ALLPCB
ALLPCB


Overview
In a simple computer model, the memory system can be viewed as a linear array of bytes that the CPU can access in constant time. In practice, the memory system is a hierarchy of storage devices with different capacities, costs, and access times. CPU registers hold the most frequently used data.
Small, fast cache memories located close to the CPU serve as buffers for data and instructions that are stored in the relatively slower main memory. Main memory acts as a cache for data located on larger, slower disks, and those disks may in turn act as caches for data on disks of other machines accessed over a network.
Cache Basic Model
The CPU fetches instructions and data from main memory over a bus, performs computation, and writes results back to memory. The bottleneck is that the CPU can perform operations much faster than main memory can supply data, so much time is spent waiting on memory. To reduce CPU accesses to slower main memory, a cache layer is inserted between the CPU and main memory, as shown below.
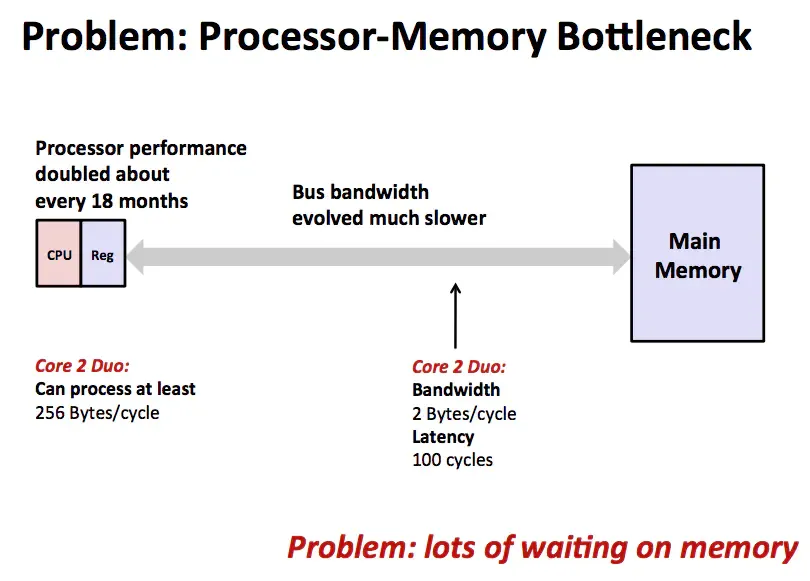
A cache is a smaller, faster memory used to store frequently or recently accessed instructions and data. Because cache is typically more expensive per byte than main memory, cache size is limited. Adding a cache layer helps mitigate the bottleneck between the CPU and main memory by exploiting locality.
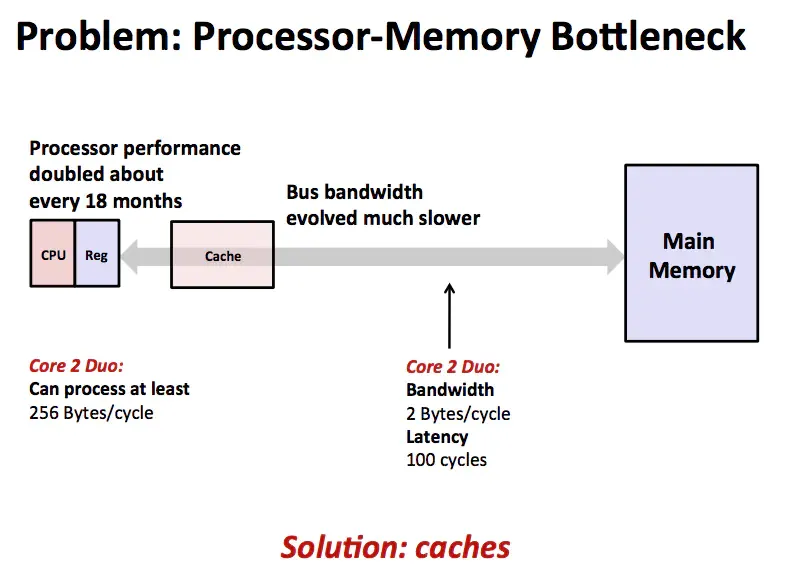
Principle of Locality
The reason a cache layer is effective is the principle of locality. Well-written programs tend to exhibit locality: references are likely to access data near other recently referenced data (spatial locality) or to reaccess the same data in the near future (temporal locality).
