 ALLPCB
ALLPCB


Background
AWS began using the Nitro DPU in 2017, and soon concluded that continuing to innovate in server infrastructure would require innovations across its compute engines. Since then, multiple generations of Nitro DPU, four generations of Graviton Arm server CPUs, two generations of Inferentia inference accelerators, and now a second-generation Trainium training accelerator have emerged. Trainium2 was announced alongside the Graviton4 server CPU at AWS re:Invent 2023 in Las Vegas. This article examines the Trainium2 training engine and its relationship to the Inferentia series.
AWS has not published extensive technical details about these AI compute engines. The Next Platform team spoke with Gadi Hutt, senior director of business development at AWS Annapurna Labs, who is responsible for designing the compute engines and coordinating with foundries. That discussion, along with a review of available technical documentation, informed an assessment of AWS systems and the relationship between Inferentia and Trainium. Where official details are absent, reasonable inferences were made.
Before diving into technical detail, a brief calculation provides context for the scale and economics of these investments.
Purchasing Context
In his re:Invent keynote, AWS CEO Adam Selipsky introduced Jensen Huang, Nvidia co-founder and CEO, who noted that during the Ampere A100 and Hopper H100 generations, AWS purchased around two million of those devices.
Reports suggested AWS completed about 50,000 H100 orders in 2023, with an estimated 20,000 in the prior year. At an assumed price of $30,000 per unit—given strong demand and limited incentive for Nvidia to discount—those 2023 purchases would represent about $2.1 billion. The remaining 1.93 million A100 units, at an average price since 2020 of roughly $12,500, would total about $24.13 billion.
Given such large investment flows, there is room for cost-performance optimization, and AWS has deployed internally developed models and deployed other third-party models—such as Anthropic's Claude 2—on its own Inferentia and Trainium hardware.
Value Proposition
The cost-performance curve for custom silicon at AWS resembles the one it established with Graviton server CPUs. AWS continues to sell Intel and AMD CPU instances, but its Graviton-based instances typically offer 30% to 40% better price/performance relative to "traditional" x86 instances. By removing intermediaries and using its own Arm CPUs, AWS can offer lower-cost instances that appeal to many customers. A similar pricing differential is expected between Nvidia and AMD GPUs and AWS-manufactured Inferentia and Trainium devices.
Compute Engine Hierarchy
All compute engines are hierarchies of compute elements, storage elements, and the networks that connect them. The abstraction levels around these elements can change, particularly when an architecture is new and workloads are evolving rapidly.
Inferentia1
Inferentia1 was developed by Annapurna Labs and first announced in November 2018, with general availability a year later. It formed the foundation of AWS's early AI engine efforts. The device architecture includes four cores, distinct compute elements, on-chip SRAM for local storage, and off-chip DDR4 main memory, similar to many AI chips available today.
AWS did not publish detailed specs for Inferentia1's SRAM sizes, cache sizes, or clock speeds, nor the exact element count inside each NeuronCore. However, the Neuron SDK discusses the NeuroCore-V2 core used in Inferentia2 and Trainium1, which provides a basis for inferring Inferentia1's architecture and for projecting Trainium2.
Across generations, a NeuronCore contains a ScalarEngine for scalar computations and a VectorEngine for integer and floating-point vector computations of various precisions. These roughly correspond to CUDA cores in Nvidia GPUs. According to the Neuron SDK, the NeuronCore-v1 ScalarEngine processes 512 floating-point operations per cycle, and the VectorEngine processes 256 floating-point operations per cycle. The SDK wording suggests these refer to 512-bit and 256-bit processing widths per cycle, with data formatted and supplied according to the computation type.
NeuronCore architecture also includes a TensorEngine to accelerate matrix math beyond what the VectorEngine can deliver. Matrix math is critical for HPC and AI workloads, which typically require high throughput. In NeuronCore-v1, TensorEngines provide about 16 teraflops at FP16/BF16 precision, roughly analogous to TensorCores in Nvidia GPUs.
