 ALLPCB
ALLPCB


Introduction
In Transformer architectures, the attention mechanism has computational complexity that scales quadratically with sequence length. This means that when models process longer text (for example, from thousands to tens of thousands of tokens), both computation time and memory requirements grow sharply. The original standard attention implementation has two main issues:
- High memory usage: the model constructs a large attention matrix of size N×N, which must be stored in high-bandwidth memory (HBM). For long sequences, this quickly exceeds GPU memory capacity.
- Poor compute efficiency: standard implementations break attention into multiple independent steps (matrix multiply, softmax, etc.). Each step requires reading data from relatively slow HBM, computing, and writing back to HBM. This frequent data movement becomes the performance bottleneck and reduces utilization of GPU compute units such as Tensor Cores.
What is FlashAttention?
FlashAttention enables processing of sequences with tens of thousands of tokens by reducing memory I/O and reorganizing computation. It improves training and inference throughput for long sequences. FlashAttention-2 reports up to 10x speedups over standard implementations on long sequences by focusing on memory-aware algorithms. FlashAttention-3 uses new hardware features such as FP8 on modern GPUs (for example, NVIDIA H100) to further increase throughput while preserving numerical accuracy via algorithmic techniques.
FlashAttention v1
Many prior works propose approximate attention methods to lower FLOPs, but they often ignore I/O costs across GPU memory hierarchy levels (fast on-chip SRAM versus slower HBM). As a result, those methods may not yield significant speedups in practice.
The core idea of FlashAttention is I/O-aware design: consider data movement costs between memory levels when designing the algorithm. On modern GPUs, compute is often faster than memory access, so many operations are memory-bound. FlashAttention addresses this with two key techniques:
- Tiling: split the input Q, K, V matrices into small tiles and perform computation in on-chip SRAM. This avoids materializing the full N×N attention matrix in slower HBM.
- Memory optimization: during backpropagation, FlashAttention does not store the large intermediate attention matrices. Instead, it stores only the forward-pass softmax normalization statistics. During backward, it recomputes required attention blocks in SRAM using those statistics, avoiding HBM reads of large matrices.
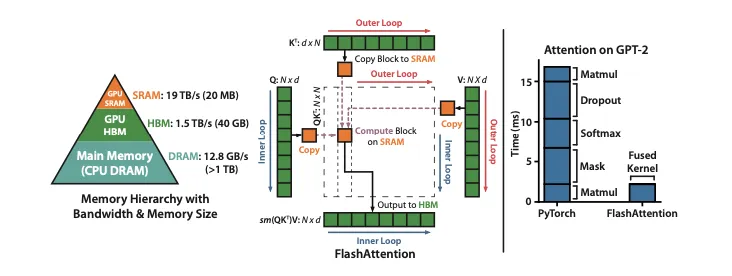
GPU memory hierarchy
- HBM (high-bandwidth memory): large capacity (for example, 40–80 GB on some GPUs) but relatively slower (bandwidth around 1.5–2.0 TB/s).
- On-chip SRAM: small capacity (for example, about 192 KB per streaming multiprocessor) but very fast (estimated bandwidth up to ~19 TB/s), orders of magnitude faster than HBM.
Because GPU compute performance has grown faster than memory speed, many operations are limited by memory access rather than arithmetic. Efficient use of fast on-chip SRAM is therefore crucial.
Operation types
Operations can be categorized by arithmetic intensity (the number of arithmetic operations per byte of memory accessed):
- Compute-bound: runtime dominated by arithmetic operations; memory access is a smaller factor. Example: large matrix multiplication.
- Memory-bound: runtime dominated by memory access; arithmetic cost is small. Examples: elementwise functions (activations, dropout) and reduction operations such as softmax and layer normalization.
Attention implementation improvements
Given query Q, key K, and value V matrices, attention is computed in three steps:
- Similarity computation
- Softmax normalization
- Weighted sum
Standard implementations (e.g., "Algorithm 0") implement each step as a separate GPU kernel and materialize intermediate matrices S and P to HBM. This leads to two main problems:
- Large memory footprint: intermediate matrices S and P are N×N, so memory scales as N^2.
- Extensive HBM accesses: each step reads and writes HBM, producing O(N^2) HBM accesses that dominate runtime for long sequences.

FlashAttention reduces HBM reads and writes and computes exact attention in a memory-efficient way using two techniques:
- Tiling: split Q, K, V into tiles and load only a small tile at a time from HBM into on-chip SRAM for processing.
