 ALLPCB
ALLPCB



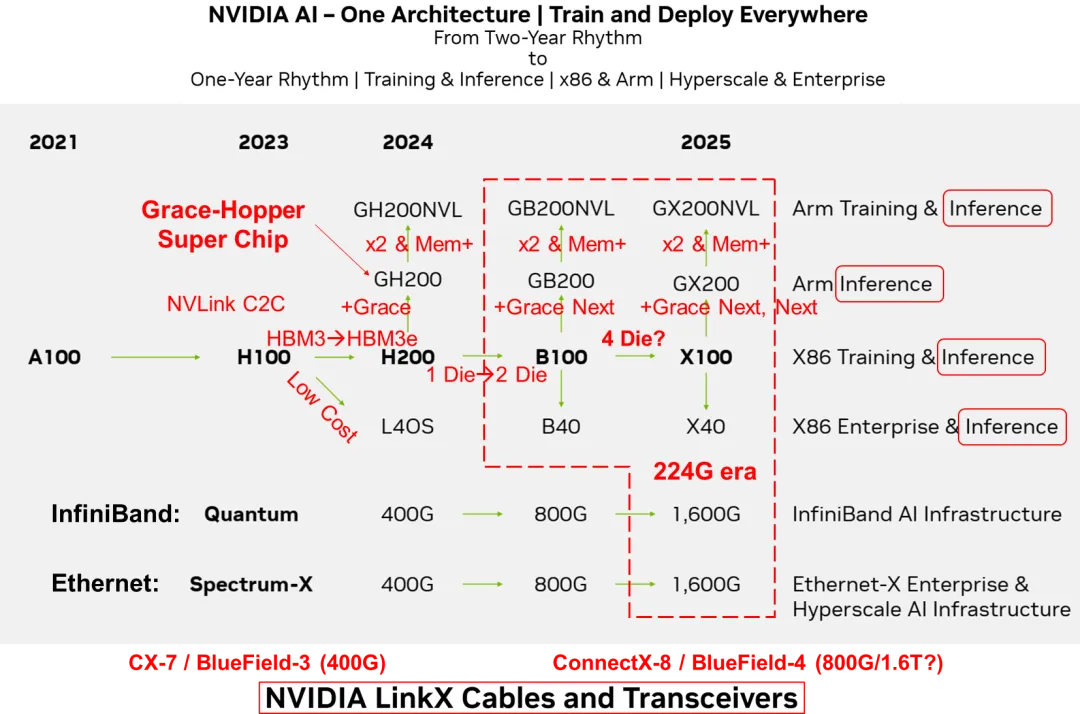
Roadmap overview
At its October 2023 investor meeting, Nvidia presented a revised GPU roadmap that shortens its previous two-year cadence to an annual update cycle. The strategic core is a unified "One Architecture" that is intended to support model training and deployment anywhere, whether in data centers or at the edge, and across both x86 and Arm hardware ecosystems. The product lineup covers both training and inference workloads, with consolidation of training and inference functions and an emphasis on inference. Target markets include hyperscale cloud operators and enterprise users.
Product and system strategy
Nvidia combines GPUs, CPUs, and DPUs in its compute and system lineup and uses NVLink, NVSwitch and NVLink C2C technologies to interconnect these components into unified hardware architectures. Together with CUDA, this forms a combined software and hardware ecosystem.
Architecture direction
The roadmap emphasizes integrating training and inference capabilities while prioritizing inference, and it follows two technical paths centered on GPUs for Arm and x86. Nvidia's Grace CPU is positioned as part of the Grace+GPU SuperChip roadmap. Grace CPUs are expected to evolve in step with GPUs and combine into next-generation SuperChips; they may also be configured as CPU-centric superchips to create differentiated two-to-one offerings. From a demand perspective, CPU evolution is less time-critical and more cost sensitive than GPU evolution. CPU performance can follow a Moore or system-Moore pace, with roughly a two-year performance doubling, while GPU compute performance is driven to increase much faster, approaching a multi-fold gain per year. This divergence has driven the emergence of SuperChips and supernode architectures.
Interconnects and supernode design
NVLink-C2C and NVLink remain central to Nvidia's SuperChip architecture. NVLink-C2C is used to construct GH200, GB200 and GX200 SuperChips. Using NVLink, two SuperChips can be back-to-back connected to form GH200NVL, GB200NVL and GX200NVL modules. NVLink networks enable the formation of supernodes, while InfiniBand or Ethernet networks can be used to build larger-scale AI clusters.
On switching, Nvidia continues to pursue two open routes: InfiniBand for AI factory deployments and Ethernet for AIGC cloud use cases. The roadmap does not provide a detailed plan for a standalone NVLink or NVSwitch ecosystem. The 224G SerDes generation may see early adoption on NVLink and NVSwitch. Nvidia's Quantum series (InfiniBand) and Spectrum-X series (Ethernet) are expected to continue incremental upgrades.
Switch and SerDes roadmap
Over multi-year cycles, SerDes lane rates typically double every 3 to 4 years, while switch capacity tends to double roughly every 2 years. Although the roadmap mentions a potential 800G upgrade for Quantum in 2024, the last public product is the 7 nm, 400G-interface, 25.6T Quantum-2 released in 2021. The roadmap does not list NVSwitch 4.0 or NVLink 5.0, but some analyses predict Nvidia may first adopt 224G SerDes in NVSwitch and NVLink. As proprietary interconnects, NVLink and NVSwitch are not bound by external standards and can be adjusted in timing and technical choices to achieve differentiation.
SmartNIC and DPU outlook
The next SmartNIC and DPU targets, typified by ConnectX-8 and BlueField-4, aim for 800G. How SmartNICs and DPUs will scale to match 1.6T-class Quantum and Spectrum-X switches remains unclear from the public roadmap. NVLink 5.0 and NVSwitch 4.0 could appear earlier in the interconnect stack.





