 ALLPCB
ALLPCB


Summary
As Moore's Law slows, techniques beyond process-node scaling are becoming increasingly important for improving chip performance. In this research, NVIDIA used deep reinforcement learning to design arithmetic circuits that are smaller, faster, and more efficient, aiming to improve overall chip performance.

Large arrays of arithmetic circuits drive NVIDIA GPUs to deliver AI, high-performance computing, and graphics acceleration. Improving these arithmetic designs is therefore critical for GPU performance and efficiency.
In the paper "PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning," the authors show that an AI agent can design these circuits from scratch and that the AI-designed circuits can be smaller and faster than designs produced by state-of-the-art electronic design automation (EDA) tools.

Paper: PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning
The latest NVIDIA Hopper GPU architecture contains nearly 13,000 instances of circuits designed by AI. Figure 1 shows a 64-bit adder designed by PrefixRL (left) that is 25% smaller than a comparable design produced by a state-of-the-art EDA tool (right).

Circuit design overview
Arithmetic circuits on chips are built from logic gate networks (such as NAND, NOR, and XOR) and interconnect. Ideal circuits have the following attributes:
- Small: smaller area lets more circuits fit on a chip;
- Fast: lower latency improves chip performance;
- Low power consumption.
The researchers in this work focused on area and latency, noting that power correlates closely with area. Area and latency are often conflicting objectives, so the goal is to discover the Pareto frontier that provides the best trade-offs. In other words, for any target latency, the design should have minimal area.
PrefixRL targets a popular class of arithmetic designs: parallel prefix circuits. Many important GPU circuits—adders, incrementers, and encoders—are prefix circuits and can be represented as prefix graphs at a higher level.
The state space of all prefix graphs is enormous (on the order of O(2^{n^n})), making brute-force search infeasible. Figure 2 illustrates one iteration of PrefixRL constructing a 4-bit circuit.
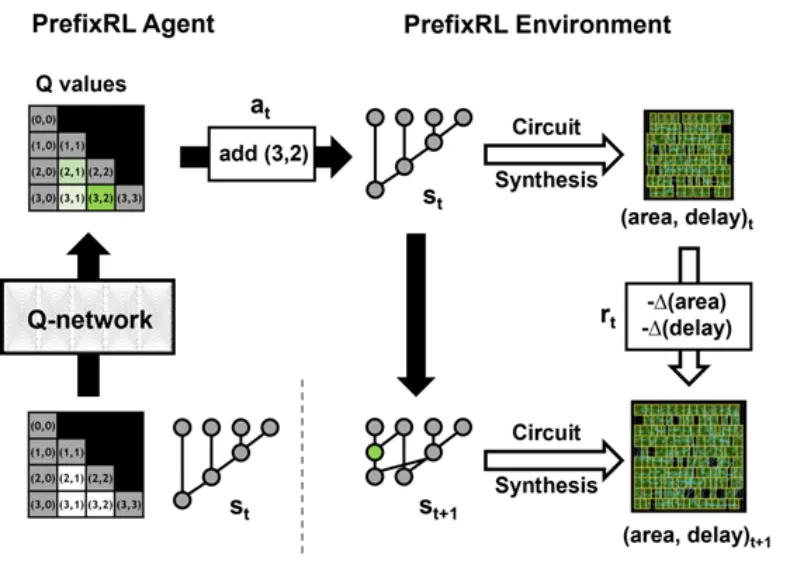
The researchers use a circuit generator to convert a prefix graph into a circuit of wires and logic gates. These generated circuits are then optimized by a physical synthesis tool that applies gate sizing, replication, and buffer insertion.
Because of these physical synthesis optimizations, final circuit properties (latency, area, and power) do not map directly from raw prefix-graph properties (such as levels and node count). For that reason, the agent learns to design prefix graphs while optimizing the properties of the final synthesized circuits. The arithmetic design task is framed as a reinforcement learning problem in which an agent is trained to optimize area and latency. For prefix circuits, the environment allows the RL agent to add or remove nodes in the prefix graph and then execute the following steps:
- The prefix graph is normalized to always preserve correct prefix computation;
- A circuit is generated from the normalized prefix graph;
- The circuit is physically synthesized using a physical synthesis tool;
- The circuit area and latency are measured.
In the animated figure, the RL agent incrementally constructs the prefix graph by adding or removing nodes. At each step, the agent receives a reward corresponding to improvements in circuit area and latency.

