 ALLPCB
ALLPCB


01. CUDA architecture supports accelerated AI compute ecosystem
GPUs are well suited to processing large datasets largely because of their CUDA cores. Originally, GPUs were specialized processors for graphics, capable of handling compute-intensive tasks required by high-resolution 3D graphics. By around 2012, GPUs evolved into highly parallel multicore systems able to process large amounts of data. In short, CPUs focus on serial linear computation while GPUs excel at parallel computation where data elements are often independent. The fundamental difference lies in CUDA cores: the more CUDA cores, the higher the compute performance. A GPU typically has hundreds to thousands of CUDA cores compared with a CPU. For example, the AMD EPYC 7003 series 7763 has 64 cores, while the NVIDIA A100 40GB has 6912 CUDA cores.
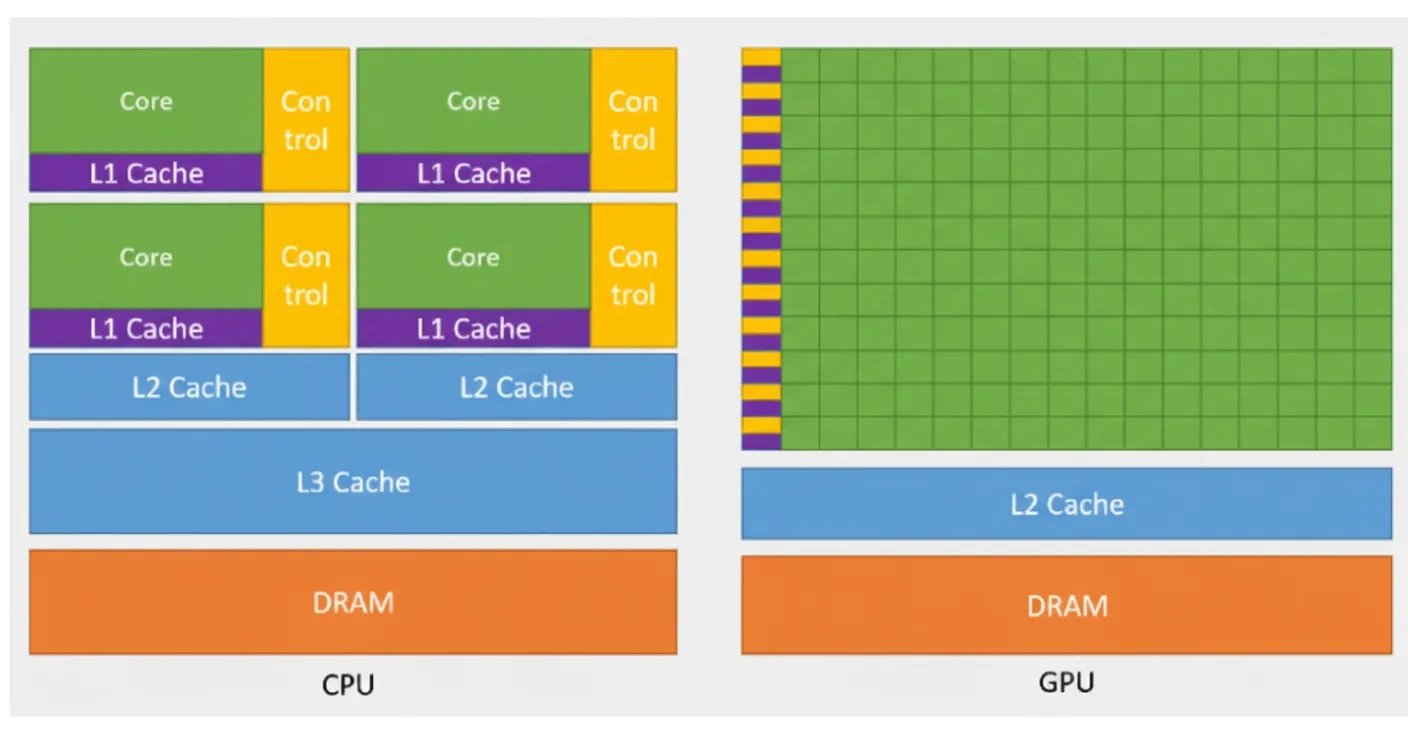
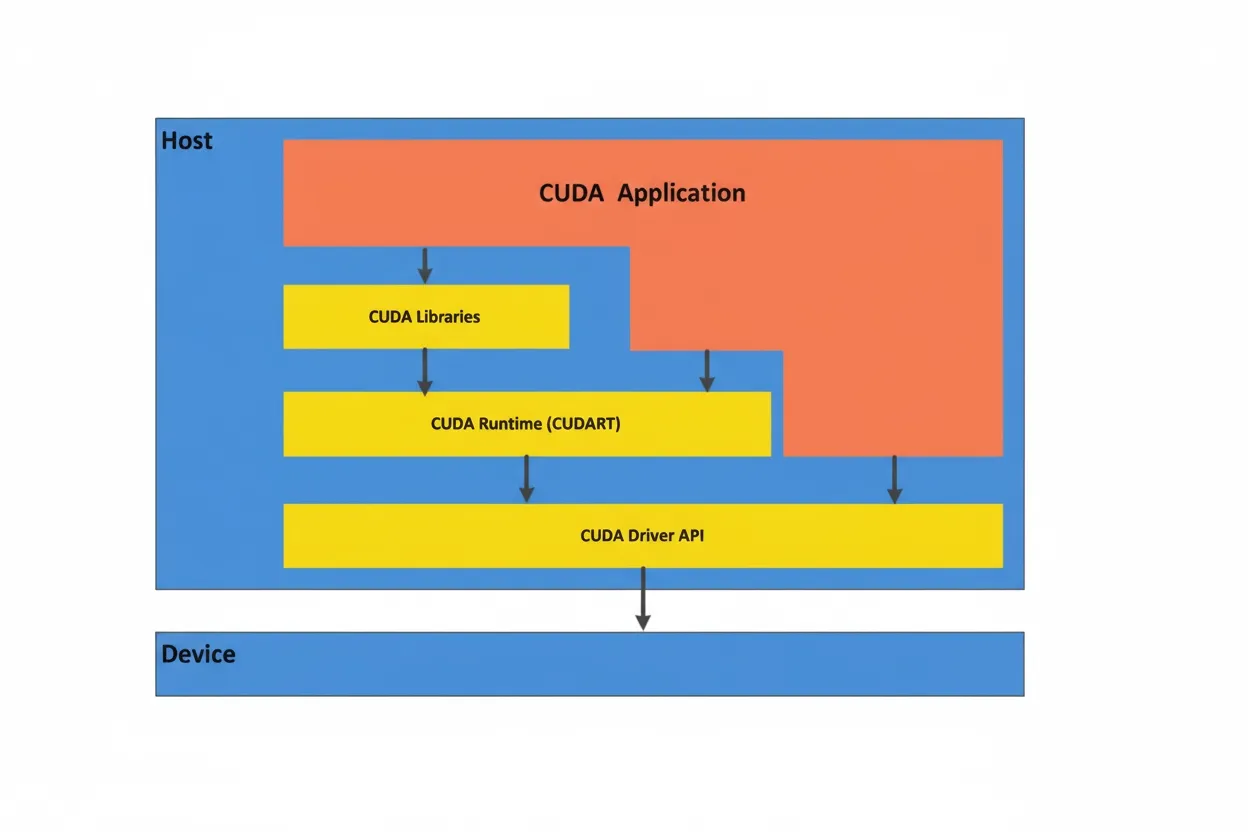
CUDA is essentially "software-defined hardware" that enables software to invoke hardware. CUDA is a parallel computing platform and programming interface that allows software to use GPUs for general-purpose processing, a model known as general-purpose GPU computing (GPGPU). CUDA exposes the GPU instruction set and parallel compute elements through a software layer for executing compute kernels. GPUs supported by CUDA can also use programming frameworks such as HIP by compiling code for CUDA. By consolidating previously disparate code paths into a single workflow, CUDA greatly accelerates model training development. Conceptually, CUDA acts like a compiler that maps software code to hardware-level assembly, forming a key part of NVIDIA's software-hardware ecosystem.
CUDA accelerates compute and deep learning: GPU workloads derived from graphics algorithms are often algorithmically intensive, highly parallel, and staged with simple control flow. CUDA extends GPUs beyond graphics by providing frameworks and libraries that leverage parallel compute for efficient implementations of matrix operations, convolutions, and other tasks common in deep learning. This simplifies deep learning programming and improves development efficiency and code quality. In GPU-accelerated applications, the serial portions run on the CPU while compute-intensive parts run in parallel across thousands of GPU cores, significantly improving compute efficiency. For example, the NVIDIA H100 GPU has up to 14,592 CUDA cores, far exceeding the 96 cores of an AMD EPYC Genoa-X CPU.
02. NVLink and NVSwitch enable fast, scalable interconnects
Faster, more scalable interconnects are a critical requirement: as computing demands in AI and high-performance computing grow, there is increasing need for multi-node, multi-GPU systems that provide seamless, high-speed communication between GPUs. Scalable, high-bandwidth interconnects are essential to build end-to-end computing platforms that meet performance requirements. As model complexity increases, a single GPU is often insufficient for training tasks; multiple GPUs and even multiple servers must be combined into clusters that exchange data between GPUs and between servers. Data transfer capability is therefore a key aspect of large-model compute cluster performance.
