ALLPCB
ALLPCB


Introduction
PPA (performance, power, area) is one of the key metrics used to evaluate a chip. Design trade-offs are typically evaluated along the three axes of performance, power, and area. At each stage of a design, engineers apply various techniques to improve these metrics as much as possible.
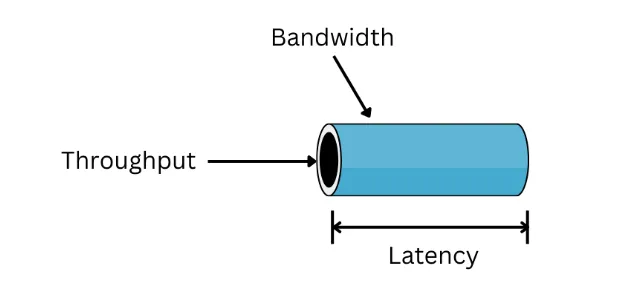
Performance Metrics: Bandwidth, Throughput, Latency
Before discussing how to improve performance, we need to define how performance is measured. Intuitively, better performance means faster operation. Across different chip types—communication (5G, Bluetooth, Wi?Fi), interface (USB, Ethernet, HDMI), and compute (CPU, GPU, AI)—performance can be characterized using three common metrics: bandwidth, throughput, and latency.
- Bandwidth: the maximum amount of data that can be transferred over a channel per unit time.
- Throughput: the effective amount of data successfully transferred over a channel per unit time during a given time interval.
- Latency: the time required for a single successful transfer.
These metrics apply both at the network level and at the micro level inside a chip, for example to bus transfers, memory accesses, and module-to-module data exchanges.
Take the AXI bus as an example. AXI is a high?bandwidth, high?performance, low?latency AMBA interface. Compared with other AMBA buses such as AHB and APB, AXI provides several features that improve bandwidth, throughput, and latency:
- Bandwidth:
- AXI supports wider bus widths. Wider buses transfer more data per cycle, analogous to widening a road.
- Throughput:
- Separate read and write channels enable read/write parallelism, increasing the amount of useful data transferred in the same time window.
- Outstanding transactions (pipelined/split transfers): starting a new transaction before the previous one completes allows more parallel operations over time.
- Burst transfers: a single address phase can access multiple consecutive addresses on the slave, increasing the data transferred per address phase.
- Out?of?order responses: relaxing strict ordering allows completed later transactions to return data immediately, improving overall throughput.
- Latency:
- Separate address and data channels reduce per?transaction latency, since address and data phases can proceed concurrently.
- Support for multiple masters and slaves with arbitration enables direct point?to?point transfers in one cycle, reducing latency compared with single?master buses like APB. Arbitration does add some overhead, but pipelining and split transactions help maintain performance.
Across these mechanisms the unifying ideas are acceleration and parallelism: to be faster you must complete more work within a given time.
Improving Performance: Acceleration and Parallelism
Acceleration reduces latency per operation through algorithmic optimization or hardware upgrades. Examples include removing redundant logic so an operation that previously took two cycles can be done in one, or using a more advanced process node to reduce gate delays.
Parallelism can be spatial or temporal. Spatial parallelism uses more physical resources to operate concurrently. Temporal parallelism schedules limited resources to minimize idle time over an interval.
Analogy: if a factory must finish a project in three days instead of a week, options include:
- Hire more workers: spatial parallelism.
- Reduce idle time and improve scheduling so existing workers are busier: temporal parallelism.
- Increase each worker's efficiency so tasks complete faster: algorithmic or hardware improvements.
In the AXI example, wider bus widths and separate channels represent spatial parallelism. Pipelining, split/burst transfers, and out?of?order responses represent temporal parallelism. Multi?master connectivity contributes to reducing overall latency.
Time Parallelism: Hiding Latency
This section focuses on temporal parallelism. Using AXI as an example, consider outstanding transactions.
'Outstanding' refers to transactions that have been issued but not yet completed. Without outstanding transactions, the bus executes one transfer at a time, so two reads must be serialized and take the sum of their latencies to complete.
A read involves both the master (M) issuing the request and the slave (S) returning data. If M is idle while waiting for S to respond, throughput is limited. With outstanding transactions, M issues a second request before the first completes, keeping M busy while S processes the first request.
In this example, completing two reads takes 80 ns instead of 100 ns: the 20 ns latency of S processing the first read is overlapped with M preparing and issuing the second read. That 20 ns is effectively hidden.
The overlap requires that S's response latency be shorter than M's time to prepare the next request; otherwise M will still stall waiting for S's ready signal. With stalls, total time increases; for instance, if M must wait 10 ns during the second transfer, three read operations could take 140 ns in total:
Buffers can decouple M and S so M can continue issuing requests without waiting for S to be ready. A simple buffer (BUF) stores pending requests; if S is very slow, a FIFO that preserves order can be used. With buffering, M can issue more requests while S consumes them as it becomes ready:
With such buffers, M avoids idle cycles and overall throughput increases. In AXI, when outstanding transactions are enabled, buffers between master and slave allow multiple in?flight transfers; slave ready signals correspond to buffer non?full indicators.
Outstanding transactions thus increase throughput by hiding latency. Latency components such as address computation on the master or DRAM access on the slave are often hard to reduce without major changes, so hiding latency via concurrency is an effective way to boost throughput.
Limits of Time Parallelism
Time parallelism is powerful but not unlimited. It works best when the master is the bottleneck. If the slave is consistently slower than the master, outstanding transactions will not increase the final completion time.
Although the master can issue three requests rapidly using outstanding transactions, the completion time is determined by the slave's processing speed, so total time matches the non?outstanding case.
This bottleneck is the classic "memory wall": CPU compute units (masters) have become faster, while DRAM access latency remains relatively large. Caching is the common solution: fast on?chip SRAM acts as an intermediary "fake" memory, reducing the effective latency to the slow DRAM.
Ideal Time Parallelism: Pipelining
From the outstanding example, both master and slave latencies affect parallelism efficiency. If the slave is slow, buffers help. If the master is also slow, is outstanding the best option? Consider a case where the slave has short latency and the master runs continuously; the slave may idle between requests. The ideal is a balanced pipeline where each stage finishes work just as the next request arrives:
If master latency and slave latency are matched, there is no idle time and the pipeline achieves maximum efficiency:
In real systems each module can be both a master and a slave. A request may pass through multiple intermediary slaves before reaching memory. In an ideal deep pipeline where each M/S pair is balanced, multiple tasks run concurrently and multiple latencies can be hidden:
To approach this ideal, designers manually split long?latency circuits into stages separated by registers. Each stage operates within one clock cycle and updates on clock edges, enabling high throughput. This is the classic pipeline technique: slice long delays and insert registers to allow simultaneous progress of multiple operations. Deeper pipelines generally yield greater throughput improvements.
Summary
This article introduced parallelism techniques focused on temporal concurrency: outstanding transactions and pipelining. These are examples of a general design philosophy: identify and eliminate idle or waiting periods in a data path to improve efficiency and throughput. Look for places in your design where waiting occurs; those are the opportunities for performance gains.