Temporal locality means that an address referenced once is likely to be referenced again soon. Spatial locality means that if a location is referenced, nearby locations are likely to be referenced soon. Programmers can improve performance by writing code with good locality.
Memory Hierarchy
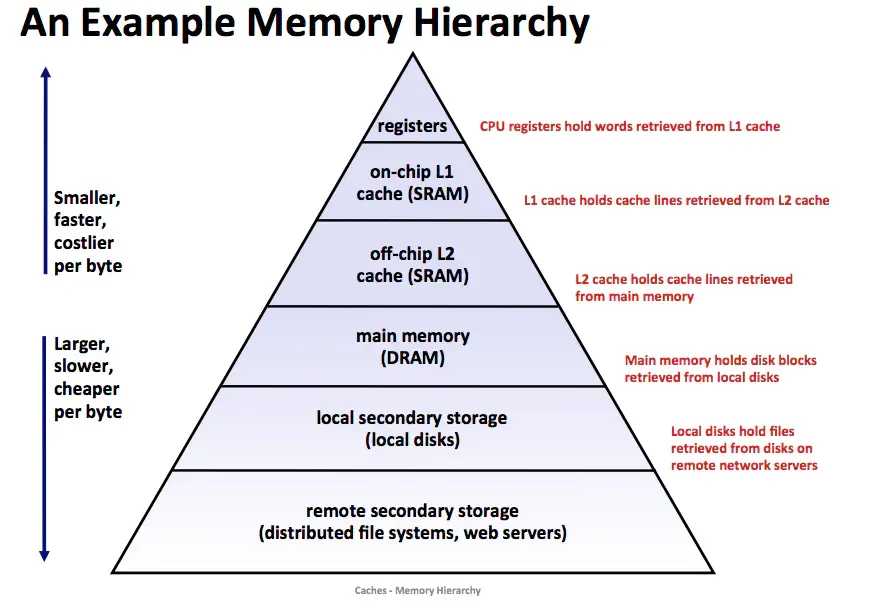
A typical memory hierarchy places smaller, faster, and more expensive storage closer to the CPU, and larger, slower, and cheaper storage further away. At the top are a small number of fast CPU registers, accessible in a clock cycle. Next are one or more small-to-medium SRAM-based caches, accessible in a few clock cycles.
Below the caches is the larger DRAM-based main memory, accessible in tens to hundreds of clock cycles. Further down are slower but higher-capacity local disks, and some systems include remote disks accessed over a network (for example, a Network File System, NFS).
The core idea is that the faster, smaller device at level k acts as a cache for the larger, slower device at level k+1. Each level caches a subset of the data objects stored at the next lower level. For example, a local disk can cache files retrieved from a remote disk.
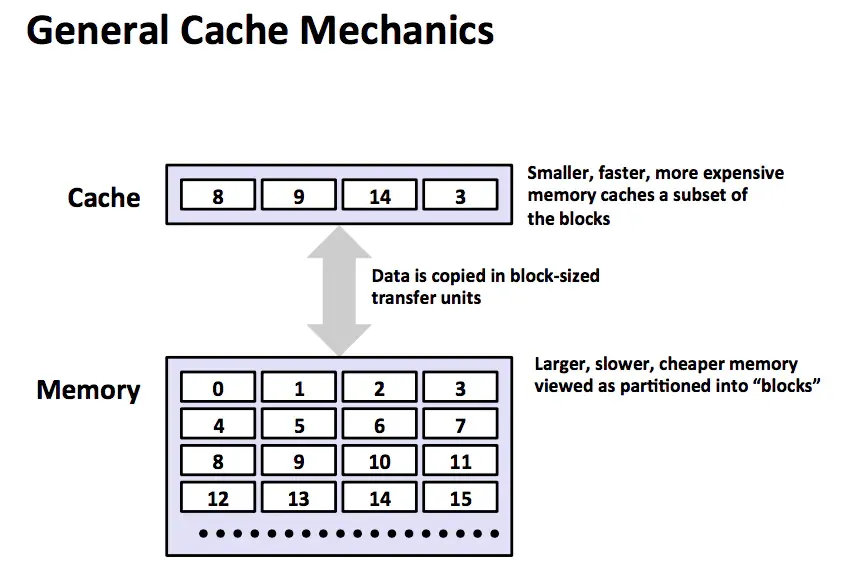
In the hierarchy, memory at level k+1 is partitioned into contiguous chunks called blocks. Each block has a unique address. The level k cache contains copies of a subset of these blocks. Data is transferred between level k and level k+1 in units of block size. Block sizes may differ between different adjacent layer pairs: L1-L2 transfers typically use blocks of a few dozen bytes, while transfers between lower layers may use blocks of hundreds or thousands of bytes. Larger blocks help amortize long access times of lower-level devices.