Trainium1
Trainium1 was announced in December 2020 and shipped in two instance families (Trn1 and Trn1n). Public documentation on Trainium1 and the instances introduced in December 2021 was limited. Trainium1 uses the NeuroCore-v2 core, which retains the same element types but deploys fewer cores overall.
Trainium1 added 32 GB of HBM stacked DRAM to increase device bandwidth, adopted a PCI-Express 5.0 form factor and I/O slot, and increased the number of NeuronLink interconnect links between chips, doubling to quadrupling interconnect bandwidth while also doubling memory bandwidth.
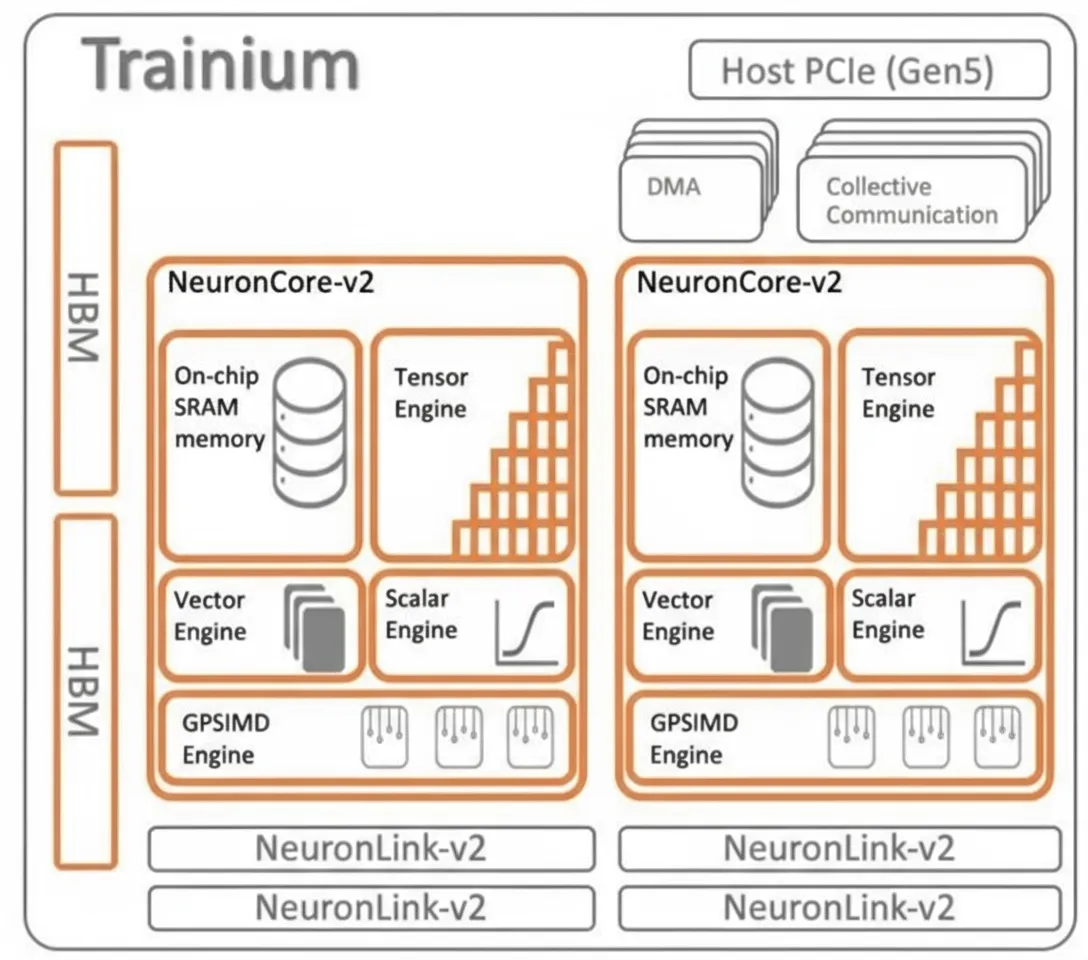
It appears that Trainium1 reduced the number of NeuronCores per chip relative to Inferentia1—likely halving core count—but increased the number of scalar, vector, and tensor engines within each core. The change mainly affected the cache and memory hierarchy abstraction, effectively enabling multithreading across the different compute element types inside each NeuronCore.