Original image is an interactive version
Fully convolutional Q-learning agent
The researchers trained the design agent using Q-learning. They represent the prefix graph on a grid where each grid element maps uniquely to a prefix node. This grid representation is used as input and output to the Q-network. Each input cell indicates whether a node exists. Each output cell represents the Q value for adding or removing the corresponding node.
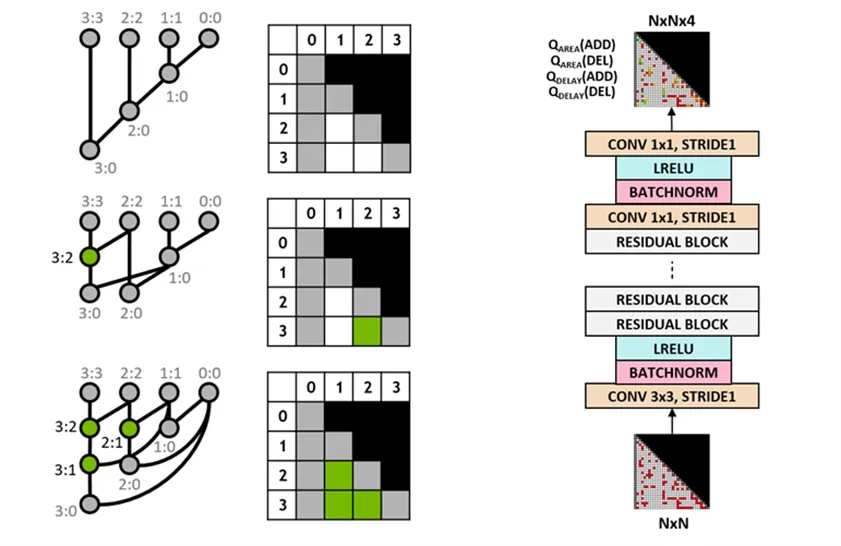
Figure 3: 4-bit prefix graph representation (left) and fully convolutional Q-learning agent architecture (right).
Raptor for distributed training
PrefixRL requires substantial compute. In physical synthesis, each GPU can require hundreds of CPUs for a single job, and a 64-bit training task can demand tens of thousands of GPU hours. To support this scale, the team developed a distributed reinforcement learning platform called Raptor that leverages hardware acceleration to enable industrial-scale RL training.
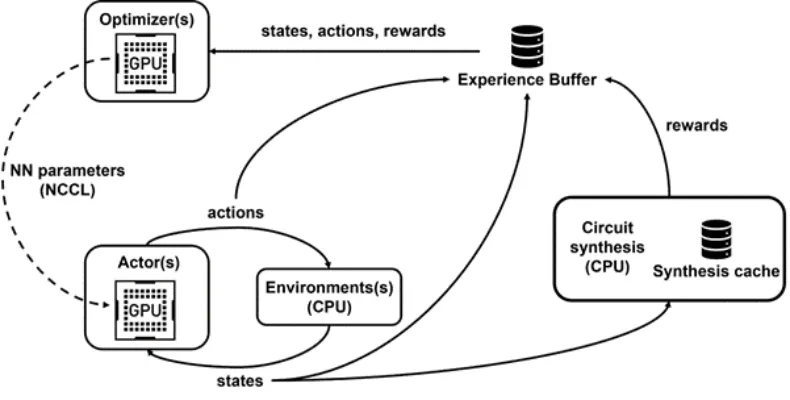
Raptor improves scalability and throughput through features such as job scheduling, custom networks, and GPU-aware data structures. In the PrefixRL context, Raptor enables hybrid allocation across CPU, GPU, and spot instances.
The training network in this application is diverse and benefits from several mechanisms:
- NCCL is used for point-to-point transfers so model parameters can be moved directly from learner GPUs to inference GPUs;
- Redis is used for asynchronous small messages such as rewards or statistics;
- JIT-compiled RPC handles high-throughput, low-latency requests such as uploading experience data.
Raptor also provides GPU-aware data structures, for example a multithreaded replay buffer that accepts experience from many workers, batches data in parallel, and preloads it to GPUs.
Figure 4 shows the PrefixRL framework supporting concurrent training and data collection, using NCCL to efficiently broadcast updated parameters to actors.
Figure 4: The researchers use Raptor to decouple parallel training and reward computation to overcome circuit synthesis latency.
Reward computation
