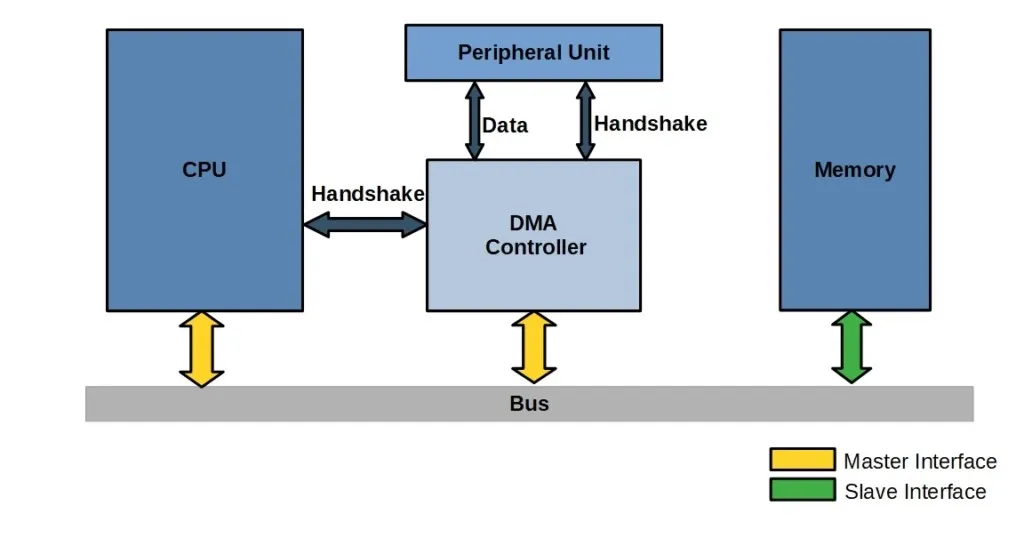
ALLPCB
ALLPCB


Overview
TigerGraph, which was the first graph database vendor to pass the LDBC SNB 1TB official audit, published an LDBC social network benchmark using a 108 TB dataset. The benchmark dataset contains 217.9 billion vertices and 1.6 trillion edges. The reported results show TigerGraph handling OLAP-style queries on this large graph workload.
Scalability Context
With multi?TB connected datasets that are incrementally updated hourly or daily becoming common, scalability is a key factor for graph database design and deployment. The 108 TB LDBC SNB BI workload demonstrates TigerGraph's ability to scale its graph engine to accommodate substantial data growth.
Previous 36TB Result and Software Version
In the prior year, TigerGraph completed the LDBC SNB BI benchmark on the SF30000 dataset. The full source dataset for that run was about 36 TB and contained 72.6 billion vertices and 539.6 billion edges. Both the 36 TB and 108 TB runs used TigerGraph Enterprise version 3.7.0. Compared with an earlier enterprise release (3.2.2), TigerGraph 3.7.0 showed improvements in loading and query performance. For example, reported load time decreased from 35.5 hours to 6.5 hours, and the average query time for power-batch queries decreased from 236.06 seconds to 99.90 seconds.
Data Expansion to 108TB
To reach the 108 TB scale, the dataset was expanded from the 36 TB base by replicating dynamic vertex and edge types three times. The resulting raw dataset loaded into TigerGraph exceeded 108 TB and contained 217.9 billion vertices and 1.6 trillion edges.
Hardware and Cost
The 108 TB benchmark used TigerGraph Enterprise 3.7.0 and a 72-node cluster of AWS r6a.48xlarge instances powered by 3rd-generation AMD EPYC processors, with total disk capacity of 432 TB. The reported hourly infrastructure cost increased from $281.27/hr (for the smaller run) to $843/hr for the 108 TB configuration. After loading the 108 TB raw dataset into TigerGraph, the on-disk footprint was reported to be reduced by a factor of 2.43.
Query Performance
On the graph containing 217.9 billion vertices and 1.6 trillion edges, TigerGraph processed complex deep-link OLAP-style queries. The report indicates that 11 data-intensive read queries returned results in under 1 minute, while the remaining queries completed within 1 to 10 minutes. These results indicate applicability to large-scale relationship analytics workloads that require frequent updates and full-graph OLAP computations.
Comparative and Operational Notes
The report notes cross-validation with another graph database on SF-10 for the 36 TB run. TigerGraph's reported capability to run large-scale graph analytics across 100+ machines, combined with cloud instance scalability, is presented as relevant for organizations seeking high-throughput graph processing at large scale.
Conclusion
The 108 TB LDBC SNB BI run demonstrates TigerGraph's reported ability to analyze graph-structured data at the hundreds-of-terabytes scale. The benchmark provides data points on loading efficiency, query latency, and infrastructure configuration for large OLAP graph workloads.