ALLPCB
ALLPCB


Overview
Large AI models are advancing at an unprecedented pace and driving the emergence of an intelligent world. Compute, algorithms, and data form the three core elements of AI. While compute and algorithms are the tools of the large model era, the scale and quality of data determine the ultimate capabilities of AI. Data storage transforms information into corpora and knowledge bases, and together with compute it is becoming a foundational infrastructure for large AI models.
This article is adapted from "Toward an Intelligent World: White Paper 2023". Reliable, high-performance, and shareable data storage is becoming the preferred data foundation for databases represented by Oracle. Looking ahead, enterprise data storage faces the following trends:
- Large AI models require more efficient large-scale raw data collection and preprocessing, higher-performance training data loading and model persistence, and more timely and accurate domain-specific inference knowledge bases. New AI data paradigms such as near-data computing and vector storage are growing rapidly.
- Big data applications are evolving from historical reporting and trend prediction toward real-time assisted precision decision-making and intelligent decision-making. Data paradigms like near-data computing will substantially improve the analytics efficiency of unified lakehouse platforms.
- Open-source distributed databases are taking on increasingly critical enterprise workloads, and new high-performance, high-reliability architectures that combine distributed databases with shared storage are emerging.
- Multi-cloud is becoming the new normal for enterprise data centers, with on-premises data centers and public clouds forming an effective complement. Cloud deployment is shifting from closed full-stack models to open, decoupled models to enable multi-cloud application deployment and centralized sharing of data and resources.
- Large AI models aggregate massive amounts of enterprise private data, increasing data security risks. Building a comprehensive data security system, including storage-native security, is urgent.
- Large AI models are driving data center compute and storage architectures from CPU-centric designs toward data-centric systems, requiring new system architectures and ecosystems.
- AI technologies are increasingly integrated into storage products and management, improving storage infrastructure SLA levels.
1. Large AI Models
The development of AI has exceeded expectations. At the end of 2022, when OpenAI released ChatGPT, no one anticipated the rapid societal changes that large AI models would bring.
In the large model era, storage as the primary carrier of data must evolve in three key areas: governance of massive unstructured data, a 10x performance improvement, and storage-native security. Beyond exabyte-scale extensibility, storage must meet bandwidths on the order of hundreds of GB/s and tens of millions of IOPS to achieve more than a tenfold performance improvement.
Enterprises using large AI models, HPC, and big data require rich raw data from the same sources: production and transaction logs, research experiment data, and user behavior data. Therefore, building large models with the same data sources and architecture as HPC and big data is the most efficient approach, enabling a single dataset to serve different environments.
All-flash storage can deliver significant performance gains and accelerate model development and deployment. Data-centric architectures enable decoupling and interconnection of hardware resources, accelerating data movement on demand. Emerging techniques such as data fabric, vector storage, and near-data computing reduce the barrier for enterprises to integrate and use data, improve resource utilization, and lower the difficulty of adopting large AI models. Storage-native security protects core private data assets and enables safer use of large AI models.
2. Big Data
Big data applications have evolved through three stages: traditional historical reporting, predictive analytics, and proactive decision-making.
Traditional data warehouse era: Enterprises built subject-oriented, time-variant datasets in data warehouses to accurately describe and aggregate historical data for analytics and decision support, typically handling structured data at the TB scale.
