 ALLPCB
ALLPCB



1. Introduction: What is embodied intelligence?
Have you considered that AI might move beyond screens to operate in the physical world, perceiving, deciding, and acting like a human? In an intelligent warehouse, robots can plan paths autonomously to pick and pack items. In homes, future service robots may do more than vacuuming: they could tidy rooms, wash dishes, or open windows. These capabilities fall under embodied intelligence (Embodied AI), which aims to give AI a body and the ability to act, perceive the environment, understand human instructions, and execute sequences of operations.
Specifically, embodied intelligence sits at the intersection of artificial intelligence, robotics, and cognitive science. It studies how to provide robots with human-like perception, planning, decision making, and behavioral capabilities. Unlike purely computational AI (such as language models or image classifiers), embodied intelligence emphasizes the interaction between a physical body and its environment, using a physical agent to perceive and model the environment, plan and decide according to task goals and the agent's capabilities, and finally use motion capabilities to complete tasks. This enables AI to perform tasks in real-world scenarios.
Embodied intelligence is applicable across many domains:
- Industrial automation: robotic arms perform precise grasping, assembly, and welding to improve production efficiency.
- Home services: service robots perform cleaning, delivery, and eldercare assistance to improve quality of life.
- Medical assistance: surgical and rehabilitation robots support complex procedures and patient recovery training.
- Exploration and rescue: autonomous robots enter hazardous areas for detection and rescue operations.
- Education and entertainment: educational robots assist teaching and companion robots provide social interaction.
The transition from "brain-only AI" (for example, ChatGPT or Co-pilot) to "hands-on AI" (for example, intelligent robotic arms and household robots) is an important direction for AI development. As hardware costs fall, algorithms improve, and data accumulates, embodied intelligence will become a key driver in applied AI.
2. Challenges in embodied intelligence development
Despite its potential, developing embodied intelligence faces several challenges. Real-world embodied tasks are complex. Even a seemingly simple task like "open a door" can present multiple difficulties for developers:
- Scene construction: build a physical scene in simulation and define the door's physical properties and initial state.
- Action design: design how to move the robotic arm, how to grasp the door, and how the door should open.
- Training code: implement reward functions, tune hyperparameters, and perform extensive reinforcement learning training and tuning.
Each step requires significant manual effort, leading to long development cycles and low efficiency. Moreover, each new skill often requires rebuilding much of the pipeline. For example, to teach a robot to "close a window" or "hand a cup," developers may need to recreate the simulation scene, reconfigure action parameters, and revise training logic. Overall, three major obstacles hinder embodied intelligence development:
- High labor cost: each new skill can take a specialized team weeks or months, involving simulation design, motion planning, and algorithm tuning.
- Low reusability: environments, actions, and reward functions designed for one task are hard to reuse for others.
- Poor scalability: as task complexity grows (for example, from single-object grasping to multi-object coordination), development difficulty increases dramatically, impeding rapid iteration.
As a result, many embodied intelligence studies focus on a few fixed tasks and struggle to scale quickly.
3. Using large language models to build a skill generator
Large language models (LLMs) have shown strong capabilities in language understanding, knowledge reasoning, and code generation. To address the challenges above, it is possible to apply "natural language + general reasoning" capabilities of LLMs to embodied system development and automate the skill development pipeline to reduce cost and improve efficiency.
Based on several LLM-driven open solutions and tailored to robotic arm tasks in embodied intelligence, we developed an embodied AI simulation generation system that automates the flow from task description to skill learning.
Concretely, we use LLMs with strong language understanding and general reasoning to generate new skill tasks. We designed high-quality prompt templates so the model can interpret task requirements, convert natural language descriptions into executable simulation tasks, and produce all necessary artifacts for task training. This automates much of the robotic arm skill development pipeline.
In short, the system converts a natural-language task specification into a complete execution plan: scene configuration, action sequence, reward functions, and simulation setup, enabling end-to-end generation of training configurations for robotic skills.
