 ALLPCB
ALLPCB


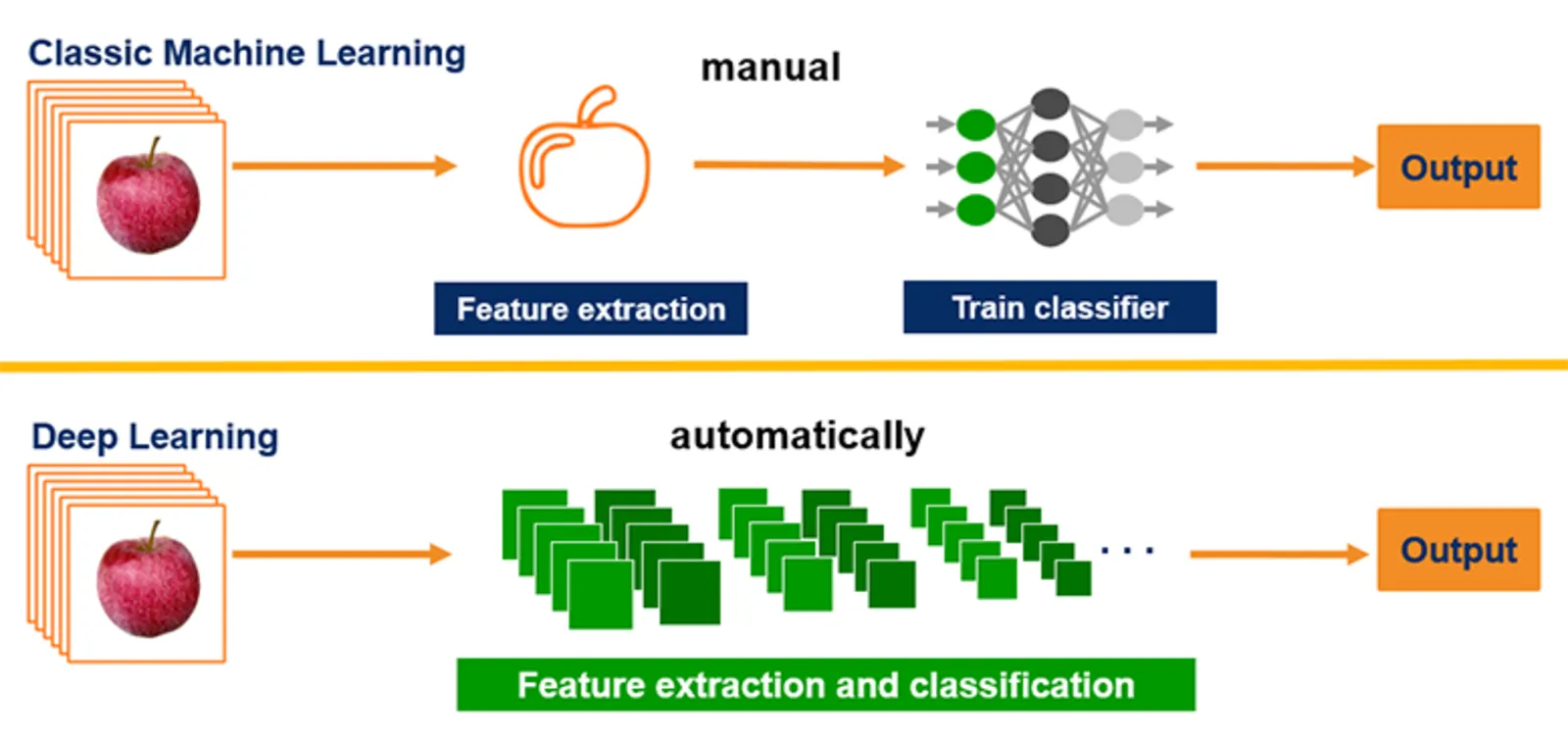
Overview
Deep learning now plays a central role across many fields, especially computer vision. Despite its successes, deep networks behave like black boxes: most practitioners and even trained researchers do not fully understand how they reach their decisions. One notable advantage of deep learning is its ability to automatically create features that humans might not anticipate. However, many success and failure cases have taught us valuable lessons about data handling. This article analyzes the strengths and limitations of deep learning, its relationship with classical computer vision, and potential risks when deep models are applied to critical tasks.
Simple and Complex Visual Tasks
At its core, a vision or computer vision problem can be framed like this: given an image captured by a camera, allow a computer to answer questions about the image content. Questions range from simple ones, such as "Is there a triangle in the image?" or "Is there a face in the image?", to more complex ones like "Is a dog chasing a cat in the image?" Although these problems may seem similar and trivial for humans, they hide significantly different levels of complexity.
Questions such as "Is there a red circle in the image?" or "How many bright spots are there?" are relatively straightforward. Other apparently simple questions like "Is there a cat in the image?" are far more challenging. The boundary between "simple" and "complex" visual tasks is often hard to define. For humans, a highly visual species, these questions are trivial, even for children. Deep learning systems, however, do not always answer them reliably.
