 ALLPCB
ALLPCB


Graduation season and job hunting? If you are applying for machine learning engineer positions, you may encounter technical interviews. These interviews assess your actual grasp of the technology, so they are important. Recently, JP Tech published an article listing 12 basic interview questions they might ask new hires. The questions are fundamental but worth reviewing.
Overview
These questions are ones I commonly ask when interviewing candidates for AI engineering roles. Not every interview will use all of them, since questions depend on the candidate's experience and projects. After conducting many interviews, especially with students, I collected these 12 deep learning questions and share them here.
Question 1: Explain the purpose of batch normalization
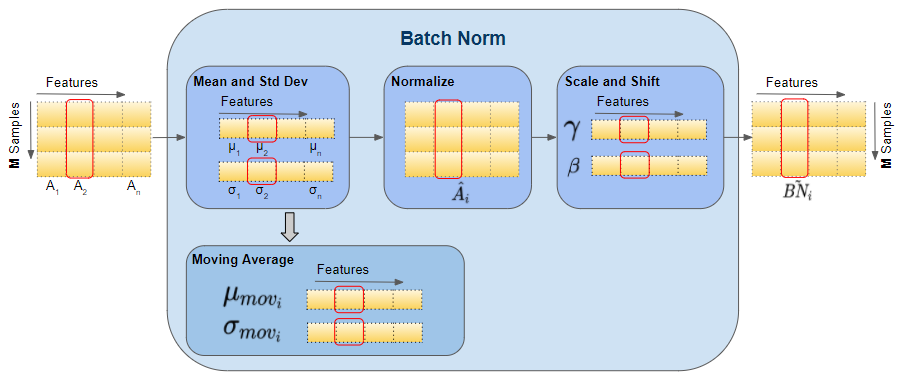
Batch normalization is an effective technique for training neural network models. Its goal is to normalize features so that each layer's outputs (the activations) have zero mean and unit variance. The opposite case is having nonzero mean activations. How does that affect training?
Nonzero means indicate activations are not centered around zero but are biased to positive or negative values. Combined with high variance, activations can become very large or very small. This is common in deep networks with many layers. If features are not within a stable range, optimization is affected because training relies on derivative calculations.
For a simple layer y = Wx + b, the derivative of y with respect to W involves x. Thus x directly influences gradient magnitudes. If x introduces unstable variation, gradients can become either too large or too small, leading to unstable learning. Batch normalization allows the use of higher learning rates during training.
Batch normalization also helps prevent activations from saturating after nonlinearities, ensuring activations are not excessively high or low. This improves weight learning and reduces sensitivity to parameter initialization.
Batch normalization can act as a form of regularization, helping reduce overfitting. When using batch normalization, excessive dropout is often unnecessary, since dropout could discard useful information; however, combining both techniques is still commonly recommended.

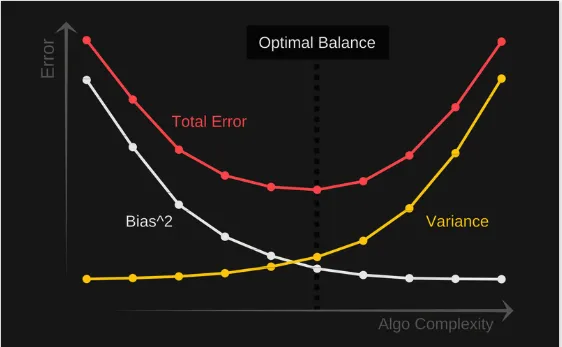
Question 2: Define bias and variance and describe their trade-off
Bias is the difference between the model's average predictions and the true values we want to predict. High bias indicates the model is not capturing the training data well; it is too simple and cannot achieve good accuracy on training and test data. This is called underfitting.
Variance describes how much the model's outputs vary for a given input. High variance means the model closely follows the training data and lacks generalization to unseen data. Such a model may perform well on the training set but poorly on the test set; this is overfitting.