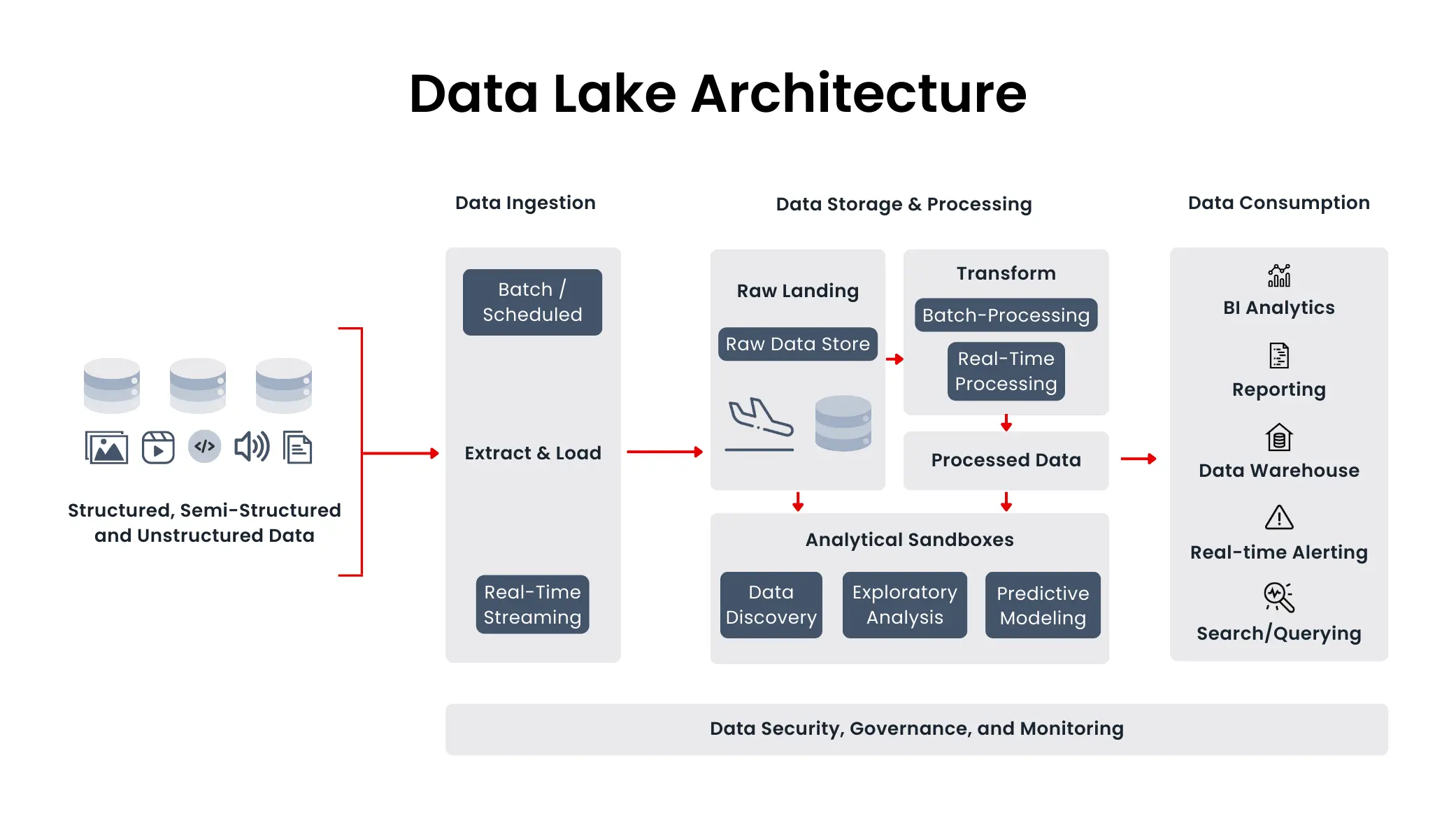
Traditional data lake era: Enterprises used Hadoop-based data lakes to process structured and semi-structured data and to predict future trends from historical data. This phase produced a "siloed" architecture where data flowed between the data lake and data warehouse, preventing real-time and proactive decision-making.
Lakehouse era: Enterprises have sought real-time and proactive decision solutions by optimizing the IT stack and moving toward unified lakehouse architectures. A key initiative is collaboration with storage vendors to decouple compute and storage in the big data IT stack so that data lake storage can serve both data lake and data warehouse use cases without moving data between them, enabling real-time and proactive decisions.
3. Distributed Databases
Open-source databases MySQL and PostgreSQL occupy the top positions in the global database market. Open-source databases are reconstructing enterprise core systems. To ensure stable business operations, the compute-storage separation architecture for distributed databases is becoming the de facto standard.
Major global banks have adopted compute-storage separation architectures to build new core systems. New distributed database products such as Amazon Aurora, Alibaba PolarDB, Huawei GaussDB, and Tencent TDSQL have shifted their architectures toward compute-storage separation, which has become a standard practice in distributed database deployments.
4. Cloud-native and Multi-cloud
Enterprise cloud infrastructure has moved from single-cloud to multi-cloud architectures. No single cloud can satisfy all application and cost requirements, so many enterprises adopt multiple public and private clouds.
