific methods:
- Transformers and LLMs: Transformers are the foundational architecture for current generative and conversational models.
- Memory-efficient Transformer variants: Prior work aims to reduce KV cache size or memory cost, including approaches like Grouped Query Attention (GQA), which reduces the number of KV heads through parameter sharing.
- Dynamic compression methods: Previous dynamic compression approaches decide at inference time which tokens to drop from the KV cache; examples include work by Anagnostidis et al. (2023) and Kim & Cho (2020).
Method overview
DMC introduces an online KV cache compression mechanism for autoregressive inference with these core components:
- Online KV cache compression: At each generation step, DMC decides whether to append the current key and value to the cache or to merge them with the top elements of the cache using a weighted average.
- End-to-end learning: The model learns compression behavior through continued pretraining, progressively increasing a global compression target so the model adapts to different rates.
- Importance scoring: An importance variable is learned to determine the weighted average between the current token and cache entries during the accumulation operation.
These mechanisms allow DMC to substantially reduce KV cache size while maintaining original LLM performance, enabling longer contexts and larger batches under fixed memory constraints.
Experiments
The paper evaluates DMC across several setups:
- Baseline models: Llama 2 at multiple scales (7B, 13B, and 70B) were used as baselines.
- Target compression rates: Models were trained for various compression rates (2x, 3x, and 4x) by progressively increasing the compression target during continued pretraining.
- Downstream evaluation: Performance was measured on multiple downstream tasks, including MMLU (knowledge), QA datasets (commonsense reasoning), and HumanEval (code generation).
Results indicate DMC maintains or improves downstream performance while significantly improving inference throughput and memory efficiency, allowing larger batch sizes and longer sequences.
Future directions
Potential avenues for further research include:
- Applicability across architectures: Evaluating DMC on other Transformer variants or sequence-processing architectures.
- Integration during pretraining: Exploring designs that incorporate DMC during initial pretraining rather than only during continued pretraining.
- Interpretability: Deeper analysis of the learned compression patterns across heads and layers to understand what the model preserves or discards.
Summary
- Background: LLMs based on Transformers are effective but face memory and inference-efficiency challenges due to growing KV caches during autoregressive generation.
- Method: Dynamic Memory Compression (DMC) compresses the KV cache online during inference and learns per-head and per-layer compression strategies through continued pretraining.
- Experiments: Applied to Llama 2 models at multiple scales, DMC shows large throughput and memory-efficiency gains while preserving downstream task performance.
- Results: DMC achieves up to ~3.7x inference throughput improvements and up to 4x cache compression, and it can be combined with methods like GQA for additional benefits.