The relationship between bias and variance can be illustrated as follows:
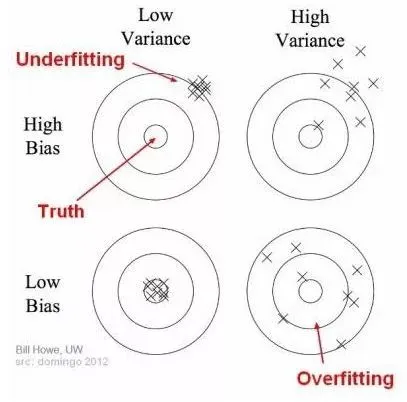
The center of the target represents a perfect predictor. As we move away from the center, predictions worsen. We can adjust the model to increase the concentration of its guesses near the center. Bias and variance must be balanced: a model with too few parameters tends to have high bias and low variance, while a model with many parameters tends to have low bias and high variance. This trade-off underlies choices about model complexity.
Question 3: Given 10 million face vectors, how do you find a new face most quickly?
This practical question focuses on indexing methods. One-shot learning for face recognition converts each face to a vector; recognizing a new face becomes a nearest-neighbor search for the most similar vector. Typically, triplet-loss-based models are used to obtain these vectors.

Computing distances to 10 million vectors on every query is inefficient. We need indexing strategies in the vector space so queries are faster. The main idea is partitioning the data into simpler structures, often tree-like, to quickly find nearest vectors for a new input.
Common approaches include locality-sensitive hashing (LSH), Annoy indexing, and Faiss for approximate nearest neighbor search.
Question 4: Is accuracy sufficient for classification? Which metrics do you use?
Accuracy is simple: the number of correct predictions divided by total predictions. However, accuracy can be misleading on imbalanced datasets. For example, if attack requests are 1 in 100,000 and a model predicts every request as benign, accuracy would be very high despite failing to detect attacks. Accuracy does not reveal per-class performance.
Use a confusion matrix to show actual versus predicted classes:
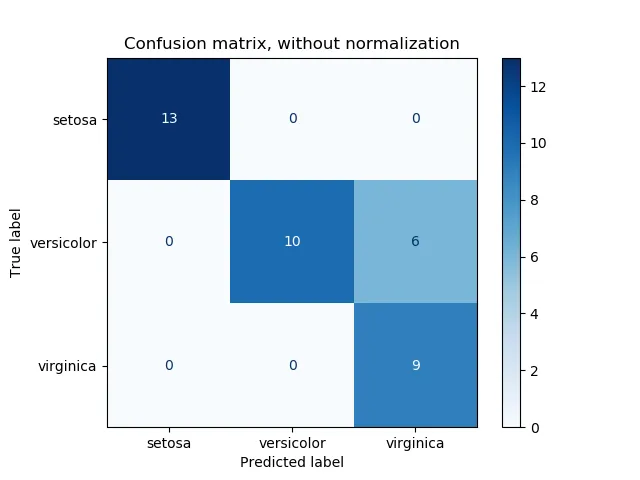
In addition to true positives and false positives across thresholds, the receiver operating characteristic (ROC) curve helps assess model effectiveness. An ROC curve closer to the top-left corner indicates higher true positive rate and lower false positive rate.