Classical Computer Vision vs. Deep Learning
Classical computer vision is a collection of algorithms that extract information from images, typically treated as arrays of pixel values. These methods have many uses, including denoising, enhancement, and detection. Some techniques search for simple geometric primitives, such as edge detection, morphological analysis, Hough transforms, blob detection, corner detection, and various thresholding methods. Other approaches produce hand-crafted feature representations, for example histogram of oriented gradients, which can serve as input to machine learning classifiers to build more complex detectors.
Contrary to some opinions, combining these tools can produce efficient and accurate detectors for specific objects. Manually designed detectors can perform well for face detection, vehicle detection, and traffic sign detection, and in some cases they can match or outperform deep learning in terms of precision and computational complexity.
The main drawback is that each detector typically requires skilled engineers to design it from scratch, which is inefficient and costly. Historically, high-performing detectors have been developed only for objects that must be detected frequently and where the upfront investment is justifiable. Many such detectors are proprietary and not publicly available, for example commercial face detectors and license plate readers. It is unlikely that someone would invest resources to handcraft a detector for every possible object class, such as dog breed classification. This is where deep learning becomes useful.
A Cautionary Classroom Example
Imagine a computer vision course where the first part of the term covers classical techniques, and students are assigned tasks that involve collecting images and asking questions about them. Early tasks might ask whether a shape is a circle or square, progressing to more complex tasks such as distinguishing cats from dogs. Students submit code weekly, and the instructor runs and inspects the results.
One quiet student submits code that is hard to understand. It looks like random filters are being convolved over images, followed by unusual logic to produce the final answer. The code performs surprisingly well. As tasks grow more difficult, this student continues to submit increasingly complex but highly effective code. On a final assignment to distinguish cats from dogs on a real image set, most students achieve no better than 65% accuracy, while this student's solution reaches 95%.
After reverse engineering the solution, the instructor discovers that the program detects dog tags. If a tag is found, it checks the color of the lower part of the object and returns "cat" or "dog" based on that heuristic. If no tag is found, it applies other color-based checks. When confronted, the student admits that the solution solved the dataset's task but does not represent an understanding of what a dog looks like or the real differences between cats and dogs.
This example illustrates that a model can succeed on a dataset by exploiting dataset-specific cues rather than learning semantically meaningful features. The solution is effective, but it does not align with the intended objective.
Blessing and Curse of Deep Learning
Deep learning uses optimization techniques such as gradient backpropagation to produce "programs" in the form of neural networks. These programs are optimized only to map inputs to correct labels on a training set. With millions of parameters and thousands of implicit condition checks, backpropagation can produce very large and complex models that latch onto subtle combinations of biases present in the training data. Any statistical signal that correlates with the target labels can be exploited, regardless of whether it aligns with the task's semantic intent.
Although networks can, in principle, learn semantically correct priors, extensive evidence shows that this is not guaranteed. Small, imperceptible changes to an image can alter a detector's output, and generalization to new examples outside the training distribution is often much weaker than within it. In some cases, changing a single pixel can alter a deep network's classification. The same ability that enables deep networks to discover unexpected features is also their weakness: many learned features appear, at least semantically, of dubious relevance.
When Deep Learning Makes Sense
Deep learning is a valuable addition to computer vision. It allows training detectors for objects that would be impractical to design by hand, and these detectors can be scaled with additional compute. However, this capability comes at a cost: the decision-making process is often not interpretable, and the basis for classification may be unrelated to the task's intended semantics. Detectors can fail when input data violates low-level biases present in the training set, and the failure modes are not yet well understood.
In practice, deep learning is useful for applications where occasional errors are tolerable and where inputs are unlikely to differ significantly from the training data. Examples include image search, surveillance, automated retail, and most non-critical tasks that can tolerate error rates on the order of a few percent.
Ironically, many view deep learning as revolutionary for application domains where errors are consequential and real-time decisions matter, such as autonomous driving and autonomous robots. Recent research shows that deep neural networks used in driving systems can be vulnerable to adversarial attacks in the real world. This suggests that applying deep models to safety-critical systems requires extreme caution.
There is also concern about medical and diagnostic applications: models trained on data from one institution may not generalize well to another, reinforcing the view that these models often learn shallower signals than researchers expect.
Data Is Shallower Than We Thought
An unexpected lesson from deep learning is that visual data, although high dimensional, can be statistically separated by many more methods than previously assumed. Low-level image features carry more statistical signal correlated with high-level human labels than we had believed. In other words, sets of low-level features can be surprisingly informative. How to construct methods that reliably separate visually meaningful categories in a semantically principled way remains an open and difficult question.
Conclusion
Deep learning has become an important component of modern computer vision systems. Classical computer vision has not disappeared and remains useful for building powerful, hand-crafted detectors that rely on semantically meaningful input features. While such detectors may not always match deep models on some dataset metrics, they can provide guarantees about which input features drive decisions.
Deep learning offers statistically powerful detectors without manual feature engineering, but it requires large labeled datasets, substantial computational resources such as GPUs, and expertise in deep learning. These detectors can suffer unexpected failures because their domain of applicability is difficult, if not impossible, to concisely describe. Combining deep learning with feature engineering and logical reasoning can produce useful capabilities across a wide range of automation problems.