NeuronCore-v2 in Trainium introduced a GPSIMD engine: a set of eight 512-bit general-purpose processors that can be addressed directly from C and C++ and can access on-chip SRAM and the other compute engines on the core. This facilitates implementing custom operations that may or may not require acceleration while remaining compatible with data and compute formats used by the other engines.
Inferentia2
Inferentia2 for inference is largely a Trainium1-like chip with approximately half the NeuronLink-v2 interconnect ports. Some chip elements on Inferentia2 may be disabled. Clock speeds, performance, and HBM memory capacity and bandwidth are broadly comparable between Inferentia2 and Trainium1.
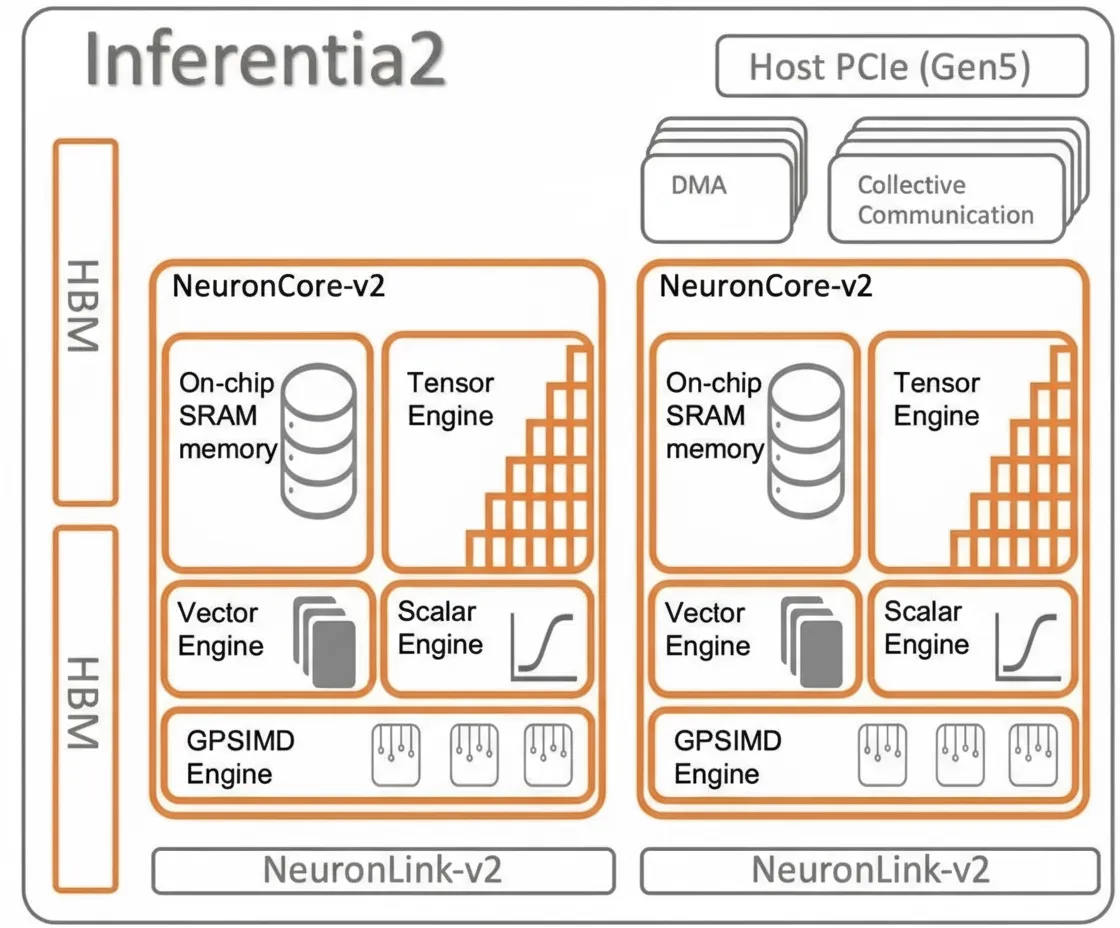
"The chip architecture between Inferentia2 and Trainium1 is nearly identical," Hutt told The Next Platform. "We reserved HBM bandwidth for Inferentia2 because it's important for inference as well as training. Large language model inference is actually memory-bound, not compute-bound. So we can use a similar silicon architecture and reduce cost where possible—for example, we don't need as many NeuronLink ports. For inference, a ring link to generate tokens is sufficient. For training, you need full mesh connectivity to minimize hops between accelerators inside a server. Training servers require much more network bandwidth."