The system can automatically perform the following tasks:
| Task | Description |
|---|---|
| Generate skill task descriptions | Create multiple robotic-arm task descriptions based on target objects |
| Generate simulation environment configuration | Produce positions and properties of target objects for MuJoCo environments |
| Generate task operation steps | Decompose a skill into an executable action sequence for the robotic arm |
| Generate primitive action sequences | Break complex actions into the robotic arm's basic action primitives |
| Generate reward function code | Produce reinforcement learning reward function logic |
| Generate object initial states | Provide default initial values for object joints and states |
With this pipeline, manual authoring of MuJoCo XML scene files, configuration parameters, and training code is greatly reduced. The user needs only to specify which objects in the scene are manipulable; the LLM then generates multiple tasks for the robotic arm, outputs full training configurations, and the MuJoCo engine can launch simulations so the arm can learn those skills.
For demonstration, the system uses a kitchen scene. An example virtual kitchen scene is shown below.

The overall system workflow comprises two main phases: task generation and task execution, as shown below.
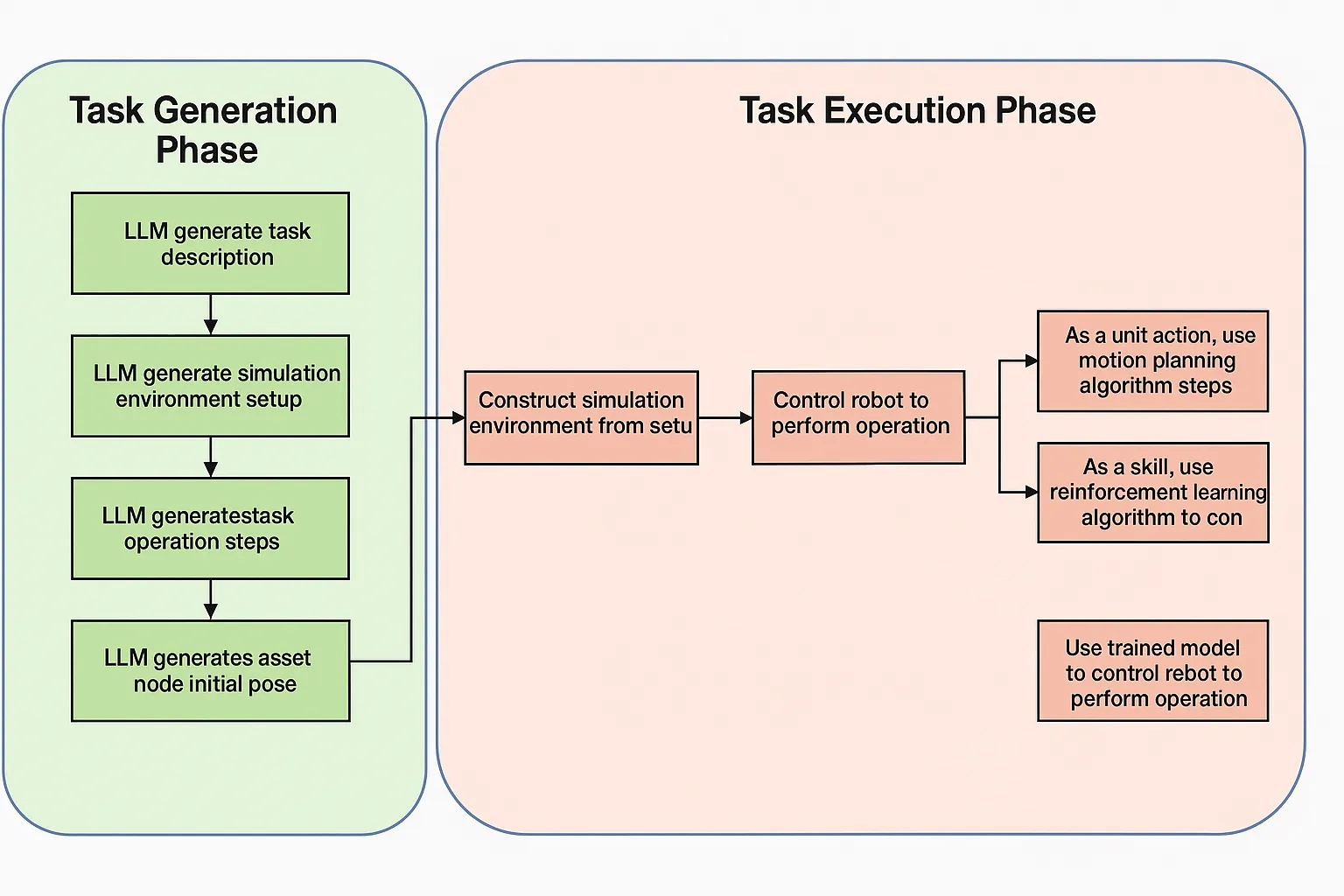
3.1 Task generation phase
During task generation, carefully designed prompts call the LLM multiple times to produce skill task descriptions, simulation environment configurations, robotic action steps, and object initial states. Each generated artifact serves a specific role:
Skill task description generation
The LLM generates multiple robotic arm task descriptions from object attribute information in the scene. The task descriptions include task name, detailed description, target object names, and joint names involved in robot-object interaction. Example for a microwave door task:
Task Name: Open Microwave DoorDescription: The robotic arm will open the microwave door.Additional Objects: NoneBodies:- microdoorroot: from the semantics,this is the door of the microwave. The robot needs to approach this door in order to open it.Joints:- microdoorroot_joint: from the articulation tree,this is the hinge joint that connects microdoorroot. Therefore, the robot needs to actuate this joint for opening the door.Simulation environment configuration generation
The LLM generates object configuration information for the simulation environment based on task descriptions and object attributes, including object names, spatial positions, and mobility flags. The LLM returns the configuration in YAML format. Example for the microwave door task:
- center: (0.6, 0.4, 1.6) movable:false name: microwave type: xml- center: (0.82, 0.16, 2.3) movable:false name: slidecabinet type: xml- center: (0.6, 0.4, 2.141) movable:true name: mug type: xml- task_description: The robotic arm will open the microwave door task_name: Open Microwave DoorTask operation step generation
The LLM uses task descriptions, object attributes, the robotic arm's available primitive actions, and environment state query functions to produce a sequence of steps the arm should perform. For each step, the LLM classifies the action type as either a primitive action or a reinforcement-learning action. For primitive actions, it outputs a primitive action sequence; for reinforcement-learning actions, it generates Python reward function logic. Example steps for opening a sliding cabinet door:
[sub] step1: move to the slidecabinet doorsubstep2: grasp the slidecabinet doorsubstep3: open the slidecabinet doorsubstep4: release the slidecabinet doorObject initial state generation
The LLM generates default joint angles and other initial state values for objects at environment initialization. For example, in a sliding door task, the door joint should be initialized to the closed state (0 indicates closed, 1 indicates open). Example:
jointvaluesslidedoor_joint:03.2 Task execution phase
After generation, the system uses the LLM-produced environment configuration, action steps, and joint values to construct the simulated environment via the MuJoCo engine and control the robotic arm according to the generated steps. The system executes primitive actions and also runs reinforcement learning training and inference where applicable. The simulation engine renders the task execution and saves it as a video, for example:

4. Advantages compared with traditional development
Compared with manual development, this automated approach offers several advantages. It enables non-experts to specify robotic tasks in natural language while helping professional teams accelerate development and prototype validation.
| Comparison | Traditional process | Automated system |
|---|---|---|
| Development time | Weeks | Hours to prototype |
| Manpower | Multiple engineers collaborating | Single developer possible |
| Extending tasks | Manual repeated work | Rapid iteration for new tasks |
| Reusability | Low | Highly modular and structured |
| Technical barrier | High specialist requirements | Language-driven, lower barrier |
Technical highlights include:
- Prompt engineering: a set of prompt templates for embodied tasks to improve LLM output accuracy and consistency. Prompts guide the model to clarify object properties and action logic.
- Modular generation: tasks are decomposed into environment, action, and reward modules for structured generation, easier debugging, and reuse.
- Deep MuJoCo integration: generated configurations are compatible with the MuJoCo simulation engine, supporting efficient physics simulation and rendering.
- End-to-end training: generated reward functions and action sequences enable automated reinforcement learning workflows, allowing simulated robots to converge to effective policies.
The system is validated on the MetaX C-series GPU lineup and can perform LLM inference and reinforcement learning training efficiently on Xiyun C500 GPU hardware.
5. Open source
The project is released as open source. The repository includes complete code and examples, and the approach can be extended to wheeled robots, quadrupeds, humanoids, and more complex multi-task learning scenarios.
6. Conclusion
Over the past decade, AI has transformed many areas through perception, instruction following, and code generation. In the coming decade, AI will increasingly act within factories, homes, and hospitals. Embodied intelligence connects cognitive capabilities with physical interaction. This system aims to lower barriers to entry for exploring embodied intelligence by automating much of the development pipeline.