- Recomputation: to avoid storing O(N^2) intermediates during backward, FlashAttention stores only softmax normalization statistics (for example, per-block maxima and log-sum-exp). During backward, it uses those statistics to recompute necessary attention blocks on demand in SRAM.
By combining tiling and recomputation, FlashAttention fuses matrix multiplication, softmax, optional masking, and dropout into a single CUDA kernel, avoiding repeated HBM writes between steps.
Performance results
FlashAttention achieved faster training of BERT-large than the MLPerf 1.1 record holder. Compared to a vendor implementation, FlashAttention reduced training time by 15%, demonstrating improved performance on standard long-sequence tasks.

When training GPT-2, FlashAttention produced significant end-to-end speedups compared with popular implementations:
- Up to 3x faster than a common Hugging Face implementation.
- Up to 1.7x faster than Megatron-LM.
- Importantly, FlashAttention achieves the same perplexity as the baseline model without changing the model definition, demonstrating numerical stability.
On the Long-Range Arena benchmark, FlashAttention provided a 2.4x speedup over standard Transformer implementations. Block-sparse FlashAttention outperformed tested approximate attention methods for very long sequences.
Memory usage with FlashAttention scales linearly with sequence length, while standard implementations scale quadratically, yielding up to 20x memory efficiency improvement in some cases.
FlashAttention v2
The first-generation FlashAttention exploited GPU memory hierarchy to reduce memory usage from quadratic to linear and obtained 2–4x speedups without approximation. However, its floating-point throughput remained below optimized GEMM, achieving only 25–40% of theoretical peak FLOPs/s. This was largely due to suboptimal work partitioning, which limited parallelism across thread blocks and warps and caused unnecessary shared-memory accesses.
FlashAttention-2 addresses these issues with improved work partitioning:
- Reduce non-matmul FLOPs: these operations are a small fraction of total FLOPs but execute slowly in practice.
- Parallelize across the sequence-length dimension: even a single attention head can be split across multiple thread blocks to raise GPU occupancy.
- Optimize intra-block work distribution: reassign work among warps in a thread block to reduce communication via shared memory.
Forward-pass improvements
FlashAttention-2 refines the online softmax technique in two ways:
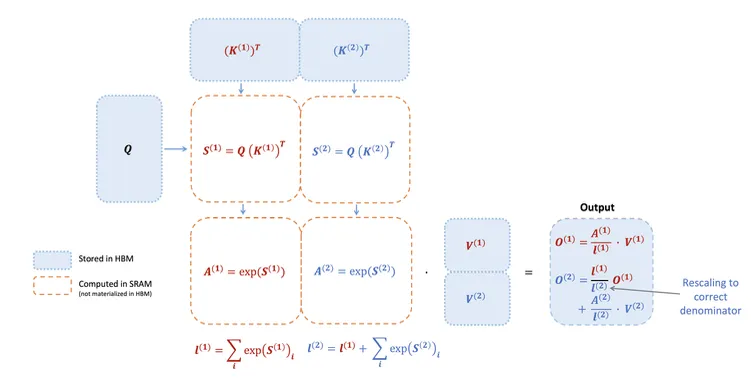
- Delayed normalization: do not normalize outputs immediately within each loop iteration. Instead, maintain an unscaled intermediate result and perform a single normalization at the end of the entire loop. This reduces scaling operations per tile and thus reduces non-matmul FLOPs.
- Simplified statistics: store only the logsumexp statistic L(j)=m(j)+log(l(j)) for backward, rather than storing both the maximum m(j) and the exponential sum l(j).
Parallelization improvements
The original FlashAttention parallelized only across batch size and attention heads. For very long sequences, batch sizes are often small, leaving GPU resources underutilized. FlashAttention-2 increases parallelization across the sequence-length dimension.
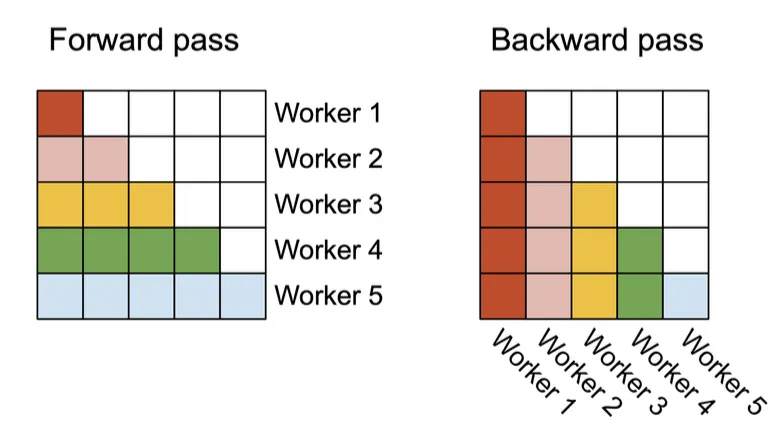
- Forward pass: assign row-block tasks of the attention matrix to different thread blocks that do not need to communicate. Parallelizing rows increases SM utilization when batch and head counts are small.
