 ALLPCB
ALLPCB


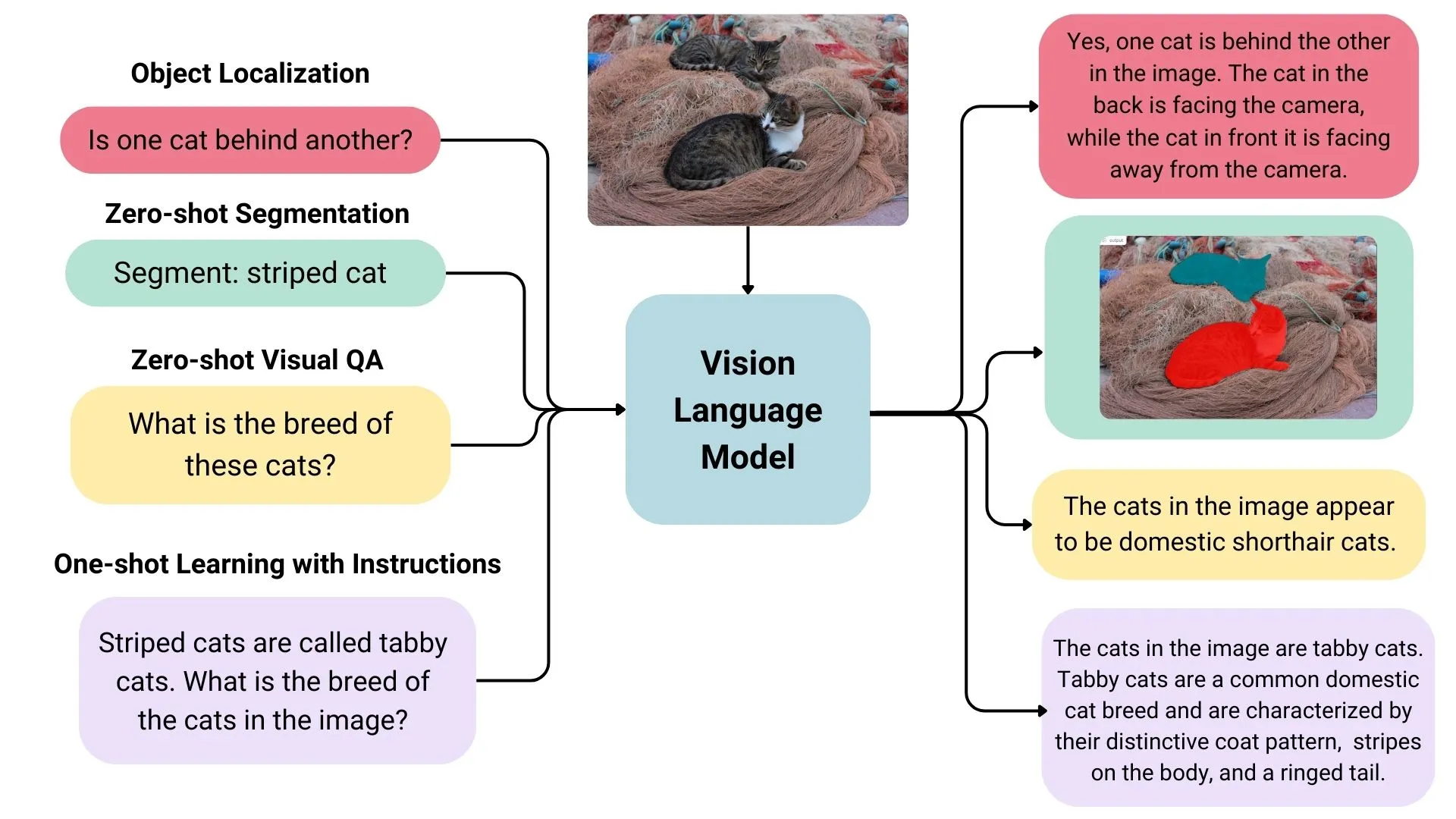
Overview
Visual-language models (VLMs) such as GPT-4V have recently made significant progress on many vision-language tasks. This work examines a more complex and less-studied area: vision-based deductive reasoning. Using Raven's Progressive Matrices (RPMs), the study evaluates VLMs' ability to perform multi-hop relational and deductive reasoning relying only on visual cues. The authors find blind spots in state-of-the-art VLMs and show that approaches effective for text-only reasoning do not always transfer to visual reasoning. Detailed analysis indicates that VLMs struggle because they fail to perceive and interpret multiple confounding abstract patterns in RPM examples.
Objective
The paper aims to evaluate and diagnose current state-of-the-art VLMs on challenging visual deductive reasoning tasks. Specifically, it uses RPM problems to test whether VLMs can infer rules from visual patterns and apply those rules to select the correct missing option, relying only on visual information.
Related Work
Relevant prior work spans several areas:
- LLM reasoning benchmarks: Multiple text-based reasoning tasks and benchmarks have been introduced to evaluate large language models (LLMs) across domains such as commonsense, mathematical reasoning, factual recall, and programming. Examples include BIG-bench, HELM, SuperGLUE, and LAMA.