Key multi-cloud infrastructure capabilities can be grouped into two categories. The first enables data mobility across clouds, such as cross-cloud tiering and cross-cloud backup, allowing data to reside on the most cost-effective storage service. The second is cross-cloud data management, which gives users a global data view and enables orchestrating data to the applications that generate the most value.
Open, decoupled architectures let hardware resources be shared across multiple clouds and enable on-demand data movement between clouds, realizing the full benefits of multi-cloud deployments.
From hardware and platforms to applications, the best services often come from different vendors. Open, decoupled construction lets enterprises assemble an optimal IT stack. For AI, leading large-model providers such as OpenAI and Meta do not match the hardware infrastructure capabilities of vendors like NVIDIA, DDN, or major IT vendors. No single vendor can provide an end-to-end optimal AI training and inference solution, so enterprises building their AI clusters tend to choose open, decoupled architectures and select the best hardware and models.
5. Unstructured Data
With the rapid development of 5G, cloud computing, big data, AI, and high-performance data analytics, enterprise unstructured data is growing quickly—video, voice, images, and documents are expanding from PB to EB scales. For example, a single genome sequencer can generate 8.5 PB per year; a large telecom operator may process 15 PB per day; a remote sensing satellite can collect 18 PB per year; and an autonomous driving training vehicle can produce 180 PB per year.
First, data must be stored cost-effectively: store more data with the lowest cost, minimal floor space, and minimal power consumption.
Second, data must be mobile: data within and between data centers must flow efficiently according to policies.
Finally, data must be usable: mixed workloads such as video, audio, images, and text must meet application requirements.
6. Storage-native Security
As data becomes the foundation of AI, its importance grows and data security is critical to protecting enterprise assets. According to Splunk's "State of Security 2023" report, over 52% of organizations experienced data breaches from malicious attacks and 66% faced ransomware attacks, indicating a rising importance of data security.
Data generation, collection, transmission, use, and disposal all involve storage devices. As the final carrier and "safe deposit box" for data, storage systems offer near-data protection capabilities and control near media, playing an irreplaceable role in data security protection, backup and recovery, and secure data disposal.
Storage-native security strengthens storage security through inherent architecture and design. It comprises two aspects: the intrinsic security capabilities of storage devices and the data protection capabilities for the stored data.
7. All-scenario Flash
By 2022, SSD market share and shipments exceeded those of HDDs by more than twofold, accounting for over 65% of the market. Enterprises are moving toward an all-flash era.
The NAND die, the core component of enterprise SSDs, largely determines cost. Improvements in 3D NAND layer count and the adoption of QLC dies have driven down all-flash material costs. Mainstream manufacturers now produce 3D NAND with layer counts up to 176 layers and roadmaps over 200 layers, nearly doubling since 2018. Regarding die types, TLC has become the mainstream choice for enterprise SSDs, and QLC SSDs have also appeared.
.
8. Data-centric Architectures
AI and real-time analytics are driving heterogeneous compute beyond CPUs to diverse combinations of CPU, GPU, NPU, and DPU.

As AI and big data demand higher performance and lower latency while CPU performance growth slows, server architectures are evolving toward composable designs. Storage architectures will follow, becoming data-centric composable systems to greatly improve storage performance. Diverse storage processors (CPU, DPU), memory pools, flash pools, and capacity pools will interconnect via new data buses so that incoming data can be placed directly into memory or flash, avoiding CPUs as a data access bottleneck.
9. AI-enabled Storage
AI can predict trends for performance, capacity, and spare-part failures to reduce the likelihood of anomalies. In complex incident-response scenarios, storage management systems augmented with large AI models can rapidly improve interaction logic and assist operators in diagnosing issues, significantly shortening mean time to repair.
10. Green and Energy-efficient Storage
Under carbon peak and neutrality goals, green and low-carbon data centers are an important direction. Storage accounts for over 30% of data center energy consumption. Beyond lowering PUE, reducing IT equipment energy—particularly storage—is vital for achieving zero-carbon data centers.
Consolidating protocols and eliminating silos enables multi-function systems and improves resource utilization. A single storage system that supports file, object, HDFS, and other protocols can meet diverse workloads and consolidate storage types. Pooling resources increases utilization efficiency.
About 83% of storage energy consumption comes from storage media. For the same capacity, SSDs consume about 70% less power and occupy about 50% less space than HDDs. Using high-capacity SSDs and high-density enclosures increases capacity per watt and reduces per-unit energy consumption, storing more data in less space.