- Backward pass: similarly parallelize over column blocks. Because some backward updates require cross-block accumulation, atomic adds are used to update shared gradients dK and dV safely.
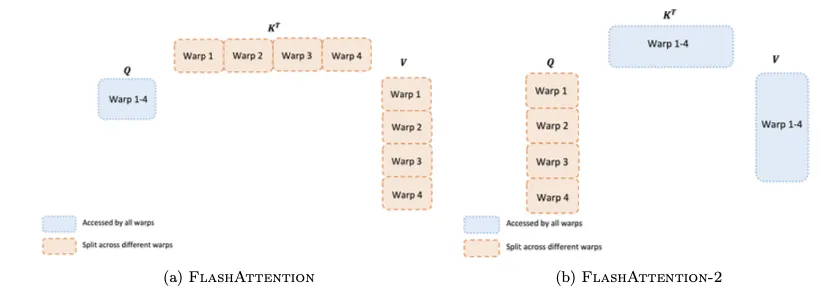
Beyond inter-block parallelism, FlashAttention-2 also optimizes work distribution among warps inside a block to reduce shared-memory traffic.
- Forward pass:
- FlashAttention v1: used a "split-K" scheme where different warps compute parts of K and V; warps then write intermediate results to shared memory and synchronize, causing extra shared-memory accesses.
- FlashAttention-2: assigns Q fragments to different warps. Each warp computes its Q fragment times the full K, allowing warps to complete their partial outputs independently without cross-warp shared-memory communication, improving efficiency.
- Backward pass: although dependencies are more complex, FlashAttention-2 similarly avoids the split-K scheme to reduce shared-memory reads and writes, improving performance.
Performance results
FlashAttention-2 is 1.7–3.0x faster than FlashAttention v1 and 1.3–2.5x faster than a Triton-based FlashAttention implementation.
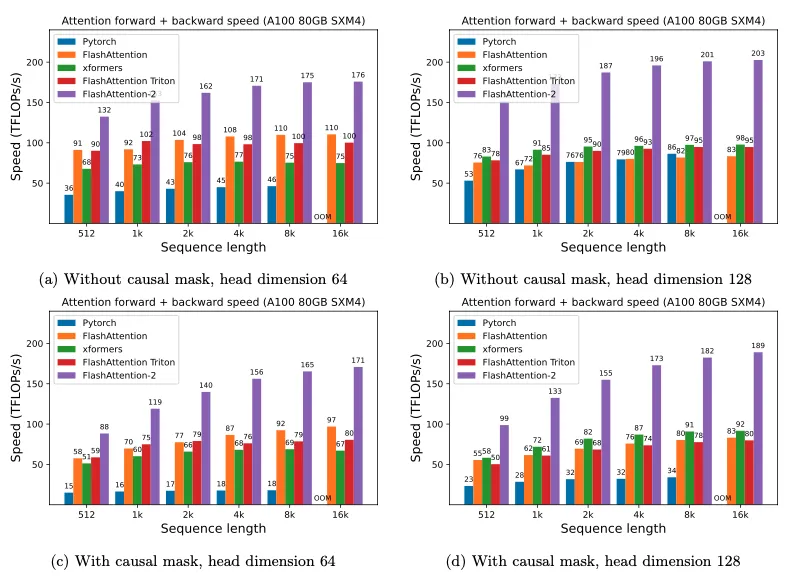
On A100 GPUs, FlashAttention-2 reached a forward-pass peak of 230 TFLOPs/s, about 73% of theoretical peak throughput. In backward, it reached about 63% of theoretical peak.
FlashAttention v3
Earlier FlashAttention versions reduced memory I/O to accelerate computation, but they did not fully leverage new hardware features on modern GPUs such as Hopper. For example, FlashAttention-2 achieved only about 35% utilization on H100 GPUs.
