 ALLPCB
ALLPCB


Overview
Self-supervised monocular depth estimation can be trained on large amounts of unlabeled video, which makes dataset collection convenient. However, real-world video sequences often contain many dynamic objects, while self-supervised training typically assumes a static scene; that assumption breaks down in dynamic environments.
Previously I reviewed SC-Depth V3 (TPAMI 2023), which addresses self-supervised monocular depth estimation in dynamic scenes. Recently I examined a related NeurIPS 2023 work, Dynamo-Depth, for a comparative study.

Abstract
Unsupervised monocular depth estimation has shown promising results but usually assumes a static scene. In dynamic scenes, apparent object motion can be explained either by assuming independent object motion or by changing object depth, creating ambiguity that leads depth estimators to predict incorrect depths for moving objects. Dynamo-Depth addresses this by jointly learning monocular depth, a 3D independent flow field, and motion segmentation from unlabeled monocular video to resolve dynamic motion ambiguity. The key insight is that a good initial estimate of motion segmentation is sufficient for jointly learning depth and independent motion despite inherent ambiguities. The method achieves state-of-the-art monocular depth performance on Waymo Open and nuScenes, with significant improvements on moving objects.
Method
Recap: standard self-supervised monocular depth training
The typical pipeline has two networks: DepthNet and PoseNet. Given consecutive frames from a monocular video (or skip-frame pairs), DepthNet estimates the depth map for the target frame while PoseNet estimates the relative pose between frames. The target frame is then reconstructed using its estimated depth and the estimated pose, and the photometric reconstruction loss between the reconstructed image and the actual image is used as the supervision signal.
That framework assumes a fully static scene; dynamic object motion significantly degrades loss computation.
There are many extensions to this basic framework (various loss terms, scale handling, temporal discontinuities, etc.). This article focuses specifically on handling dynamic scenes.
Primary application for outdoor monocular depth estimation
The main use case is autonomous driving, where the ego-vehicle moves along the road and other vehicles often travel in the same or opposing directions.
Key challenge in that scenario
When driving, nearby objects appear to move faster while distant objects appear slower. Mathematically, this creates epipolar ambiguity: a vehicle moving in the same direction as the ego-vehicle may appear nearly static, causing the network to infer a very large distance; conversely, an oncoming vehicle may be inferred to be very close. Critically, incorrect depth estimates can still produce correct optical flow or pose estimates, since the photometric loss can be satisfied by compensating errors.
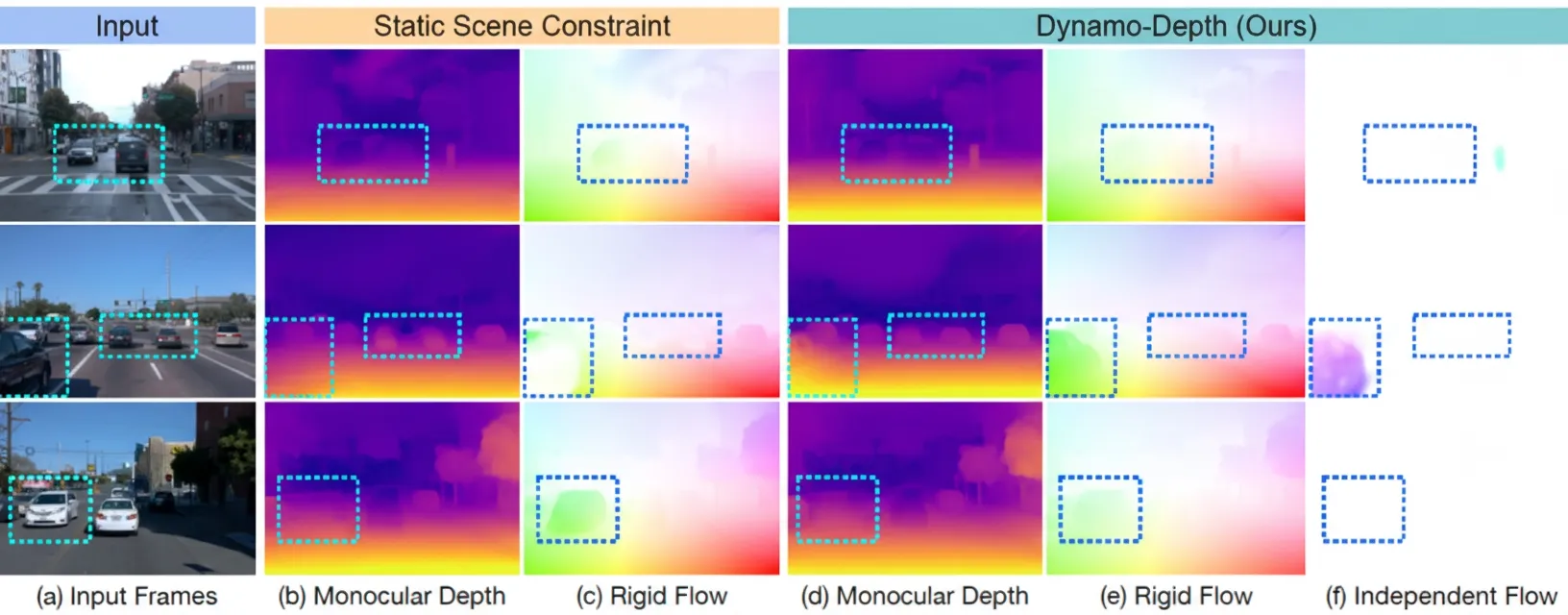
Is simple regularization sufficient?
