 ALLPCB
ALLPCB


Overview
ByteDance and a research team from Peking University recently published a paper titled "Scaling Large Language Model Training Beyond 10,000 GPUs", describing a production system for training large language models that addresses efficiency and stability challenges on clusters with more than 10,000 GPUs. The paper details the system design, implementation, and deployment, and discusses problems encountered and solutions at that scale.
Two key challenges at 10,000-GPU scale
Training large models requires massive compute resources. Model size and training data volume are primary factors determining model capability. Major industry players build clusters of tens of thousands of GPUs to train LLMs. At the 10,000-GPU scale, two central challenges arise.
First, achieving highly efficient training at large scale. Model floating-point utilization (MFU), defined as actual throughput divided by peak theoretical throughput, is a common metric for training efficiency and reflects end-to-end training speed. Training LLMs requires partitioning the model across many GPUs, which incurs substantial communication. Beyond communication, operator optimizations, data preprocessing, and GPU memory usage also significantly affect MFU.
Second, maintaining high stability across large-scale training. Failures and delays are common in large-model training, but their cost is high. Reducing recovery time is critical because a single slow or failed node can slow the entire multi-thousand-GPU job.
To address these issues, ByteDance developed the MegaScale system and deployed it in its data centers. The following sections summarize the techniques used to improve efficiency and stability.
How to achieve efficient large-model training
Meeting sharply increased compute demands without harming model quality requires state-of-the-art algorithmic optimizations, communication strategies, data pipeline management, and network tuning. The paper explores these methods for optimizing large-model training at scale.
Algorithmic optimizations
Algorithm-level changes improve training efficiency without impacting accuracy. Key techniques include parallel transformer blocks, sliding window attention (SWA), and the LAMB optimizer.
Parallel transformer blocks: A parallel version of transformer blocks replaces serialized computation so that attention and MLP blocks can execute in parallel, reducing compute time. Prior work shows this modification does not reduce quality for models with hundreds of billions of parameters.
Sliding window attention (SWA): SWA is a sparse attention mechanism that applies a fixed-size window around each token instead of full self-attention. By stacking windowed attention layers, the model captures broad context while creating a large receptive field, accelerating training without degrading accuracy.
LAMB optimizer: Large-batch training is often limited by batch-size-related convergence issues. The LAMB optimizer enables scaling BERT training to batch sizes of 64K without harming accuracy.
Communication overlap in 3D parallelism
3D parallelism here refers to tensor parallelism, pipeline parallelism, and data parallelism.
Data parallelism requires two main collective operations: all-gather and reduce-scatter. In 3D parallelism, a single device may host multiple model shards. Overlap is implemented per shard to maximize bandwidth utilization. All-gather is triggered before a shard's forward pass, and reduce-scatter starts after its backward pass. This leaves the first all-gather and the last reduce-scatter unhidden. Inspired by PyTorch FSDP, initial all-gather operations are prefetched at the start of each iteration to overlap with data loading, effectively reducing communication time.
