 ALLPCB
ALLPCB


Overview
Using cluster resources to improve performance is well established. The Beowulf project showed that commodity hardware can deliver high performance. The idea of a "Beowulf cluster" is often invoked when deploying a new technology. Recent announcements from GigaIO and TensorWave bring that concept closer to practical reality.
SuperNODE and recent developments
GigaIO introduced a 32-GPU single-node system, SuperNODE, in June. SuperNODE won two HPCwire Editor's Choice awards at the 2023 Supercomputing Conference in Denver. HPCwire reported on the performance of the 32-GPU SuperNODE and the 64-GPU SuperDuperNODE. GigaIO and TensorWave are now advancing toward creating larger, Beowulf-style GPU clusters.
TensorNODE project
GigaIO announced that SuperNODE received a major order that will ultimately deploy tens of thousands of AMD Instinct MI300X accelerators, which AMD unveiled at its Advanced AI event. GigaIO's infrastructure will serve as the backbone of a bare-metal AI cloud called TensorNODE, built by cloud provider TensorWave to provide access to AMD data center GPUs for large language model workloads.
Matt Demas, GigaIO global sales CTO, said the company used SuperNODE to build a large cluster for TensorWave. Each SuperNODE includes two additional servers and can access the GPU memory across the entire TensorNODE. Each TensorNODE also includes a substantial amount of staging disk capacity.
Architecture and memory fabric
TensorNODE deployments will be based on the GigaIO SuperNODE architecture at larger scale, using GigaIO's PCIe Gen-5 memory fabric to simplify workload setup and deployment compared with traditional networks and to reduce related performance overhead.
TensorWave plans to use GigaIO's FabreX to create the first petabyte-scale GPU memory pool without the performance penalties of non-memory-centric networks. The initial TensorNODE products are expected to begin operating in early 2024. The architecture is designed to support up to 5,760 GPUs within a single FabreX storage domain. Because all GPUs in the domain can access the VRAM of all other GPUs in the domain, extremely large models can be run. Workloads can access more than a petabyte of VRAM within a single job from any node, enabling very large jobs to complete more quickly. Multiple TensorNODE deployments are planned through 2024.
Hardware and scaling
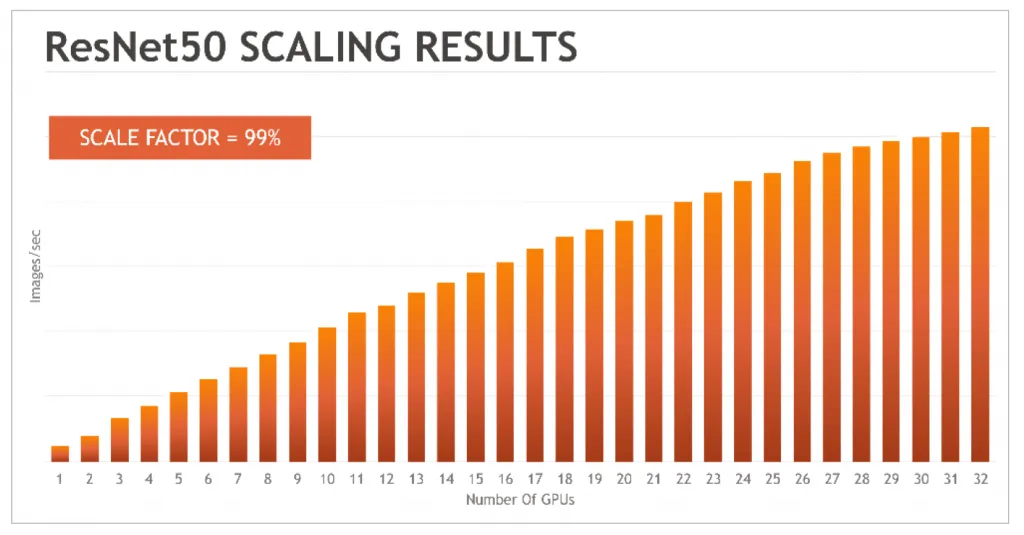
TensorNODE is a full AMD solution, using fourth-generation AMD CPUs and MI300X accelerators. Each MI300X accelerator provides 192 GB of HBM3, supporting the expected TensorNODE performance. The accelerators' memory capacity combined with GigaIO's memory fabric aims to achieve near-linear scaling with minimal performance loss, addressing underutilization or idle GPU cores that can occur with distributed memory models.
Provider perspective and composability
TensorWave stated it selected the GigaIO platform for its capabilities and for alignment with open standards. TensorWave intends to use this infrastructure to support large-scale AI workloads and to be among the first cloud providers to deploy MI300X accelerators.
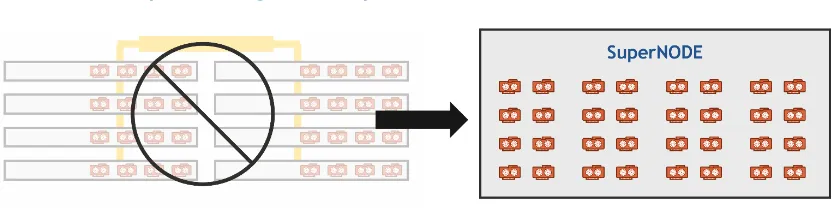
GigaIO's composable and dynamic infrastructure provides TensorWave flexibility and agility. As LLM and AI demand evolves, the infrastructure can be reconfigured to meet current and future needs. TensorWave's architecture eliminates the need for traditional GPU server hosts (typically 4–8 GPUs per server) and associated networking equipment, which reduces cost, complexity, and resource use such as space, cooling water, and power.
Validation and outlook
GigaIO said that combining AMD Instinct MI300X accelerators with GigaIO's AI infrastructure, including the FabreX memory fabric, supports large-scale deployments such as TensorWave's. The deployment serves as a validation of their approach to rethinking data center infrastructure. GigaIO also noted TensorWave's experience in building and deploying complex accelerated data centers.
Given generative AI models' memory requirements, the large memory capacity and bandwidth from GigaIO and AMD are likely to make TensorWave's TensorNODE attractive to cloud customers building and delivering AI solutions.





