ALLPCB
ALLPCB


Introduction
This article provides an overview of database technologies and introduces a range of database types to broaden learning and inform technical choices for projects.
Relational Databases
Relational databases organize and store data in tables. Each table is similar to a spreadsheet, composed of rows and columns. For example, a simple student management system might store student information in a table like this:
| Student ID | Name | Class ID |
|---|---|---|
| 1 | Xiao Li | 1 |
| 2 | Xiao Yu | 2 |
| 3 | Xiao Pi | 3 |
Each row represents a student record and each column represents an attribute. Structured Query Language (SQL) is used to query, filter, and manipulate relational table data.
A key feature of relational databases is that tables can be related. For example, the system can have a class table like this:
| Class ID | Class Name |
|---|---|
| 1 | Happy Class |
| 2 | Cool Class |
| 3 | Relaxed Class |
To find a student's class information, join the student table's Class ID with the class table's Class ID, without storing all columns together. SQL can join multiple tables to produce combined results:
| Student ID | Name | Class ID | Class Name |
|---|---|---|---|
| 1 | Xiao Li | 1 | Happy Class |
| 2 | Xiao Yu | 2 | Cool Class |
| 3 | Xiao Pi | 3 | Relaxed Class |
Relational databases also emphasize data consistency. They follow the ACID principles (atomicity, consistency, isolation, durability) and support transactions, ensuring consistent state across multiple operations (for example, in a transfer between accounts, both debit and credit occur atomically).
Because they balance flexible querying and accurate writes, relational databases are suitable for many systems, such as CRM, HRM, analytics, and financial systems. Common relational systems include MySQL, Oracle, PostgreSQL, and Microsoft SQL Server. MySQL is widely used due to its open-source nature and relative ease of learning.
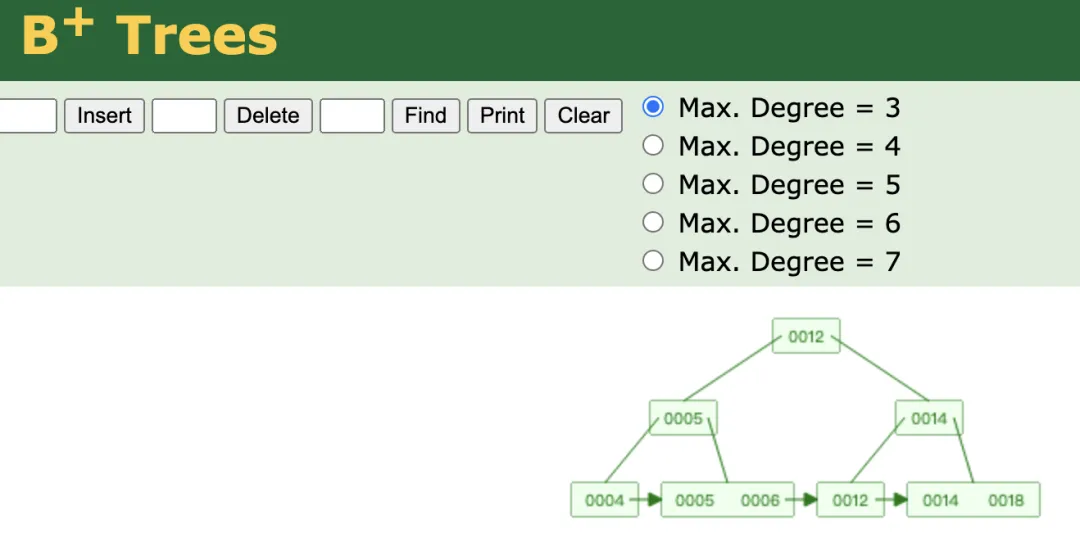
The relational model is based on formal mathematical theory. Implementations commonly use B+ trees for index structures; their balanced nature enables efficient queries and reasonable performance for inserts, updates, and deletes at scale.
Relational databases are suitable for most projects, but they are not a universal solution. When stored items are not strongly related or have flexible structures, relational databases may not be the best choice. For content such as articles, a document-oriented approach can be more convenient.
Non-Relational Databases (NoSQL)
NoSQL databases suit data with weak or flexible structure and scenarios requiring very fast access, such as strings or JSON. A common NoSQL type is key-value (KV) stores.
KV stores persist data as key-value pairs, similar to a HashMap; each key uniquely maps to a value, and keys and values can be arbitrary types (strings, numbers, arrays, etc.). For example, user profile data might be stored as a single value keyed by user ID.

KV stores have simple structures and offer high read/write performance. They are highly scalable because unrelated key-value pairs can be distributed across multiple machines, supporting sharding and load balancing. Common uses include caching, distributed sessions, distributed locks, and real-time statistics.
Redis is a prominent open-source, in-memory KV store with rich data types and persistence options. Other KV or wide-column systems include LevelDB, RocksDB, and Apache Cassandra.
KV implementations vary; a typical approach uses hash tables to store pairs. Different value types may use different internal representations—for example, Redis uses Simple Dynamic Strings (SDS) for string storage.
Specialized Databases
Beyond traditional relational and KV databases, there are databases optimized for specific data structures and application scenarios. These systems can provide more efficient storage and querying for particular use cases. Below are several specialized database types.
Search Engine Databases
Search engine databases provide full-text search capabilities for large volumes of text. They typically use an inverted index structure, which maps terms to document IDs, enabling fast and flexible fuzzy search and relevance ranking.
