 ALLPCB
ALLPCB


Overview
This article explains why state-of-the-art deep neural networks can still recognize heavily corrupted images and how that reveals that DNNs often rely on unexpectedly simple strategies to classify natural images. An ICLR 2019 paper highlighted these findings and showed how they simplify ImageNet classification, making it possible to build more interpretable image classification pipelines and explaining phenomena observed in modern CNNs, such as texture bias and insensitivity to spatial arrangement of object parts.
Retro bag-of-features models
Before deep learning, object recognition in natural images often used a simple approach: define a set of visual features or "words", count their occurrences in the image as a "bag", then classify based on those counts. These models are called bag-of-features or BoF models.
For example, given an eye and a feather in an image, a simple BoF classifier would add +1 evidence for "human" for each detected eye and +1 evidence for "bird" for each detected feather. The class with the largest accumulated evidence is selected.
This simple BoF approach is highly interpretable and transparent. It is straightforward to examine which image features contribute evidence for a class, and spatial integration of evidence is trivial compared with deep nonlinear feature integration in modern neural networks. That clarity makes it easy to understand how decisions are made.
Traditional BoF models were state of the art before deep learning, but they were soon overtaken due to lower classification performance. The question is whether deep neural networks learn fundamentally different decision strategies than BoF models.
A deep but interpretable BoF network: BagNet
To test this, researchers combined BoF interpretability with DNN performance. The approach divides an image into small q x q patches, runs each patch through a DNN to obtain class evidence (logits) for that patch, and sums evidence across patches to make an image-level decision.
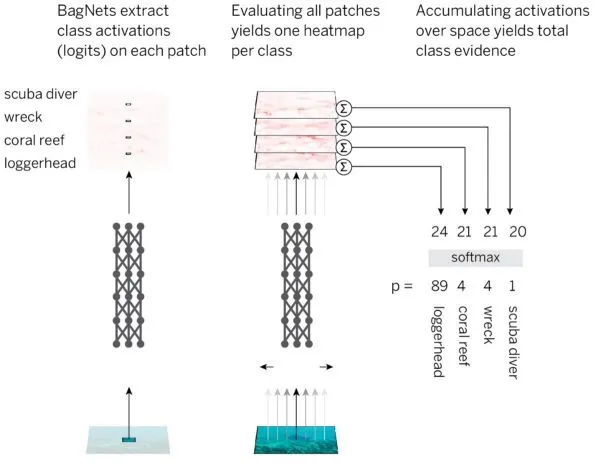
To implement this efficiently, the authors used a standard ResNet-50 architecture but replaced most (not all) 3x3 convolutions with 1x1 convolutions. In this design, hidden units in the final convolutional layer each "see" only a small part of the image, i.e. their receptive fields are much smaller than the full image.
This avoids explicit image partitioning while remaining close to a standard CNN. The resulting architecture is called BagNet-q, where q denotes the receptive field size at the top layer. The paper tested q = 9, 17 and 33. BagNet-q runs at roughly 2.5 times the runtime of ResNet-50.
BagNets performance on ImageNet
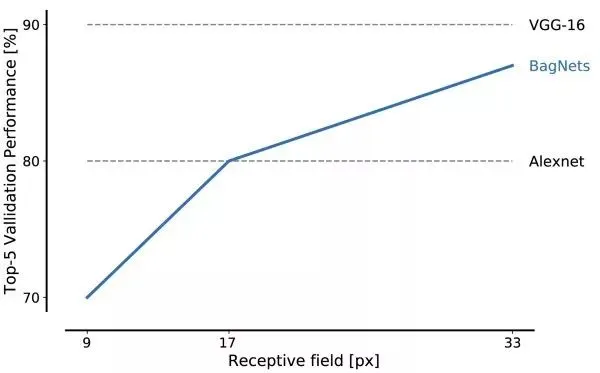
BagNets perform well even with very small patch sizes. Local features of size 17 x 17 pixels are sufficient to reach AlexNet-level performance, and 33 x 33 pixel features yield approximately 87% top-5 accuracy. With careful placement of 3 x 3 convolutions and additional hyperparameter tuning, higher performance is possible.
The first important result is that ImageNet can be effectively addressed using only local patch features. Large-scale spatial relationships such as object shape or arrangement of parts can be ignored without preventing high performance.
A key property of BagNets is transparent decision making. It is possible to see which image patches provide the most evidence for a given class and to quantify their exact contribution to the prediction.

The heatmaps produced by BagNets show the exact contribution of each image region to the decision. These maps are not approximations but display the real per-patch contributions.
ResNet-50 behaves surprisingly similarly to BagNets
BagNets demonstrate that high accuracy on ImageNet can be achieved by relying on local image features and weak statistical correlations between features and object classes. If this is sufficient, why would standard deep networks like ResNet-50 learn fundamentally different strategies? Why would they need to encode complex large-scale relationships such as object shape?
To test whether modern DNNs follow strategies similar to BoF networks, the authors evaluated ResNets, DenseNets and VGG on several BagNet "signatures":
- Invariance to spatial rearrangement of image features (testable only on VGG)
- Independence of modifications in different image regions, with respect to their contribution to total class evidence
- Similarity of errors between standard CNNs and BagNets
- Similar sensitivity to the same features in standard CNNs and BagNets
Across all four experiments, CNNs and BagNets behaved very similarly. For example, patches that most affected BagNets' predictions were largely the same patches that most affected CNNs. BagNets' heatmaps predicted DenseNet-169 sensitivity better than attribution methods such as DeepLift, which computes heatmaps directly for DenseNet-169.
That said, DNNs are not identical to BoF models. Deeper networks tend to learn larger features and exhibit more long-range dependencies. Deeper networks therefore improve on simple BoF models, but the core classification strategy often remains similar.
Explaining curious CNN phenomena
Viewing CNN decisions as a BoF-like strategy explains several curious observations about CNNs. It clarifies why CNNs have strong texture bias and why they are relatively insensitive to scrambled object parts. It also helps explain the existence of adversarial patches and perturbations: small misleading signals placed anywhere in an image can reliably influence the prediction regardless of whether those signals match the rest of the image.
The results indicate that CNNs rely on many weak statistical regularities present in natural images and do not integrate object-level evidence in the same way humans do. The same tendencies appear across other tasks and sensory modalities.
To counteract this reliance on weak statistics, researchers must reconsider architectures, tasks and learning methods. One option is to change CNN inductive biases from small local features toward more global features. Another option is to remove or replace features that the network should not rely on.
A larger issue is the task itself: if local image features are sufficient to solve the task, models need not learn the true "physics" of the natural world. That suggests a need to redesign tasks so models are encouraged to learn the physical essence of objects, which likely requires moving beyond purely observational learning of correlations and toward methods that allow models to extract causal dependencies.
Conclusion
In summary, the results indicate that CNNs can follow an extremely simple classification strategy based on local features. This finding attracted attention in 2019 and highlights how little is understood about the internal workings of deep neural networks.
Improving our understanding is essential to developing better models and architectures that narrow the gap between human and machine perception. Guiding CNNs toward more object-centric and physically grounded representations could yield substantial improvements in robustness and human-like behavior.