In a 16-chip Trainium1 server, the interconnect forms a 2D torus or a 3D hypercube, depending on how one describes it. Hutt describes these topologies as equivalent representations of the same connectivity pattern.
Performance and Feed Rates
The available data for Inferentia1, Inferentia2, and Trainium1 was compiled into a comparative table along with predictions for Trainium2. The Neuron SDK has not yet been updated with Trainium2-specific details.
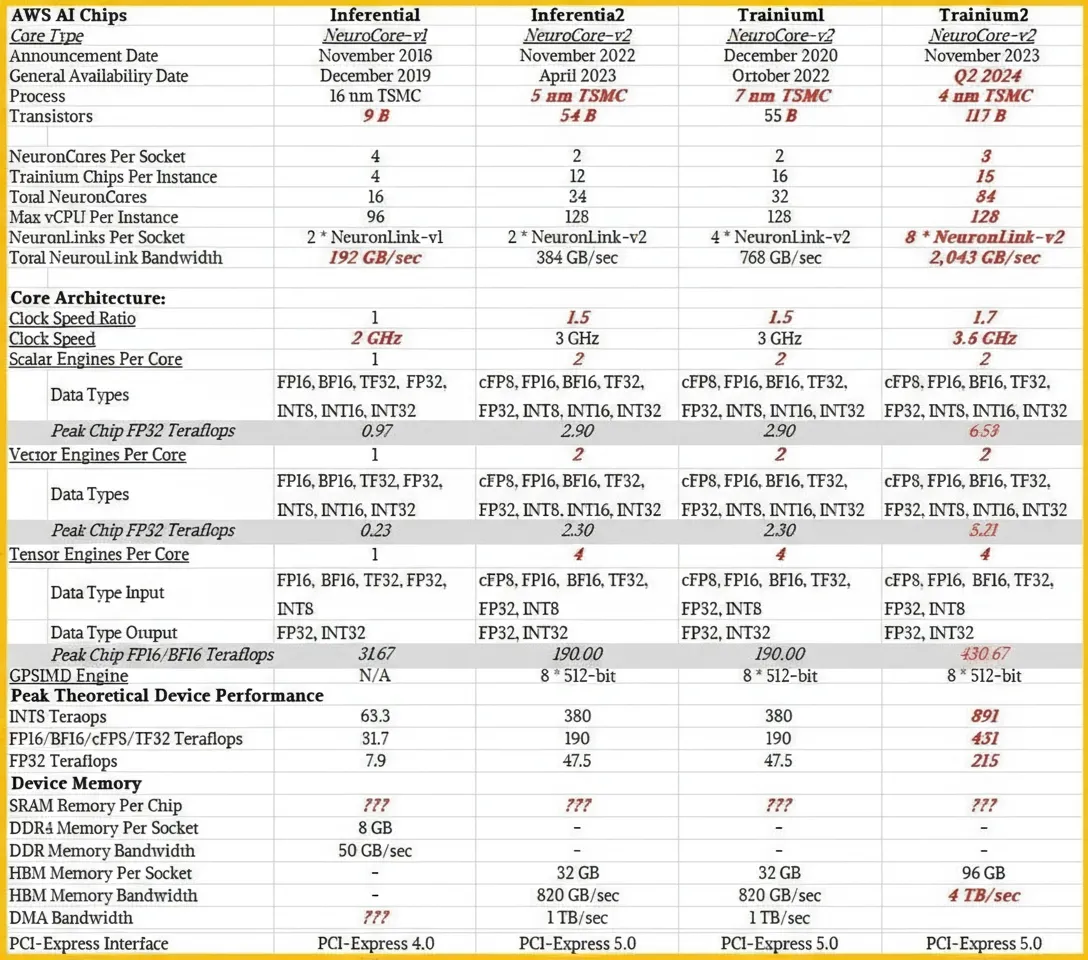
Trainium2 Expectations
Based on package imagery, Trainium2 appears to be essentially two Trainium1-class chips interconnected—either as a single monolithic die or as two chiplets connected via a high-speed interconnect.
Hutt did not disclose specific metrics for Trainium2, but confirmed it will have more cores and greater memory bandwidth. He also said effective performance could scale up to 4x versus Trainium1, calling that a conservative estimate and noting actual AI training workloads are often limited by memory capacity and bandwidth rather than compute throughput.
Projected details include a move from the 7 nm process used in Trainium1 to a 4 nm process for Trainium2, enabling roughly double the core count within comparable or slightly higher power envelopes. Clock speeds are expected to increase modestly from the disclosed 3 GHz in Trainium1 to around 3.4 GHz in Trainium2. Total NeuronLink bandwidth may increase by about 33%, to 256 GB/s per port, producing roughly 2 TB/s aggregate and still allowing a 2D torus interconnect. The number of NeuronLink ports per chip may increase to add torus dimensions and reduce hops when devices share data. A 2D torus implies a fixed two-hop path between any two NeuronCore chips in a cluster. A full mesh is possible but appears less likely.