Like FlashAttention-2, FlashAttention-3 parallelizes work across thread blocks (CTAs), but it introduces intra-block warp role specialization:
- Producer: responsible for asynchronously loading data from HBM (global memory) into shared memory (SMEM).
- Consumer: after data is loaded, reads from SMEM and performs computation.
Producers and consumers synchronize using a circular buffer: producers place data into buffer stages and consumers consume stages; once a stage is consumed, the producer can reuse it to load new data.
Overlapping GEMM and Softmax within a thread
In standard FlashAttention, GEMM and softmax have sequential dependencies: softmax must wait for the first GEMM, and the second GEMM must wait for softmax results.
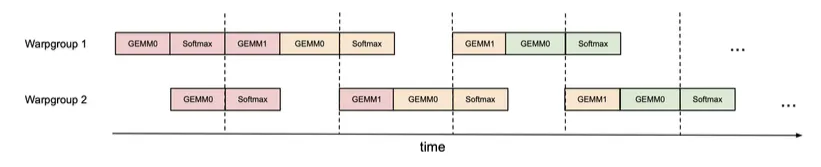
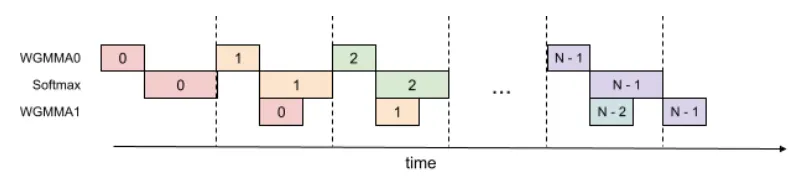
FlashAttention-3 breaks these dependencies by using extra register buffers. In each loop iteration, it asynchronously launches the next GEMM while concurrently performing softmax and update operations on the current GEMM output. This overlap of GEMM and softmax increases utilization.
FP8 low-precision computation
FP8 WGMMA (Warp Group Matrix-Multiply-Accumulate) instructions expect input matrices in a specific k-major layout, while tensors are often stored in mn-major layout.

FlashAttention-3 performs in-kernel transposes to satisfy the required layout. It uses LDSM/STSM-like instructions to move data efficiently between SMEM and registers while transposing during transfer, avoiding expensive HBM reads and writes.
Instead of conventional per-tensor quantization, FlashAttention-3 quantizes each block separately. Per-block scaling factors better handle outliers and reduce quantization error.
Performance results
FlashAttention-3 achieves 1.5–2.0x faster forward passes and 1.5–1.75x faster backward passes compared with FlashAttention-2. The FP16 variant reached a peak of 740 TFLOPs/s, about 75% of H100 theoretical peak throughput.
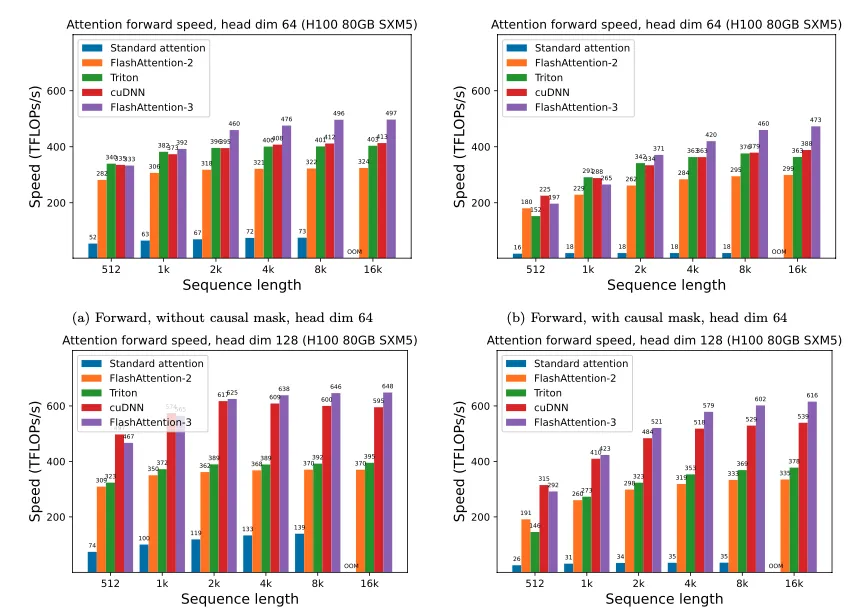
For medium to long sequences (1k tokens and above), FlashAttention-3 outperforms vendor-optimized libraries that target H100, such as cuDNN, for attention computations.