Learning the motion of dynamic objects is substantially harder than learning static background depth.
Approach of Dynamo-Depth
The core idea is that modeling only the rigid flow induced by camera motion cannot fully explain dynamic object motion, so the method also learns a separate 3D independent flow field to capture object motion.
The pipeline has two parts. The first part assumes static scene geometry: it estimates a static 3D flow from the target frame depth and camera pose. The second part estimates a dynamic 3D flow using an independent flow predictor together with a motion mask. The two flow fields are combined to reconstruct the target image, and losses are applied on the reconstruction.
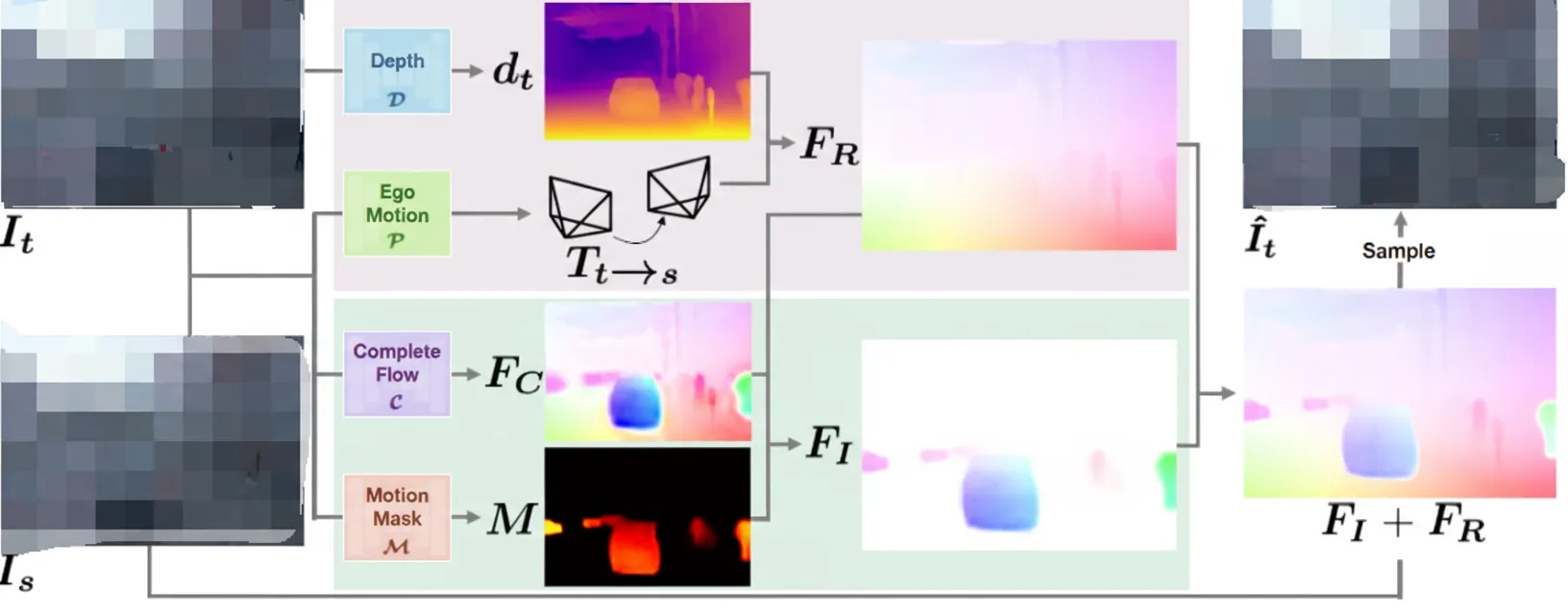
Why not directly predict the dynamic 3D flow for objects?
