 ALLPCB
ALLPCB


Overview
Automatic speech recognition (ASR), also called speech-to-text, is a combination of processes and software that decodes human speech and converts it into digital text.
1. What ASR Does
ASR captures human speech and converts it into readable text. It removes the need for manual transcription and provides a foundation for machine understanding. As spoken language becomes more searchable and actionable, developers can apply higher-level analytics such as sentiment analysis. ASR is typically the first stage in conversational AI pipelines that enable natural language interaction with machines.
Typical conversational AI applications use three subsystems to process and transcribe audio: understanding the question (extracting meaning), generating a reply (text), and converting the reply back to speech. These steps are often implemented with multiple deep learning models working together.
First, ASR processes raw audio signals and transcribes text. Second, natural language processing (NLP) extracts meaning from the ASR output. Finally, text-to-speech (TTS) synthesizes human-like audio from text. Each stage requires one or more deep learning models, so optimizing the multi-step pipeline is complex.
2. Why Use ASR
Use of speech recognition and conversational AI is growing across industries, including finance and healthcare. Speech-to-text has many practical applications:
- Busy professionals such as surgeons or pilots can record notes and issue commands hands-free while working.
- Users who cannot use a keyboard, or who would be unsafe doing so while driving, can speak requests or dictate messages.
- Voice-driven phone systems can handle complex requests without requiring users to navigate menus.
- People with disabilities who cannot use other input methods can interact with computers and automated systems via speech.
- Automated transcription is faster and less expensive than manual transcription.
- Speech recognition is often faster than typing. A typical person can speak about 150 words per minute but may type only around 40 words per minute, and small smartphone keyboards can reduce typing speed further.
Speech-to-text is now common in smartphones and desktop computers and also used in specialized domains such as medicine, law, and education. As deployment expands across homes, cars, and offices, research and development in the field have intensified.
3. How ASR Works
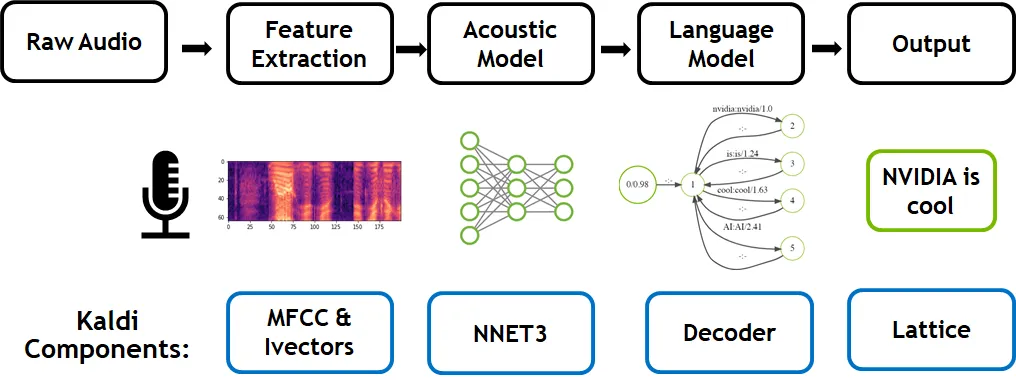
ASR is a challenging natural language task that comprises subproblems such as speech segmentation, acoustic modeling, and language modeling, producing a sequence of labels from noisy and unsegmented input. Deep learning has replaced traditional statistical ASR methods like hidden Markov models and Gaussian mixture models because it achieves higher accuracy in recognizing phonemes, the basic sounds that form speech. The introduction of Connectionist Temporal Classification (CTC) removed the need for pre-segmented data, allowing end-to-end training of networks for sequence labeling tasks such as ASR.
Typical ASR systems using CTC follow these steps:
Feature extraction: Extract useful audio features from the input and suppress noise and other irrelevant information. Mel-frequency cepstral coefficients (MFCC) capture spectral features from spectrograms or mel spectrograms.
Acoustic model: Feed the spectrogram into a deep learning acoustic model to predict character probabilities at each time step. During training, the acoustic model is trained on hundreds of hours of audio paired with transcriptions from datasets such as the LibriSpeech ASR Corpus, Wall Street Journal, TED-LIUM Corpus, and Google Audio set. The acoustic model outputs based on how words are pronounced, which may produce repeated characters.
Decoding: A decoder and a language model convert characters into word sequences. Words can be buffered into phrases and sentences, segmented appropriately, and passed to subsequent stages.
Greedy (argmax) decoding is a simple decoder strategy that selects the most probable symbol at each time step from the Softmax output without considering semantic context. Repeated characters are collapsed and blank tokens are removed.
A language model can add context to correct acoustic model errors. A directed search decoder weights the relative probabilities from the Softmax output with the probability of particular words occurring in context, attempting to match the acoustic model output to likely next words.
4. Deep Learning and GPU Acceleration for ASR
Innovations like CTC integrated ASR into the deep learning domain. Popular deep learning models for ASR include Wav2letter, DeepSpeech, Listen, Attend and Spell (LAS), and Jasper, a toolkit from NVIDIA research for speech applications. Kaldi is a C++ toolkit that supports both traditional methods and deep learning modules.
GPUs with hundreds of cores can process thousands of threads in parallel. Neural networks are built from many identical neurons, giving them high inherent parallelism that maps well to GPUs. This parallelism delivers much faster computation compared to CPU-only training. For example, GPU-accelerated Kaldi can run 3,500 times faster than real-time audio and about 10 times faster than CPU-only solutions. Such performance makes GPUs the preferred platform for training deep learning models and running inference.
5. Industry Applications
Healthcare
One challenge in healthcare is limited access and long waits when calling medical offices or contacting claims representatives. Conversational AI and chatbots trained for healthcare are an emerging technology intended to address workforce shortages and open communication channels with patients.
Financial Services
Conversational AI is used to build chatbots and assistants for financial services companies.
Retail
Chatbot technology is widely used in retail to analyze customer queries and generate replies or recommendations, streamlining customer workflows and improving store operations.
6. NVIDIA GPU-Accelerated Conversational AI Tools
Tools exist to simplify conversational AI deployment, including NVIDIA NeMo and NVIDIA Riva. The NGC software registry provides pretrained ASR models, training scripts, and performance results.
NVIDIA NeMo is a PyTorch-based toolkit for developing conversational AI applications. It supports rapid experimentation by composing modular deep neural network components. NeMo modules typically represent data layers, encoders, decoders, language models, loss functions, or activation functions. Reusable components are available for ASR, NLP, and TTS, which simplifies building complex architectures and systems.
NGC provides NeMo resources such as pretrained models, training and evaluation scripts, and end-to-end NeMo applications that enable experimentation with different algorithms and transfer learning on domain-specific datasets.
NVIDIA also provides domain-specific NeMo ASR applications to support training or fine-tuning pretrained acoustic and language models on a user’s own data, enabling stepwise creation of higher-performance ASR models for specific datasets.
7. NVIDIA GPU-Accelerated End-to-End Data Science
NVIDIA RAPIDS, an open-source suite of software libraries built on CUDA, enables end-to-end data science and analytics to run entirely on GPUs while maintaining familiar APIs such as Pandas and scikit-learn.
8. GPU-Accelerated Deep Learning Frameworks
GPU acceleration in deep learning frameworks provides flexibility for designing and training custom neural networks and offers programming interfaces for common languages such as Python and C/C++. Widely used frameworks like MXNet, PyTorch, and TensorFlow rely on NVIDIA GPU libraries to deliver high-performance multi-GPU training.





