ALLPCB
ALLPCB


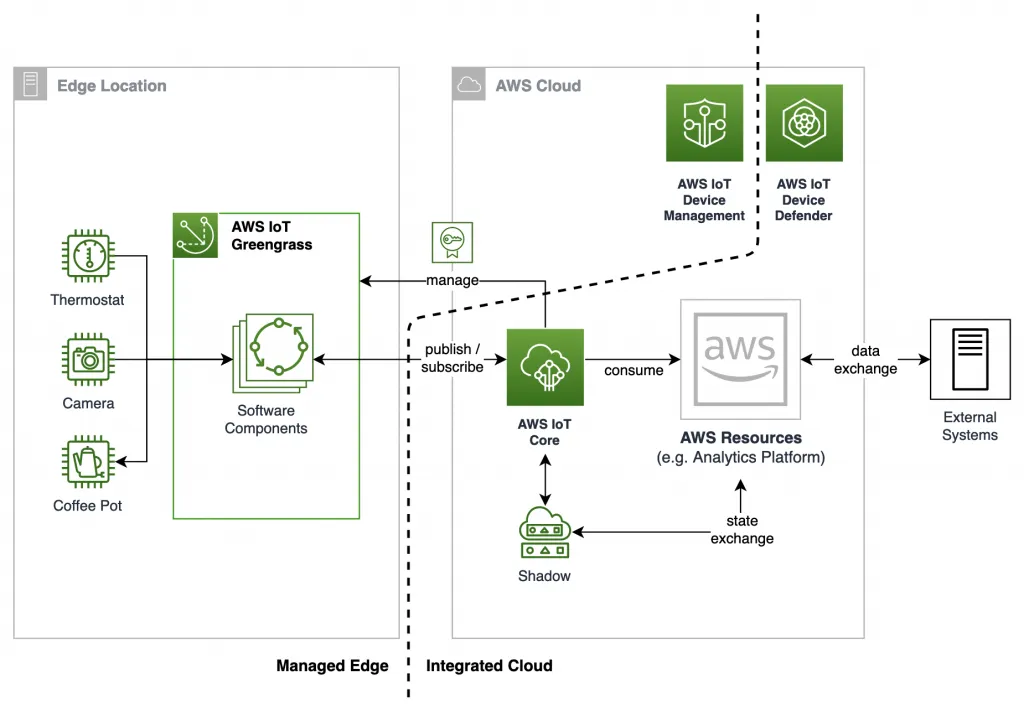
Internet of Things (IoT) offers each industry opportunities to address operational challenges. As device counts increase, solutions are needed to connect, collect, store, and analyze device data. Amazon Web Services (AWS) provides various services that enable connected devices to interact securely with cloud applications and other devices. Migrating or designing IoT solutions on the AWS platform lets teams focus on core functionality without managing underlying infrastructure, supporting high availability and stability.
Design for reliable large-scale operation
IoT systems must handle high-velocity and high-volume data captured by devices and gateways. Sudden spikes in traffic, caused by legitimate business growth or by malicious activity, can lead to data surges. Cloud architectures should be designed to scale to absorb such influxes.
A recommended approach is to send incoming data into queues, buffers, or real-time memory stores before committing it to persistent storage. This enables real-time event handling while smoothing insertion rates to prevent database overload or performance degradation.
Devices can publish data to Amazon Kinesis, or AWS IoT rules can forward data to Amazon SQS and Kinesis for storage in Amazon S3, Amazon Redshift, a data lake, or Elasticsearch and other time-series stores. These storage layers can then be used to build custom dashboards or visualizations with tools such as Amazon QuickSight.
Route large data volumes through data pipelines
Directly connecting incoming device topic data to a single service limits scalability and may reduce availability during failures or data flood events.
The AWS IoT rules engine is designed to connect endpoints to AWS IoT Core in a scalable manner. However, different AWS services have different data flow characteristics and trade-offs. No single service should be treated as the only ingress point for all traffic. For high-volume scenarios, consider buffering (ElastiCache) or queuing (SQS) incoming data before invoking downstream services so the system can recover from downstream failures.
AWS IoT rules can trigger multiple AWS services in parallel, such as AWS Lambda, Amazon S3, Amazon Kinesis, Amazon SQS, and Amazon SNS. Once IoT data is captured, these AWS endpoints can process and transform it, enabling simultaneous storage in multiple data stores.
A robust pattern is to redirect device topic data to Amazon SNS topics designed to handle bursty traffic, ensuring reliable ingestion and delivery to appropriate downstream channels. For scalability, use multiple SNS topics, SQS queues, and Lambda functions for different device topic groups. Consider staging data in durable buffers such as queues, Amazon Kinesis, Amazon S3, or Amazon Redshift before processing. This practice reduces the risk of data loss from message floods, unexpected exceptions, or deployment issues.
Automate device provisioning and updates
As deployments scale and many devices join an IoT ecosystem, manual processes for device configuration, boot software, security settings, rule configurations, and OTA updates become impractical. Minimizing manual interaction during initial provisioning and upgrades saves time and reduces costs.
Design devices with built-in capabilities for automated provisioning and use AWS tools to manage provisioning and lifecycle. AWS IoT supports bulk import workflows and policy sets that can integrate with manufacturing or provisioning flows, allowing devices to be pre-registered and certificates to be installed. Later, provisioning flows can claim devices and attach them to users or other entities. AWS also provides tooling to trigger and track device OTA updates.
Adopt an extensible architecture for custom components
IoT solutions often need to integrate with external systems beyond device connectivity, control, and reporting. Consider incorporating data science and machine learning, or integrating third-party services such as IFTTT, Alexa, or Google Home. Architectures should allow external components to be integrated without creating performance bottlenecks.
Plan for offline access and edge processing
Not all machine data needs to be processed in the cloud, and continuous Internet connectivity may not be available. Add AWS Greengrass at the edge to process and filter data locally, reducing the need to send all device data upstream. Edge components can capture and retain data for a limited period and forward it to the cloud on error events or on demand. For time-series requirements, schedule regular uploads of device data to the cloud to enable future use cases such as cloud-based analytics and machine learning.
Choose appropriate data stores
IoT systems generate high-velocity, high-volume, and heterogeneous data. Different devices or topics may use different data formats that are not well suited to a single database type. Architects should carefully select data stores and formats. A single store may suffice in some cases, while a mix of stores optimized for specific purposes often yields higher throughput and maintainability. Frequently accessed static data can be cached with ElastiCache to improve performance and overall system scalability.
Filter and transform data before processing
Incoming IoT data often requires filtering or transformation before storage or forwarding. AWS IoT rules provide actions to route messages to different AWS services. Architects should categorize data into types such as data that requires processing, configuration or static data to be ignored or stored as-is, and data to be persisted directly.
AWS IoT service architecture
AWS IoT supports rapid device connectivity, secure data ingestion, device management, and multi-protocol support. The guidance above helps design scalable, reliable IoT solutions for domains such as logistics, healthcare, home automation, and security and monitoring.