Two reasons:
- During training, target motion is the sum of camera motion and independent object motion; directly predicting the independent component is difficult when the inputs contain this mixture.
- Independent rigid motion estimation tends to be sparse, preferring no-dynamics solutions. Early in training, noisy depth and pose predictions can cause the network to converge to a high-sparsity solution that ignores dynamic objects.
Experiments
Datasets used are Waymo Open, nuScenes, and KITTI (Eigen split). Training used four NVIDIA 2080 Ti GPUs, batch size 12, and initial learning rate 5e-5. Standard metrics were used: Abs Rel, Sq Rel, RMS E, RMSE log, and three accuracy thresholds.
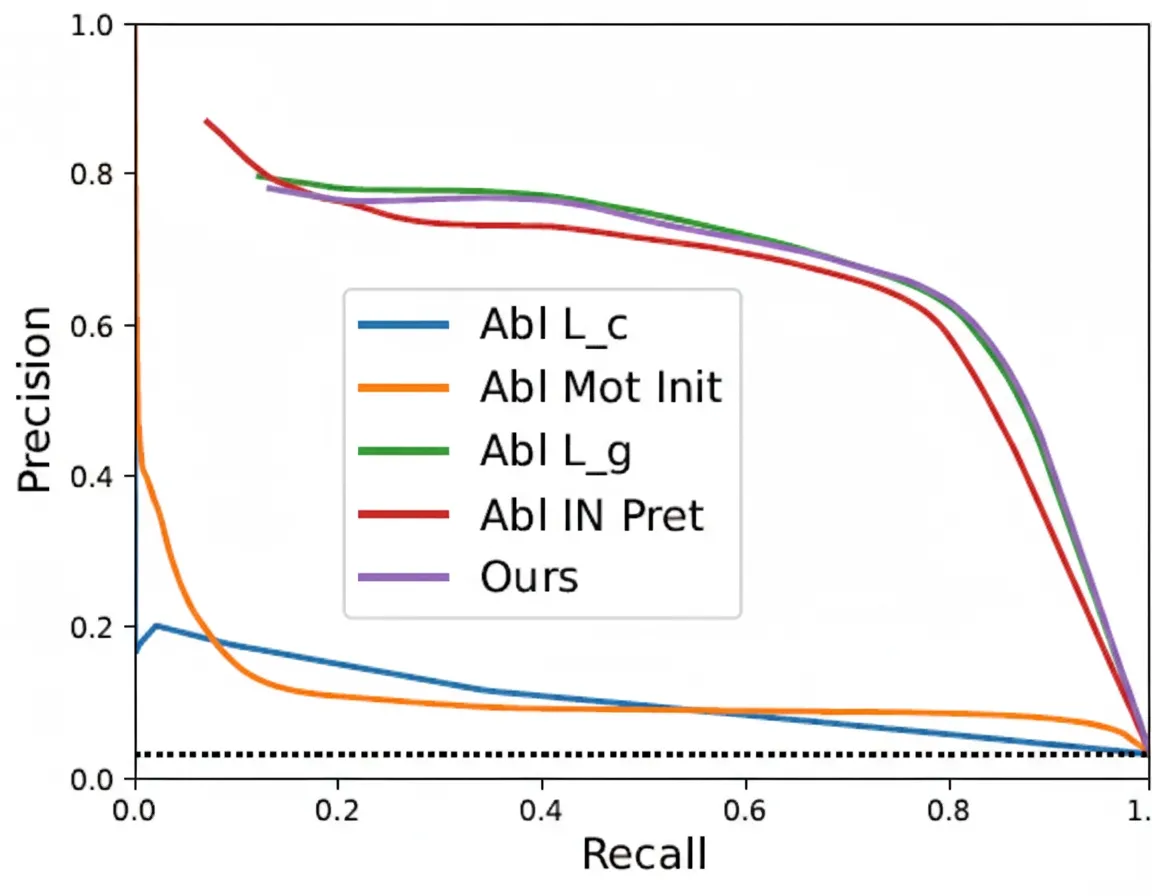
On Waymo Open, precision-recall curves were used as an ablation to evaluate the joint motion mask network. The method maintains high precision as recall increases and reaches an F1 score of 71.8% on Waymo Open.
Conclusion
Dynamo-Depth targets the autonomous driving case with vehicles often moving colinearly. The method jointly learns depth, pose, a 3D independent motion field, and motion segmentation, showing strong improvements on Waymo Open and nuScenes. However, the approach is specialized for that driving scenario and may be limited in broader contexts. For dynamic object handling, SC-Depth V3 still appears stronger in some aspects.