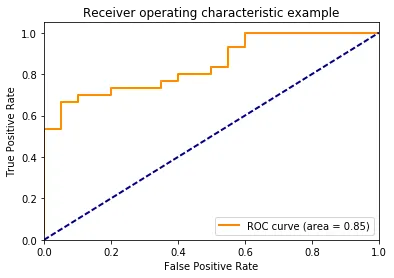
Question 5: How do you understand backpropagation? Explain the mechanism
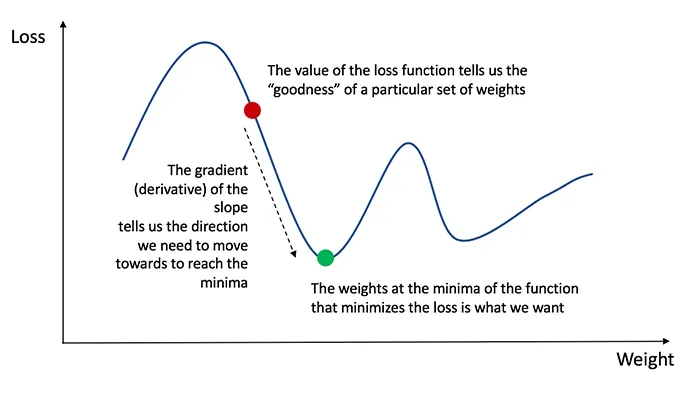
The forward pass computes layer outputs and produces a prediction yp. The loss function L(yp, yt) measures the difference between predictions and true labels yt. Training aims to minimize this loss.
Backpropagation computes gradients of the loss with respect to each layer's parameters using the chain rule. Optimizers such as Adam, SGD, and AdaDelta use these gradients to update network weights via gradient descent, propagating gradients from the output layer back to the input layer.
Question 6: What are activation functions and what are saturation regions?
Activation functions introduce nonlinearity to neural networks. They act as filters deciding whether information passes through a neuron. Activations affect gradient slopes and thus the trainability of neurons. Common activation functions include sigmoid, softmax, tanh, and ReLU. Most are continuous and differentiable, so small input changes produce small output changes.
Saturation regions occur where input changes no longer produce output changes. Functions like tanh, sigmoid, and ReLU have such regions:
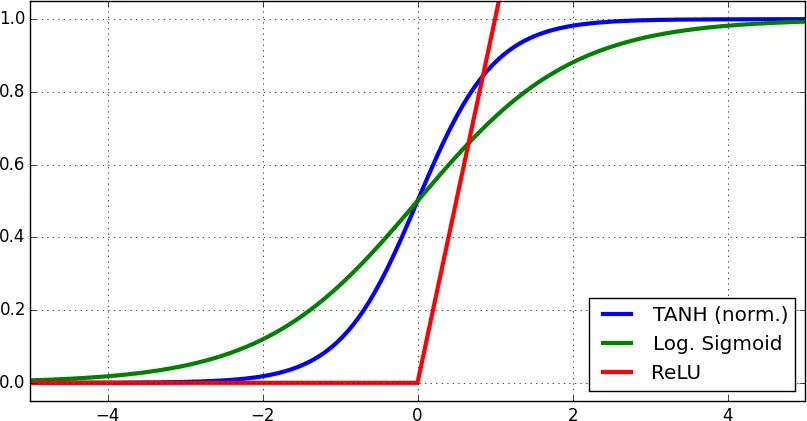
Saturation causes two problems. In the forward pass, layers falling into saturation may produce many identical outputs, causing covariate shift. In the backward pass, derivatives in saturation regions may be near zero, preventing learning. This is one reason batch normalization is used to keep values centered around zero.
Question 7: What are hyperparameters? How do they differ from parameters?
Model parameters are values learned from training data that capture relationships between inputs and outputs. For example, in linear models the coefficients w1, w2, ... are parameters. Characteristics of parameters:
- Used to predict new data;
- Reflect model capability (e.g., accuracy);
- Learned directly from the training dataset;
- Not set manually.
Hyperparameters, by contrast, are set outside the training process and are not learned from the training data. They guide training and model selection and are typically chosen manually or by heuristic search. Examples include learning rates for neural network training, C and sigma for SVMs, and k in k-nearest neighbors. Since the optimal hyperparameters are unknown a priori, techniques like grid search are used to estimate suitable ranges.
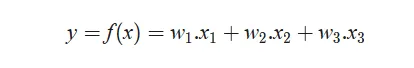
Question 8: What happens if the learning rate is too high or too low?