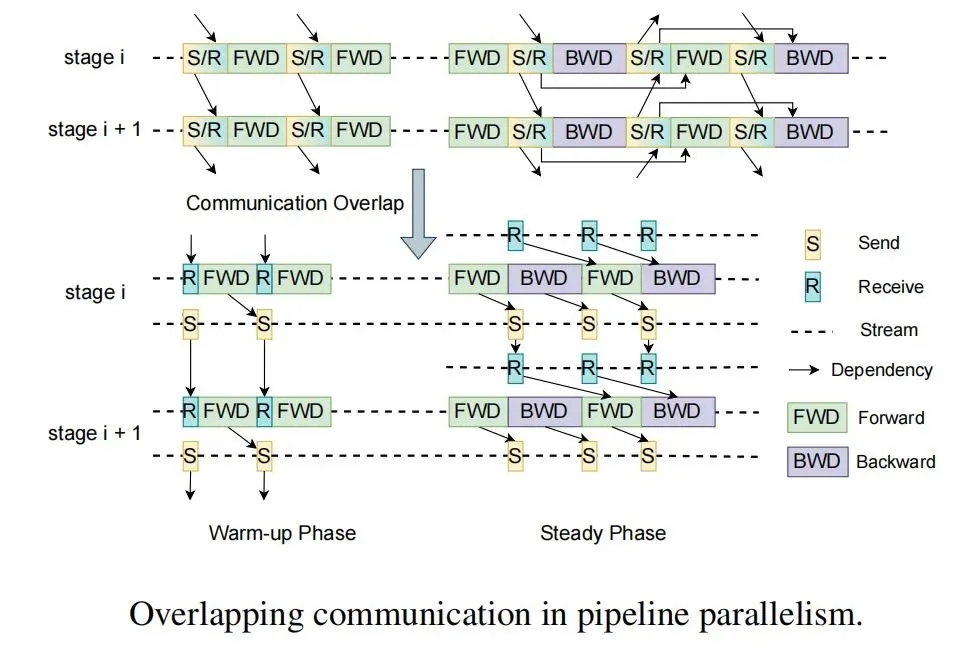
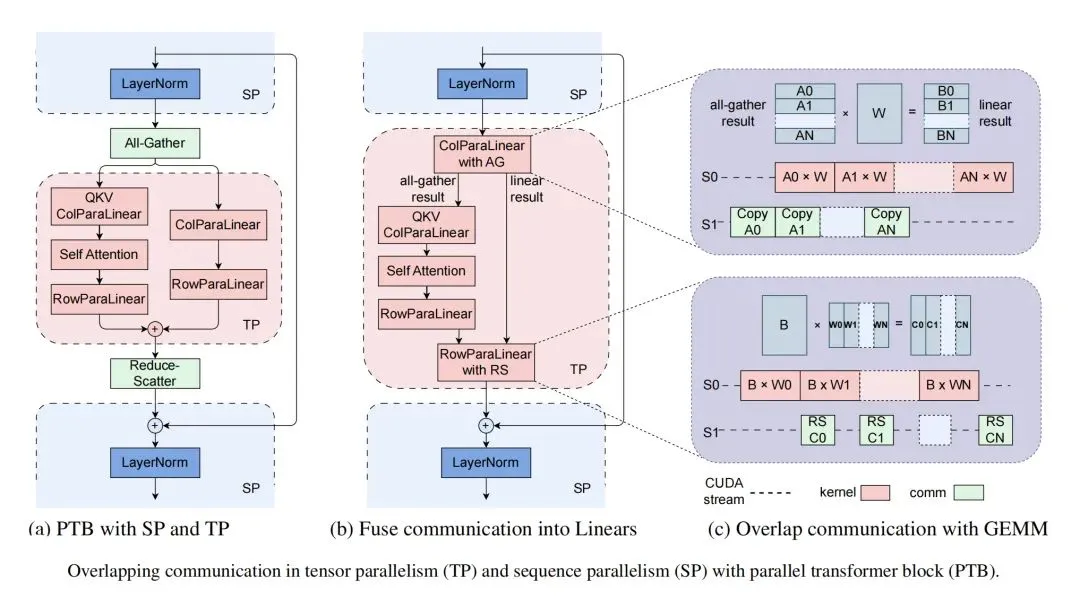
In pipeline parallelism, MegaScale uses an interleaved 1F1B schedule to overlap communication. During warmup, forward passes depend only on prior receives. The design decouples send and receive, allowing send operations to overlap with computation. For tensor/sequence parallelism, the paper describes fused communication-computation strategies and splitting GEMM kernels into tiles that are pipelined with communication.
Efficient operators
Although Megatron-LM optimizes GEMM, other operators offer further gains. The attention module uses FlashAttention-2, which improves work distribution across thread blocks and warps. LayerNorm and GeLU were previously implemented as fine-grained kernels; fusing these kernels reduces kernel launch overhead and improves memory access patterns, yielding better performance.
Data pipeline optimizations
Data preprocessing and loading are often overlooked but cause nontrivial GPU idle time at step boundaries. Optimizing these stages is essential for overall efficiency.