For example, given documents:
| Document ID | Content |
|---|---|
| 1 | Thanks for following Yupi |
| 2 | Yupi is a programmer |
| 3 | Thanks for following Rookie tutorials |
An inverted index maps words to document IDs:
| Word | Document IDs |
|---|---|
| thanks | 1, 3 |
| following | 1, 3 |
| yupi | 1, 2 |
| programmer | 2 |
With this index, a query is tokenized and the index is used to find relevant documents without scanning the entire dataset. Search databases also support relevance scoring to rank results. Popular search technologies include Elasticsearch, Apache Solr, and Apache Lucene.
Document Databases
Document databases store and manage semi-structured documents, commonly in JSON format. Unlike relational tables with fixed schemas, document stores hold hierarchical document structures where each document can have different fields.
| Document ID | Document |
|---|---|
| 1 | {"_id": 1, "title": "Article 1", "content": "Content of article 1"} |
| 2 | {"_id": 2, "title": "Article 2", "author": "Yupi"} |
Adding a field to a document does not require altering a central schema. Document databases scale well and are suitable for content management systems and collaborative document editing. Widely used document databases include MongoDB and Couchbase.
Time Series Databases
Time series databases are optimized for efficiently storing and processing time-stamped data. Each data point includes a timestamp as a primary dimension.
For a temperature monitoring system collecting per-minute samples, data might look like:
| Timestamp | Device ID | Temperature |
|---|---|---|
| 2023-07-01 10:00 | Device001 | 25.5 |
| 2023-07-01 10:01 | Device001 | 25.7 |
| 2023-07-01 10:02 | Device001 | 25.8 |
| 2023-07-01 10:03 | Device001 | 26.2 |
| 2023-07-01 10:04 | Device001 | 26.5 |
| 2023-07-01 10:05 | Device001 | 26.3 |
Time series databases support efficient range queries, aggregation, and visualization and are commonly used for IoT sensor data, log monitoring, and financial tick data. Examples include InfluxDB and TimescaleDB. They are often used with visualization tools like Grafana. Time series engines index by time; InfluxDB uses TSM (Time-Structured Merge Tree) and B+ trees for time indexes.
Vector Databases
Vector databases store and process high-dimensional vector data. Each vector represents an entity and contains multiple numeric dimensions. For example, facial recognition systems represent each face as a feature vector; vectors can have hundreds or thousands of dimensions.
| Face ID | Feature Vector |
|---|---|
| 1 | [0.1, 0.2, 0.3, ..., 0.5] |
| 2 | [0.1, 0.3, 0.2, ..., 0.4] |
Similarity between vectors indicates likeness. Vector databases support efficient storage, similarity computation, and approximate nearest neighbor search, useful for image retrieval, feature matching, recommendation systems, and storing embeddings used in AI. Popular vector databases include Milvus, Pinecone, and Faiss; some databases such as PostgreSQL also support vector types. Implementations rely heavily on index design (KD-trees, ball trees, inverted indexes, etc.) and often use parallel computation to accelerate searches.
Spatial Databases
Spatial databases handle geographic spatial data: geometric objects expressed in coordinate systems such as points, lines, and polygons. For example, storing the location of items in a room might use:
| Object ID | X | Y | Z |
|---|---|---|---|
| 1 | 2.5 | 3.0 | 1.8 |
| 2 | 1.0 | 4.2 | 2.3 |
| 3 | 3.7 | 2.1 | 1.5 |
Spatial databases enable efficient storage, querying, and analysis, such as intersection tests, path planning, and visualization. They are core to GIS systems and are used for navigation and urban planning. PostgreSQL with the PostGIS extension provides spatial capabilities. Spatial indexing structures include R-trees and quadtrees, and spatial databases implement algorithms for nearest-neighbor queries and spatial relationships.
Graph Databases
Graph databases specialize in storing graph-structured data composed of nodes and edges. For example, a social network of friends (friend-of-friend) can be modeled as a graph; each user is a node and friendships are edges.
Graph data can be stored as node and edge tables. Node table example:
| Node ID | Name |
|---|---|
| 1 | Xiao Wang |
| 2 | Xiao Li |
| 3 | Xiao Liu |
Edge table example:
| Edge ID | Type | Source | Target |
|---|---|---|---|
| 1 | friend | 1 | 2 |
| 2 | friend | 1 | 3 |
Graph databases enable fast queries and analysis of relationships, useful for social graphs, recommendation systems, and knowledge graphs. Common graph databases include Neo4j and TigerGraph, which support graph algorithms and distributed processing. Under the hood, graph systems use adjacency lists, adjacency matrices, and graph indexes to accelerate operations.
Columnar Databases
Columnar databases store data by column rather than by row. For analytics, storing each column contiguously improves query performance for aggregations because only the required columns need to be read. This layout also enables better compression for homogeneous column data.
For example, a daily revenue table stored by row:
| Date | Revenue | Cost | Profit |
|---|---|---|---|
| 2022-01-01 | 500 | 600 | -100 |
| 2022-01-02 | 280 | 450 | -170 |
| 2022-01-03 | 290 | 480 | -190 |
In a columnar store, the same matrix is conceptually transposed so each column is stored together. Aggregations such as total profit can read only the profit column, improving performance. Columnar databases are suited for real-time analytics, OLAP, and data warehouses. Examples include Apache HBase, ClickHouse, and Druid.
Multi-Model Databases
Multi-model databases support multiple data models within a single system, such as relational, document, and graph models. This can simplify application architecture by allowing different types of data to be stored and queried in one database rather than using separate specialized systems.
For example, an e-commerce system might store basic product metadata in relational form, detailed product descriptions as documents, and recommendation relationships in a graph. A multi-model database can handle these types centrally and may support transactions to maintain consistency without cross-database coordination. Examples include ArangoDB and OrientDB. Multi-model databases are flexible but are used less frequently in typical development; they are an option to consider when their capabilities match application requirements.