If the learning rate is too low, training is very slow because weight updates are tiny; many updates are needed to reach a local optimum. If the learning rate is too high, the model may fail to converge because updates overshoot the optimum, causing the parameters to oscillate around the optimum rather than settle.
Question 9: If input image dimensions double, how many times more parameters does a CNN have? Why?
This question can be misleading because many assume parameters scale with input size. However, CNN parameter count depends on filter sizes and counts, not input image dimensions. Doubling the input dimensions does not change the number of parameters in convolutional layers.
Question 10: How do you handle imbalanced data?
Real-world datasets are often imbalanced. Techniques to address imbalance include:
- Choose appropriate evaluation metrics: accuracy is often inappropriate; use precision, recall, F1 score, AUC, etc.;
- Resample the training set: undersampling, oversampling, bootstrapping, or SMOTE to create a more balanced training set;
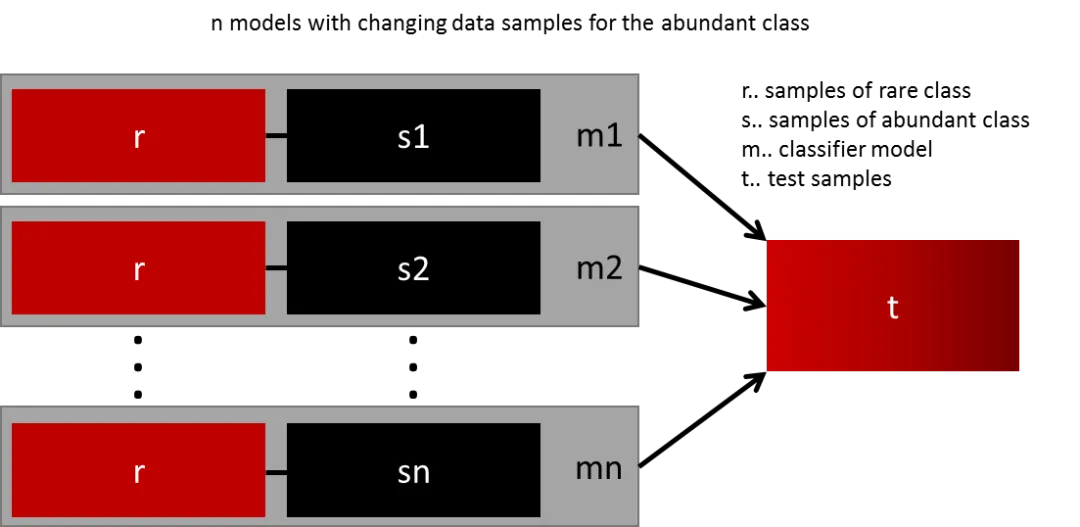
- Ensemble different models: for example, train multiple classifiers each using all minority class samples paired with a subset of majority class samples, then combine results;
- Redesign the loss function: apply class-weighted penalties in the cost function to penalize the majority classes more, forcing the model to better learn the minority class.
Question 11: What are epoch, batch, and iteration?
- Epoch: one pass through the entire training dataset;
- Batch: a subset of the dataset used when the whole dataset cannot be fed to the network at once;
- Iteration: the number of batches needed to complete one epoch. For example, with 10,000 images and batch_size 200, one epoch has 50 iterations (10,000 / 200).
Question 12: What is a data generator and why use it?
Generator functions are useful in programming to produce data for each training batch on the fly. Data generators help train on large datasets without loading the entire dataset into RAM, avoiding memory waste or overflow and reducing preprocessing time for inputs.

Summary
These are 12 common deep learning interview questions I often ask. Questions may vary based on each candidate's background, and other experience-based questions may also appear. Technical knowledge is important, but attitude matters as well. In addition to building skills, present yourself honestly, proactively, and modestly to improve your chances in an interview.