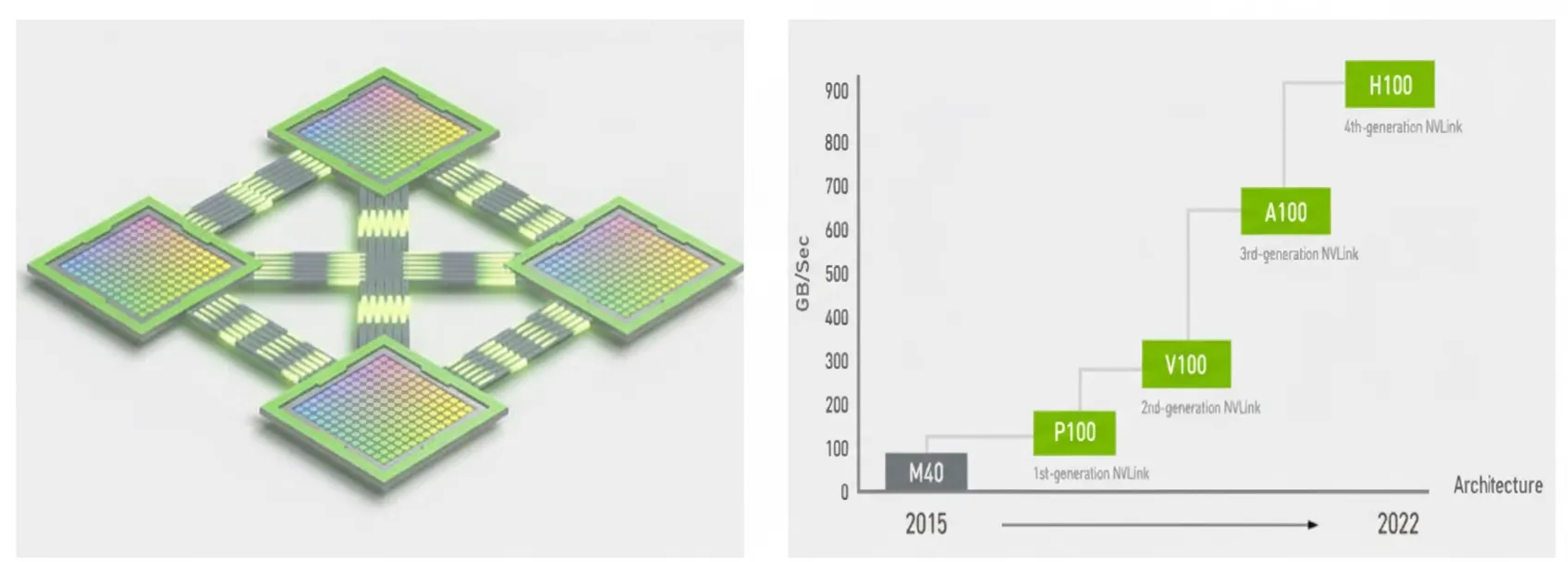
NVIDIA introduced NVLink to replace traditional PCIe for GPU interconnects. The fourth-generation NVLink provides up to 1.5 times the bandwidth of prior generations and enhanced scalability for multi-GPU configurations. A single NVIDIA H100 Tensor Core GPU supports up to 18 NVLink connections, for a total bandwidth of 900 GB/s, which is seven times the bandwidth of PCIe 5.0. Systems such as NVIDIA DGX H100 use this technology to increase scalability and accelerate deep learning training.
NVSwitch works with NVLink to build high-speed connectivity: NVSwitch is a high-speed switch technology that directly connects multiple GPUs and CPUs to form a high-performance computing system. Each NVSwitch has 64 NVLink ports and includes the NVIDIA SHARP engine for in-network reduction and multicast acceleration.
03. InfiniBand and network design enable efficient interconnects
IB switches implement the InfiniBand network standard, whereas Ethernet switches use the Ethernet protocol. InfiniBand networks provide high throughput and low latency. Mellanox was a leading InfiniBand switch vendor and was acquired by NVIDIA in 2020 for $6.8 billion. In current large-model deployments, particularly for training, NVIDIA's network configurations are widely used. Industry networks built around NVIDIA A100 and H100 GPUs commonly pair them with InfiniBand switches.
Example configurations:
- DGX A100 SuperPOD basic deployment: 140 servers (8 GPUs per server) plus switches (40 ports per switch, 200G per port). Network topology is an InfiniBand fat-tree; switch rate is 200 Gb/s. Switches in this configuration are typically Mellanox HDR 200 Gb/s InfiniBand switches.
- DGX H100 SuperPOD basic deployment: 32 servers (8 GPUs per server) plus 12 switches. Network topology is an InfiniBand fat-tree; switch port rate is 400G, which can be combined to form 800G ports. Switches in this configuration are typically NVIDIA Quantum QM9700 switches.
Ethernet is a widely used network protocol, but its throughput and latency may not meet the demands of large model training. In contrast, end-to-end InfiniBand networks can provide up to 400 Gbps and microsecond-level latency, making InfiniBand a preferred network technology for large-model training.
InfiniBand networks establish a single connection fabric between storage, network, and server devices through central InfiniBand switches that control traffic. This reduces data congestion between hardware devices and addresses communication bottlenecks in traditional I/O architectures. InfiniBand can also connect remote storage and network devices.
End-to-end InfiniBand deployments support data redundancy and error correction mechanisms to ensure reliable data transmission. When handling large datasets for model training, transmission errors or data loss can interrupt or ruin training, so transmission reliability is critical. InfiniBand networks help provide that reliability.





