 ALLPCB
ALLPCB


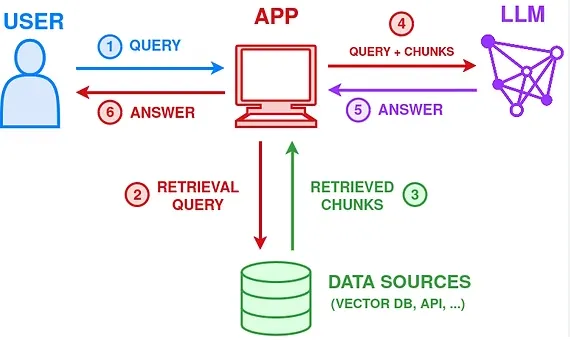
Introduction
RAG (retrieval-augmented generation) retrieves information fragments relevant to a user query and uses a large model to synthesize an answer. This approach addresses issues such as model hallucination and outdated knowledge and is widely used for deploying large models in practical systems.
Problem Statement
During retrieval, systems often return fragments that are highly similar to the query but either do not contain the correct answer or contain distracting, incorrect answers.
Key Findings
- LLMs are more affected by irrelevant fragments that are highly semantically related to the query than by semantically unrelated irrelevant fragments.
- As the number of irrelevant fragments increases, LLMs become more distracted and their ability to identify the correct information decreases.
- Model robustness to irrelevant fragments varies by question format: free-form Q&A is least affected, yes/no questions are more affected, and multiple-choice questions are most affected.
- Adding system prompts that instruct the model to "ignore irrelevant fragments" yields a small improvement in recognition ability.
- When highly semantically related but answer-irrelevant fragments are present, chain-of-thought (COT) reasoning or in-context learning (ICL) can cause LLMs to overthink and perform worse.
Data and Fragment Construction
The study categorizes answer-irrelevant fragments into three types:
- Irrelevant: Paragraphs that are unrelated to the question topic but score highly on similarity metrics.
- Partially related: Paragraphs that score highly on similarity metrics and partially overlap with the question topic.
- Related: Paragraphs that score highly on similarity metrics and overlap with the question topic, but do not contain the correct answer.
Similarity scores were computed using the Contriever model. In many cases, the related and partially related fragments scored higher than the true evidence fragment, which validates the data construction approach.
Evaluation Metrics
- Misrepresentation Ratio (MR): The proportion of cases where the LLM changes a correct answer due to influence from irrelevant information. MR measures the tendency of LLMs to be misled by irrelevant fragments.
- Uncertainty Ratio (UR): The proportion of responses in which the LLM expresses uncertainty after being exposed to irrelevant fragments. UR measures the model's confidence after interference.
For evaluation convenience, the experiments use a multiple-choice setup where the model selects among "correct answer", "wrong answer", or "uncertain".
Experimental Results
Models were evaluated across the three semantic relevance levels. As fragment relevance increases, model performance declines and the models show greater confidence in the (interfered) incorrect answers. Closed-source models outperformed open-source models in these tests.
Note: The open-source evaluation in the study included only Llama 2 7B, so broader open-source coverage was limited.
Effect of Number of Fragments
Increasing the number of irrelevant fragments worsens distraction. As more irrelevant fragments are added, models are more likely to choose an unrelated answer.
Question Format Comparison
Using multiple-choice format simplifies evaluation. The study also compared other formats and found:
- Free-form Q&A is least affected by irrelevant fragments.
- Yes/no style questions are more affected than free-form Q&A.
- Multiple-choice questions are most affected by irrelevant fragments.
For free-form responses, the study used GPT-3.5 to align answers to the multiple-choice options. A manual check of 300 samples found a 97% alignment accuracy, indicating the alignment process was reliable.
Prompting and Reasoning Methods
Prompts instructing models to ignore irrelevant fragments produced a small improvement. However, chain-of-thought (COT) prompting and combining ignore-prompting with in-context learning (ICL) degraded performance when highly related irrelevant fragments were present, causing models to overthink and reduce accuracy.
Conclusion
This study provides an empirical analysis of how retrieved fragments that are irrelevant to the answer can skew LLM outputs in RAG systems. The results highlight the importance of retrieval quality and of careful use of reasoning and prompting strategies when integrating retrieved context into generation.