Asynchronous data preprocessing: Preprocessing is moved off the critical path so that, while GPUs synchronize gradients at the end of a step, preprocessing for subsequent steps can start and hide preprocessing overhead.
Eliminating redundant data loaders: Typical distributed setups assign a data loader per GPU worker, reading data into CPU memory and forwarding it to GPUs. This creates contention for disk bandwidth. Observing that GPU workers on the same machine often belong to the same tensor-parallel group and require identical inputs each iteration, MegaScale uses a two-level tree approach: one dedicated loader per machine reads data into shared memory, and each GPU worker copies the required data into its GPU memory. This eliminates redundant reads and significantly improves transfer efficiency.
Collective communication group initialization
Initializing NCCL communication groups among GPU workers incurs overhead. For small scales, torch.distributed is sufficient, but at scales beyond 10,000 GPUs, naive initialization overhead becomes unacceptable.
Long torch.distributed initialization time stems from two issues. First, a synchronization step uses a TCPStore-based barrier with single-threaded blocking read/writes. Replacing TCPStore with a nonblocking, asynchronous Redis reduces this overhead. Second, excessive use of global barriers—where each process performs a global barrier after initializing its groups—adds latency. By carefully designing the initialization order of communication groups, the number of global barriers and time complexity are reduced.
Without these optimizations, initializing a 2,048-GPU cluster took 1,047 seconds; after optimization it drops below 5 seconds. Initialization time for a 10,000+ GPU cluster can be reduced to under 30 seconds.
Network performance tuning
The team analyzed inter-machine traffic in 3D parallelism and designed techniques to improve network performance, covering topology design, reduction of ECMP hash collisions, congestion control, and retransmission timeout tuning.
Network topology: The data center network is built on Broadcom Tomahawk 4 switches. Each Tomahawk chip provides 25.6 Tbps with 64×400 Gbps ports. A three-layer, CLOS-like topology connects over 10,000 GPUs. Downlink and uplink bandwidth per layer are provisioned 1:1, e.g., 32 ports down and 32 ports up, providing low-diameter, high-bandwidth connectivity so nodes communicate within few hops.
Reducing ECMP hash collisions: The topology and flow scheduling were designed to reduce ECMP hash collisions. At the rack ToR, uplink and downlink ports are split; a 400G downlink port is broken into two 200G downlinks via a specific AOC cable, which lowers collision rates.
Congestion control: Using default DCQCN at large scales can cause all-to-all patterns to trigger congestion and increase PFC usage, which risks head-of-line blocking and reduced throughput. The team developed an algorithm combining principles from Swift and DCQCN that pairs precise RTT measurement with ECN-based fast congestion response. This approach improves throughput while minimizing PFC-related congestion.
Retransmission timeout tuning: NCCL parameters controlling retransmission timers and retry counts were tuned for fast recovery during link jitter. Additionally, the NIC feature ad_ap_retrans was enabled to allow retransmits at shorter intervals, helping quicker recovery when jitter cycles are short.
Fault tolerance
As clusters scale to tens of thousands of GPUs, software and hardware faults become inevitable. The system implements a robust training framework with automatic fault detection and fast recovery to minimize operator intervention and training impact.