To support scaling an Ultracluster to 100,000 devices, AWS may increase manufacturing yield by disabling a small portion of cores on many chips. For example, if about 10% of cores are disabled to improve yield, AWS could reserve fully functional Trainium2 chips for internal use where every core is required, and deploy slightly derated chips more broadly. This could result in shipped devices having 56 to 58 active cores rather than a full 64. AWS mentioned a 96 GB memory configuration, which may correspond to three of four HBM stacks being active; actual HBM capacity per device could be 128 GB. HBM3 is suspected but not confirmed.
Hutt emphasized that performance is memory-driven rather than defined by peak theoretical compute. If correct, memory bandwidth between Trainium1 and Trainium2 could grow by about 5x.
Instance Types
The following figure shows instances that use Inferentia and Trainium chips.
Expected Competitive Positioning
Exact comparisons between Trn2 instances and GPU-based instances in price or performance remain speculative. Based on indications and inference, Trainium2 may deliver roughly 2x the performance of an Nvidia H100 for certain workloads, which would position it competitively with H100-class accelerators. Nvidia's newly announced H200 uses larger, faster HBM3e memory for some variants, which will affect comparisons across model sizes. If AWS prices Trainium2-based EC2 instances proportionally to the price/performance gap seen between Graviton CPUs and x86 processors—roughly 30% to 40%—Trainium2 instances could offer a different cost profile versus Nvidia GPU instances. Hutt did not confirm pricing or specific ratios, only noting that price-performance will improve.
At scale, connecting 100,000 devices running FP16 precision to deliver about 65 exaflops without sparsity techniques, using true FP16 precision, could create one of the largest AI clusters in the world.





