ALLPCB
ALLPCB


Developing high-reliability embedded systems requires a comprehensive approach, from adhering to a structured development cycle to implementing rigorous execution and systematic checks. This article outlines several practical and durable techniques to enhance system reliability and detect anomalous behavior.
Selecting Reliable Hardware and Software Components
To ensure system reliability, it is advisable to use hardware and software components that have undergone extensive validation. Newer versions of software may contain undetected bugs, making established components a safer choice.
- Hardware: Opt for high-reliability processors, memory, and sensors that have been rigorously tested. For example, industrial-grade embedded systems often use components known for long-term operational stability.
- Software: Choose validated operating systems, drivers, and middleware to ensure compatibility and stability. Real-time operating systems (RTOS) can offer enhanced system predictability and reliability.
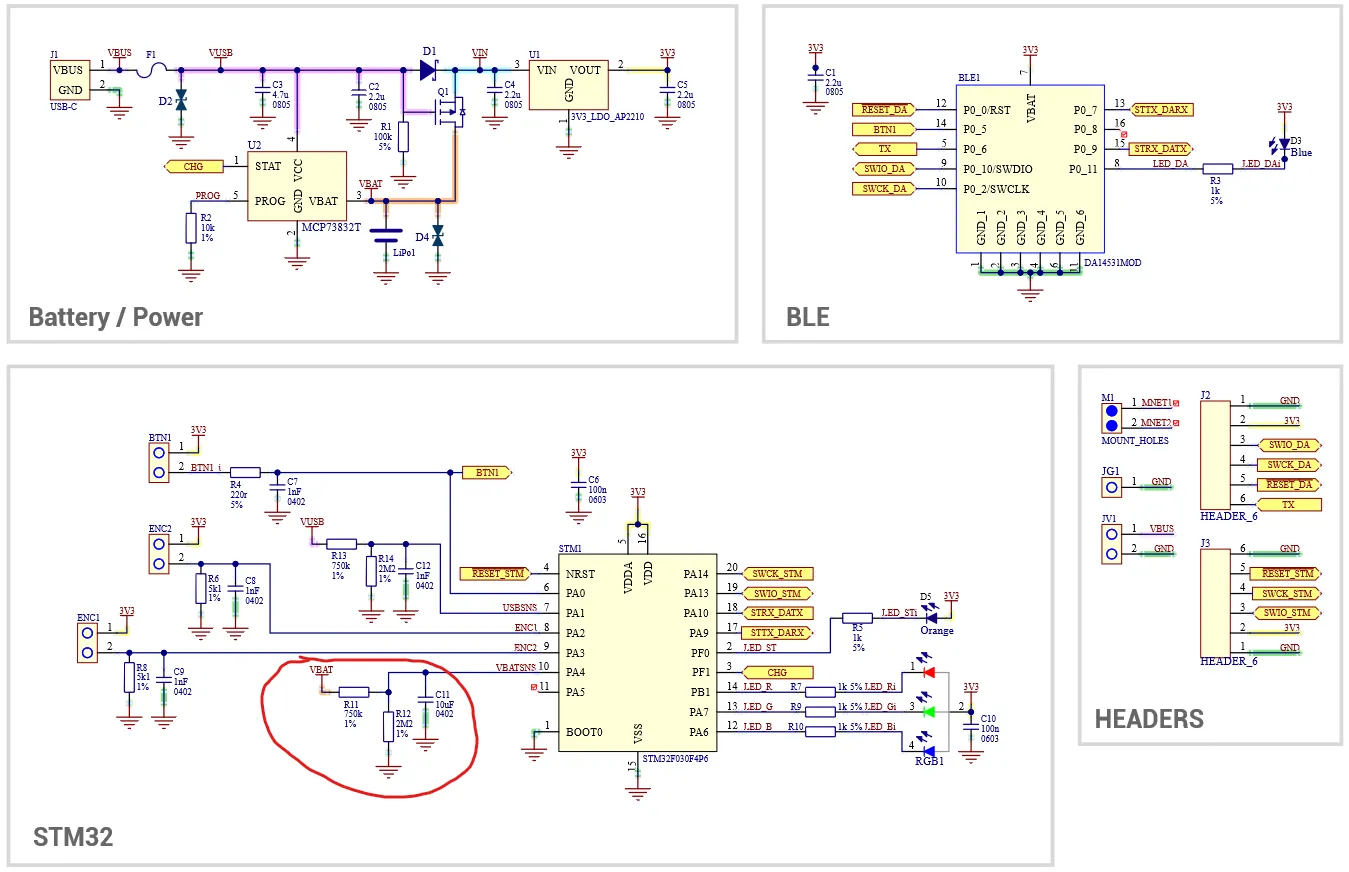
Verifying Application Integrity with CRC
Modern integrated development environments (IDEs) and toolchains can automatically generate checksums or cyclic redundancy checks (CRCs) for applications or memory spaces. These checksums are typically used to verify application integrity during code loading. However, retaining the CRC in memory allows for ongoing validation, such as at system startup or periodically for long-running systems, to ensure the application remains intact.
While the likelihood of an application being altered is low, the billions of microcontrollers deployed annually in potentially harsh environments make application corruption a non-zero risk. A system defect, such as an unintended flash write or erase, could compromise application integrity.
Performing RAM Checks at Startup
Ensuring hardware functionality is critical for system reliability. Conducting RAM checks at startup, for both internal and external memory, verifies that the hardware operates as expected. A common method involves writing a known pattern to RAM, waiting briefly, and reading it back to confirm consistency. While most checks pass, a failure provides an early indication of hardware issues.
Implementing a Stack Monitor
Stack overflows are a common challenge in embedded systems. While stack size is statically allocated at compile time, its usage is runtime-dependent, storing variables, return addresses, and other data dynamically. Excessive stack growth can overwrite adjacent memory, causing system instability.
A stack monitor creates a buffer zone between the stack and other memory regions, filled with a known bit pattern. The monitor periodically checks for changes to this pattern, indicating stack overflow. If detected, the system can log the event and relevant diagnostics for analysis. Many RTOSes and microcontrollers with memory protection units (MPUs) include stack monitoring, though it is sometimes disabled to save memory. Enabling this feature is highly recommended.
Leveraging Memory Protection Units (MPUs)
MPUs, once rare in low-cost microcontrollers, are increasingly common. They enhance firmware robustness by isolating memory spaces for different tasks, preventing unauthorized access or corruption. In an RTOS-based system, MPUs ensure tasks execute within their designated memory boundaries. If a task behaves errantly, the MPU can terminate it and trigger protective measures. Developers should prioritize microcontrollers with MPUs and utilize their capabilities.
Designing a Robust Watchdog System
A watchdog timer is a critical reliability feature, designed to reset the system if an error prevents normal operation. However, poorly implemented watchdogs, such as those cleared by an independent periodic timer, may fail to detect system failures. A robust watchdog system requires integration with application tasks. For example, tasks can signal successful completion within a specified period; failure to do so prevents the watchdog from being cleared, triggering a reset. Advanced implementations may use an external watchdog processor to monitor the main processor¡¯s performance.
Avoiding Dynamic Memory Allocation
Dynamic memory allocation, such as using `malloc` in C to allocate heap memory, is common in general computing but risky in resource-constrained embedded systems. Improper use can lead to memory leaks or fragmentation, which embedded systems are ill-equipped to handle. If an application requests memory that is unavailable, system failure may result.
A safer approach is static memory allocation. For instance, defining a fixed 256-byte buffer at compile time avoids heap-related issues and ensures memory availability throughout the application¡¯s lifecycle.