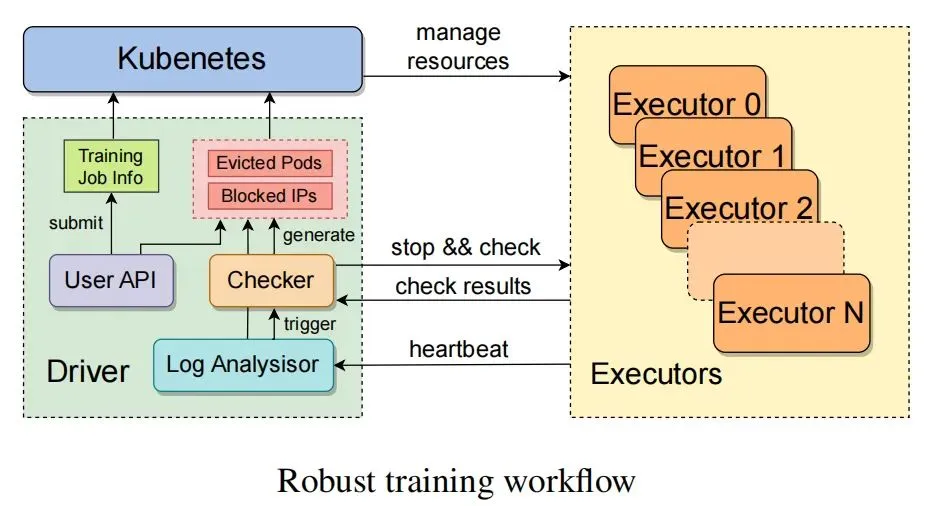
Upon receiving a training job, a driver process interacts with a custom Kubernetes interface to allocate compute resources and launch pods for each executor. Each executor manages a node. After initialization, the executor spawns training processes on each GPU and starts a resilient training daemon that sends periodic heartbeats to the driver for real-time anomaly detection. When an anomaly is detected or a status report is missed, a recovery routine pauses ongoing training tasks and triggers self-diagnostic checks.
When a faulty node is identified, the driver submits the node IPs and pod information to Kubernetes for eviction, and healthy nodes replace the failed ones. A UI allows manual removal of problematic nodes. After recovery, the driver resumes training from the latest checkpoint. Checkpointing and recovery were optimized to minimize lost training progress.
A millisecond-resolution monitoring system was developed to improve stability and performance observability. Multi-level monitoring tracks various metrics to support fast troubleshooting, checkpoint recovery, and root-cause analysis during MegaScale deployments. The paper is available for download.
Conclusion
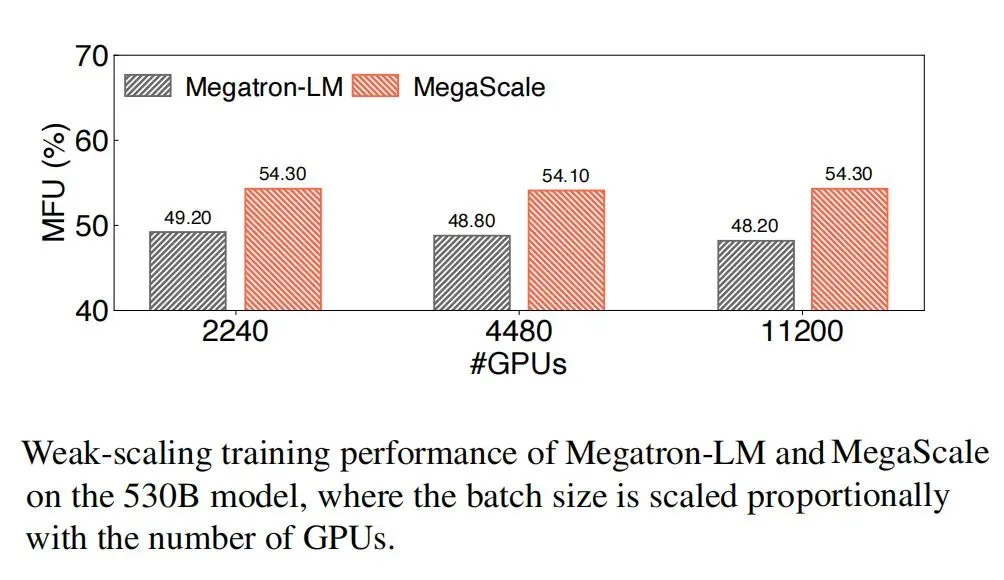
The paper describes the design, implementation, and deployment of MegaScale. Through algorithm-system co-design, MegaScale optimizes training efficiency. On 12,288 GPUs training a 175B LLM, MegaScale achieved 55.2% MFU, a 1.34× improvement over Megatron-LM.
The system emphasizes fault tolerance across training and implements a custom robust training framework for automatic detection and repair. A comprehensive monitoring toolset provides deep visibility into system components and events to facilitate root-cause identification of complex anomalies. The work offers practical insights for LLM training and informs future research in large-scale model training.





