ALLPCB
ALLPCB


Overview
MonoDream enables robots to obtain global awareness and forward-looking navigation using only a single monocular camera.
A key challenge in vision-and-language navigation (VLN) is enabling agents to follow instructions, understand space, maintain orientation, and make sequential decisions in real environments. High-performance systems have typically relied on panoramic RGB-D sensors to fill field-of-view gaps and provide geometric cues, but those solutions increase cost, power consumption, and system complexity, making large-scale deployment difficult. MonoDream takes a different approach: it does not add sensors, but instead strengthens the monocular model's ability to imagine unseen scene geometry and future states.
Core idea
Researchers at Horizon and collaborators build a unified navigation representation (UNR) for vision-language models and introduce an implicit panoramic dreaming mechanism (LPD). During training, the model is trained to predict implicit panoramic RGB-D features for the current and future timesteps from only monocular inputs, which teaches the agent to reconstruct space and reason about dynamics from limited views. At inference, MonoDream requires only a monocular image for navigation decisions, eliminating the need for panoramic input, explicit depth, or an explicit reconstruction module. This achieves global understanding and foresighted decision making with a lightweight sensing setup, narrowing the performance gap between monocular and panoramic navigation approaches.
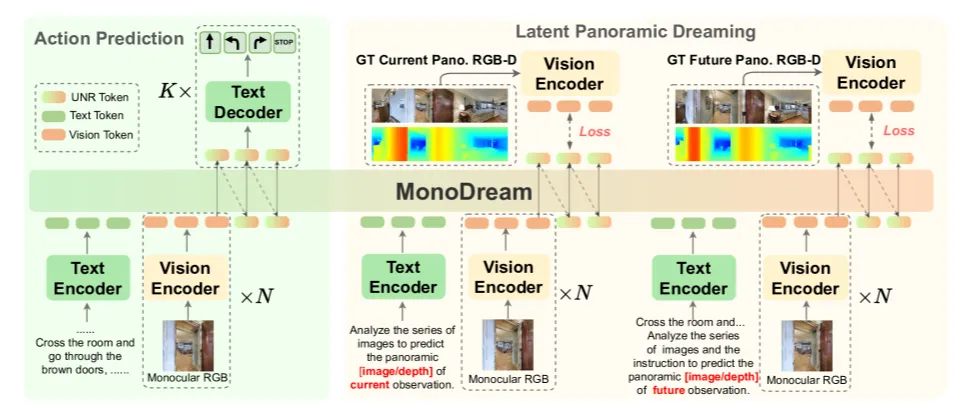
MonoDream trains an implicit panoramic imagination while making navigation decisions from monocular images, allowing the model to infer complete spatial layouts and future states from a restricted field of view.
Building imagination inside the agent
Rather than fighting incomplete observations, MonoDream trains the model to imagine the unseen world. Using UNR and the LPD mechanism, the model is forced during training to predict implicit panoramic RGB-D features for present and future frames from monocular inputs alone. This enables spatial completion across missing viewpoints and temporal anticipation of future states. Crucially, these imagined representations are not rendered explicitly; they are internalized as part of the navigation policy.
At deployment, MonoDream returns to a minimal hardware regime: no panoramic sensors, no depth maps, and no explicit reconstruction. A standard monocular camera suffices for navigation decisions. Training grants the model a "see more" capability, while inference maintains a device-minimal footprint. This design makes imagination a functional capability rather than an additional sensor burden.

MonoDream can make correct navigation choices at corners and in blind spots, whereas models without imagination tend to misjudge routes and enter wrong rooms.
Monocular potential beyond expectations
Experiments show this approach is both feasible and effective. On standard benchmarks such as R2R-CE and RxR-CE, MonoDream achieves leading performance under monocular settings, maintains robust generalization with limited training data, and significantly reduces the performance gap with panoramic solutions. The results suggest that monocular limitations were not inherent to the sensor, but rather due to models lacking the ability to complete missing views and form spatial cognition.