- Visual reasoning evaluation: Prior work has focused on tasks like visual question answering and image captioning, which involve answering questions about images or generating natural language descriptions. Datasets such as CLEVR and SHAPES evaluate counting, comparison, logical reasoning, and memory-related visual skills.
- Deductive reasoning: Both text and vision domains have benchmarks for deductive reasoning. Tasks like GuessWhat?! and ReferIt assess visual reasoning. Newer benchmarks such as LMRL Gym and Entity Deduction Arena evaluate multi-step deductive capabilities in LLMs. ARC tasks are similar to RPMs in requiring inference of unseen outputs from given examples.
- VLM development: As VLMs have advanced, benchmarks have diversified. New datasets such as MMMU and MathVista test scene and object understanding in images and videos, covering scene text, formulas, chart interpretation, visual stimulus understanding, geometric and spatial reasoning, and facial expression reasoning.
Approach
The paper addresses visual deductive reasoning through a systematic evaluation framework:
- Evaluation framework: The authors build a framework to evaluate VLMs on RPM problems. They select diverse datasets, including the Mensa IQ test, IntelligenceTest, and RAVEN, and evaluate several popular open-source and closed-source VLMs.
- Standard strategies: They apply strategies that are effective in LLMs, such as in-context learning and self-consistency, to explore their usefulness in VLMs.
- Capability decomposition: VLM performance is decomposed into perception, deductive reasoning, and hypothesis verification to diagnose bottlenecks. The analysis highlights perception as a primary limitation and provides a case study exposing specific blind spots even in strong VLMs like GPT-4V.
- Error and sensitivity analysis: The authors identify issues including overconfidence, sensitivity to prompt design, and poor use of contextual examples. Ablation experiments examine the impact of different prompt formats and find that more structured prompts can benefit model performance.
- Experimental details: The paper documents datasets, compared models, and prompt methods used to generate responses.
- Results and analysis: The authors report model performance across datasets, analyze prediction uncertainty, and evaluate the effectiveness of standard strategies on visual deductive tasks.
Experiments
Key experimental components include:
- Dataset evaluation: Three RPM datasets are used—Mensa IQ test, IntelligenceTest, and RAVEN—covering varied difficulty levels and visual patterns.
- Model comparison: Multiple leading VLMs are compared, including GPT-4V, Gemini Pro, Qwen-VL-Max, and LLaVA-1.5-13B.
- Reasoning strategies: In-context learning and self-consistency are evaluated to see if they improve VLM reasoning.
- Perception tests: Models are evaluated on their ability to describe RPM images accurately and to recognize underlying patterns.
- Deductive reasoning with oracle descriptions: The authors test whether providing correct textual descriptions improves reasoning performance.
- Hypothesis verification: The study measures whether models can generate and validate hypotheses after receiving correct descriptions and rationales.
- Prompt structure impact: The influence of prompt organization, such as image-text ordering, on model predictions is investigated.
- Error-handling: Models are tested on whether they can reason effectively when given incorrect self-generated text descriptions.
Findings
- VLMs lag behind LLMs on complex deductive reasoning when visual perception is required. Text-based reasoning capabilities do not directly imply comparable visual reasoning ability.
- Strategies effective for LLMs are not consistently effective for VLMs on RPM tasks.
- Perception is the primary bottleneck: VLMs often fail to detect and represent multiple abstract visual patterns simultaneously.
- Models show overconfidence and sensitivity to prompt structure, and they do not reliably use contextual examples.
- Structured prompts and providing correct descriptions can help, but limitations remain in perception and hypothesis verification stages.
Future Directions
- Training data improvements: VLMs are often trained on real-world images, which may reduce sensitivity to abstract patterns. Fine-tuning on more diverse RPM-like data could improve pattern recognition.
- Contrastive and reinforcement learning: Exploring contrastive learning or reinforcement learning algorithms may help models better learn and reason about visual patterns.
- Integrating perception and reasoning: When tasks require complex spatial layouts and relational reasoning, textual information alone may be insufficient. Investigating better integration of visual cues and text could yield improvements.
- Prompt structure optimization: Given VLM sensitivity to prompt design, further work on structured and robust prompting could raise performance on visual reasoning tasks.
- Uncertainty calibration: Models often produce confident answers even when uncertain. Improving calibration so models express uncertainty more accurately is a potential direction.
- Generalization: RPM tasks require strong generalization. Future research should explore improving few-shot generalization for visual deductive tasks.
- Explainability: Models sometimes produce incorrect explanations. Enhancing explanation quality and alignment with visual cues is an open area.
Summary
This paper evaluates VLMs on RPM-style visual deductive reasoning and identifies key limitations. While VLMs have advanced on many vision-language tasks, they remain substantially behind human-level performance on abstract visual reasoning that requires perception of multiple interacting patterns. The study decomposes VLM capabilities into perception, deductive reasoning, and hypothesis verification, showing perception as the dominant bottleneck. The authors test common LLM strategies and provide analyses and suggestions for future work, including data diversification, learning algorithm advances, better integration of vision and language, prompt design, uncertainty calibration, and explainability improvements.