Cache Hits and Misses
When a program requests a data object d from level k+1, it first looks for d in a block currently stored at level k. If d is present, it is a cache hit and the program reads d from level k, which is faster. If d is not present, it is a cache miss. On a miss, the level k cache fetches the block containing d from level k+1, and if the level k cache is full it may evict an existing block. The eviction process is governed by a replacement policy, such as random replacement or least-recently-used (LRU).
Cache Organization
Early systems had three levels: CPU registers, DRAM main memory, and disk. As the speed gap between CPU and main memory widened, designers added a small SRAM cache called L1. As the gap continued, larger SRAM caches (L2, etc.) were added between L1 and main memory.
Consider a system with m-bit memory addresses, yielding M = 2^m addresses. A cache can be organized as an array of S = 2^s cache sets. Each set contains E cache lines. Each line stores a block of B = 2^b bytes, has a valid bit indicating whether the line holds useful data, and t = m - (s + b) tag bits that uniquely identify which block is stored in that line.
Depending on the number of lines per set E, caches are classified differently. A cache with one line per set (E = 1) is a direct-mapped cache. The following describes direct-mapped behavior.
Suppose a system has a CPU, a register file, an L1 cache, and main memory. When the CPU issues a read for a word w, it requests w from L1. If L1 has a copy, the cache hits and returns w to the CPU. On a miss, L1 requests the block containing w from main memory and the CPU waits. When the block arrives, L1 stores it in one of its lines, extracts w, and returns it to the CPU.
Cache access proceeds in three steps:
- Set selection
- Line matching
- Byte extraction
In direct-mapped caches, set selection uses the s set-index bits of the address to pick a set. With only one line per set, line matching compares the tag bits; if the valid bit is set and the tag matches, it is a hit. Byte extraction uses the block offset bits to select the requested word within the block.
On a miss in a direct-mapped cache, the new block replaces the existing line in the selected set, since each set has only one line.
Writing Cache-Friendly Code
Two basic goals for cache-friendly code are:
- Make the common case fast.
- Minimize the number of cache misses inside loops.
int sumvec(int v[N])
{
int i, sum = 0;
for (i = 0; i < N; i++)
{
sum += v[i];
}
return sum;
}
In this example, loop variables i and sum exhibit temporal locality. The array v is accessed with stride 1, so when v[0] causes a miss, the block containing v[0]..v[3] is loaded into cache and the next references hit. With a block holding four words, three out of every four references hit, which is good spatial locality.
Conclusion
Understanding the memory hierarchy is important because it has a major impact on application performance. Data stored in CPU registers is accessible in zero cycles during instruction execution; data in cache typically requires a few to a few dozen cycles; data in main memory requires hundreds of cycles; and disk access can require millions of cycles. By understanding how data moves through the hierarchy, programmers can structure their code so that frequently accessed data resides at higher, faster levels of the hierarchy.
Some practical points to improve performance:
- Repeated references to the same variable exhibit good temporal locality.
- Reference patterns with small stride have better spatial locality.
- Loops often exhibit good spatial and temporal locality.
- Arrays generally exhibit good spatial locality.
References
This article is based on lecture notes from the University of Washington course "The Hardware/Software Interface" and the textbook "Computer Systems: A Programmer's Perspective" (CS:APP). Images and content were derived from the course materials.