Rewards combine area and latency objectives using a trade-off weight w in the range [0,1]. Agents are trained with different weights to obtain a Pareto frontier trading off area and latency. The physical synthesis tool is driven using the same trade-off weight associated with the agent being trained.
Performing physical synthesis inside the reward loop has two benefits:
- The agent learns to directly optimize final circuit properties for the target process node and library;
- The agent includes surrounding logic of the target algorithm during synthesis, jointly optimizing the algorithm circuit and its neighbors.
However, physical synthesis is slow (a 64-bit adder can take roughly 35 seconds), which can significantly slow RL training and exploration.
The researchers decoupled reward computation from state updates because the agent only needs the current prefix-graph state to act, not the synthesized circuit or prior rewards. Using Raptor, costly reward computations are delegated to a pool of CPU workers that perform synthesis in parallel while actor agents continue interacting with the environment without waiting.
When a CPU worker returns a reward, the result is inserted into the replay buffer. Synthesized rewards are cached to avoid redundant computation for repeated states.
Results and outlook
Figure 5 shows the area and latency of a 64-bit adder designed by PrefixRL compared to Pareto-dominant adders produced by a state-of-the-art EDA tool.
The best PrefixRL adder achieves 25% smaller area at the same latency compared with the EDA-tool adder. The prefix graphs that map to these Pareto-optimal adders after physical synthesis exhibit irregular structures.
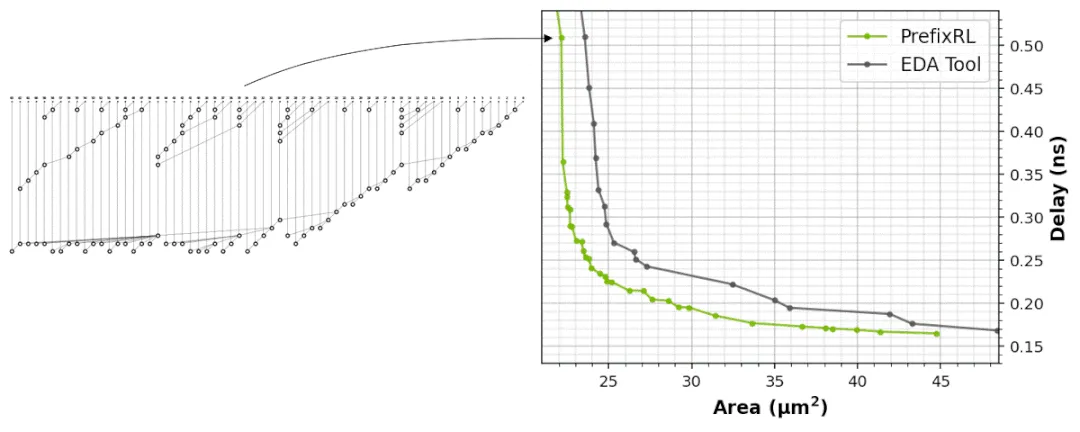
Figure 5: PrefixRL-designed arithmetic circuits can be smaller and faster than state-of-the-art EDA designs. Left: circuit architectures. Right: characteristics of the corresponding 64-bit adder circuits.
This work represents the first reported use of deep reinforcement learning agents to design arithmetic circuits. The approach provides a blueprint for applying AI to real-world circuit design problems, including defining action spaces, state representations, RL agent models, multi-objective optimization, and techniques to mitigate slow reward computation.