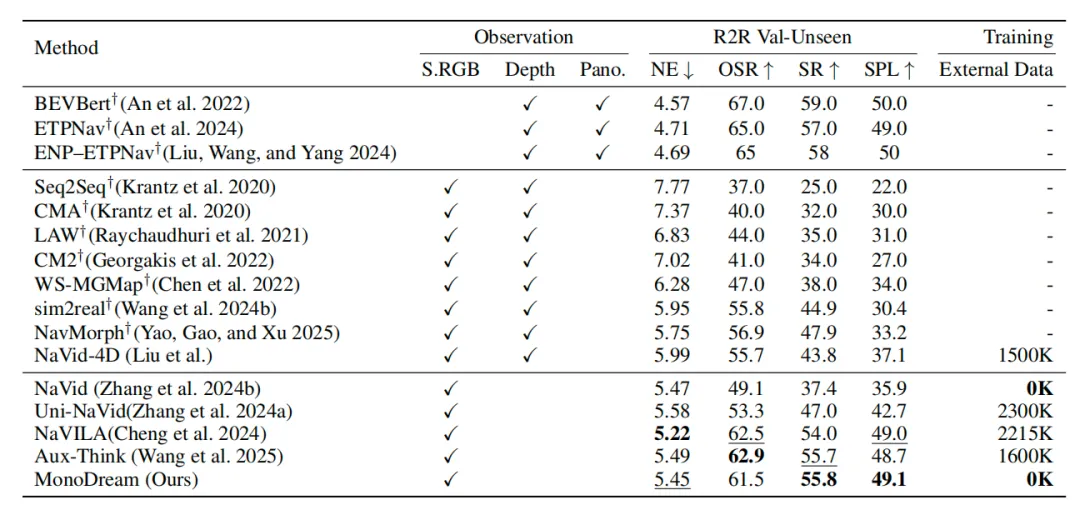
On the R2R-CE benchmark, MonoDream using only monocular input approaches the performance of panoramic and depth-based models without relying on external data.
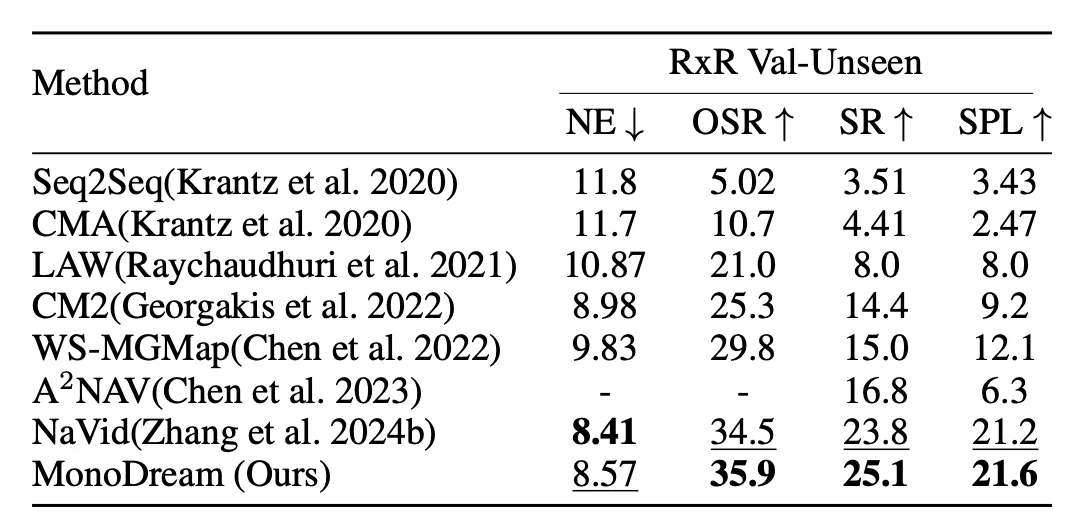
Even without training on RxR-CE data, MonoDream transfers directly and achieves state-of-the-art results, demonstrating that the implicit panoramic dreaming mechanism provides global understanding and long-range navigation capability.
Conclusion and outlook
When a robot can reconstruct panoramas and future states from a monocular image, it becomes less constrained by its raw inputs and can rely on an internal world model for imagination and decision making. This paradigm can extend to higher-level embodied intelligence tasks such as long-range planning and interactive understanding, and potentially enable autonomous reasoning and exploration in unknown environments. MonoDream reframes what monocular sensors can achieve by showing how cognitive abilities can compensate for hardware limitations.