 ALLPCB
ALLPCB


Overview
Random forest is a supervised learning algorithm that uses an ensemble of decision trees. The output is the consensus answer from many trees. Random forest can be applied to both classification and regression tasks.
What is a random forest?
Random forest is a mainstream ensemble learning method for classification and regression.
Ensemble learning combines multiple machine learning algorithms to produce a better model, applying collective intelligence to data science problems. The idea is that a group of individuals with limited domain knowledge can collectively produce a better solution than a single expert.
A random forest is a collection of decision trees. A decision tree answers questions about dataset elements by asking a series of yes/no questions about features. For example, to predict a person’s income, the tree might consider features such as whether the person is employed and whether the person owns a house. In algorithmic terms, the model searches features to split observations into groups that are as different as possible from each other while keeping members within each subgroup as similar as possible.
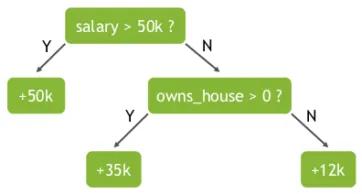
Random forest uses a technique called bagging to build full decision trees in parallel by randomly sampling the dataset and features with replacement. While individual decision trees are often prone to overfitting when built on a fixed set of features, randomness is critical to a forest's performance.
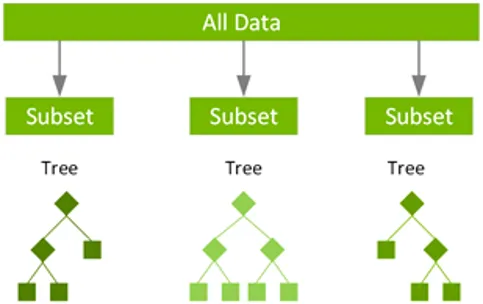
Randomness ensures low correlation between individual trees, reducing the risk of high variance. Having many trees also reduces overfitting, which can occur when a model incorporates too much noise from the training data and makes poor decisions.
With a random forest model, the probability of making a correct prediction increases as the number of uncorrelated trees grows. The overall result reflects the majority vote of the trees, which limits the damage any single tree's error can cause. Even if some trees are wrong, others will be correct, and the ensemble tends to move toward the correct outcome. Random forests can be computationally intensive when many features are considered, but even small models with a limited number of features often perform well.
How random forest works
Each tree in a random forest is trained on a randomly sampled subset of the training data in a process called bootstrapping or bagging. The model fits these smaller datasets and aggregates their predictions. Sampling with replacement allows multiple instances of the same datum to appear in a sample, so trees are trained on different datasets and also make decisions using different feature subsets.
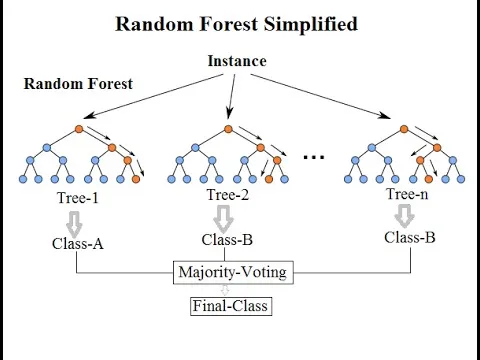
Use cases
Classification examples include:
- Fraud detection
- Spam detection
- Text sentiment analysis
- Predicting patient risk, sepsis, or cancer
Regression examples include:
- Estimating the amount of fraudulent activity
- Forecasting sales
Why choose random forest?
Main advantages of random forest models:
- Well suited for both regression and classification problems. In regression, the output variable is numeric, such as housing prices. In classification, the output is typically a class label.
- Can handle missing values and maintain high accuracy, even when a large portion of data is missing due to bagging and sampling with replacement.
- Because the algorithm outputs a majority vote, the model is less likely to overfit.
- Can handle datasets with thousands of input variables, making it useful for dimensionality reduction.
- Can identify highly important features from the training data.
Some drawbacks:
- Random forest often outperforms a single decision tree but can be less accurate than gradient-boosted ensembles such as XGBoost.
- Random forest models with many trees can be slower than optimized gradient-boosting implementations.
Gradient boosted decision trees
Gradient boosted decision trees (GBDT) are another ensemble decision tree method used for classification and regression. Both random forest and GBDT build models from multiple decision trees, but they differ in how the trees are constructed and combined.
GBDT uses boosting: it iteratively trains a set of shallow trees where each new tree fits the residual errors of the previous model. The final prediction is a weighted sum of all trees. Bagging in random forest reduces variance and overfitting, while boosting in GBDT reduces bias and underfitting.
XGBoost is a scalable, distributed variant of GBDT. In some implementations, trees can be constructed in parallel rather than strictly sequentially. XGBoost follows a layer-wise growth strategy, scanning gradient values and using them to evaluate split quality at each candidate split in the training data.
XGBoost is popular due to its broad use cases, portability, multi-language support, and cloud integration.
Compared with XGBoost, random forest accuracy can be affected by two error sources: bias and variance:
- Gradient boosting eliminates bias and variance through multiple boosting rounds with a low learning rate.
- Boosting hyperparameters also help reduce variance.
- Random forest controls bias and variance through tree depth and the number of trees.
- Random forest trees may need to be deeper than boosting trees.
- More data reduces both bias and variance.
GPU-accelerated random forest, XGBoost, and end-to-end data science
From an architecture perspective, CPUs have a few cores with large caches and can run a small number of software threads concurrently. GPUs have hundreds or thousands of cores and can run many thousands of threads in parallel.
The NVIDIA RAPIDS open-source software suite enables end-to-end data science and analytics workflows on GPUs. The suite relies on NVIDIA CUDA primitives for low-level compute optimization while exposing GPU parallelism and high-bandwidth memory through user-friendly Python interfaces.
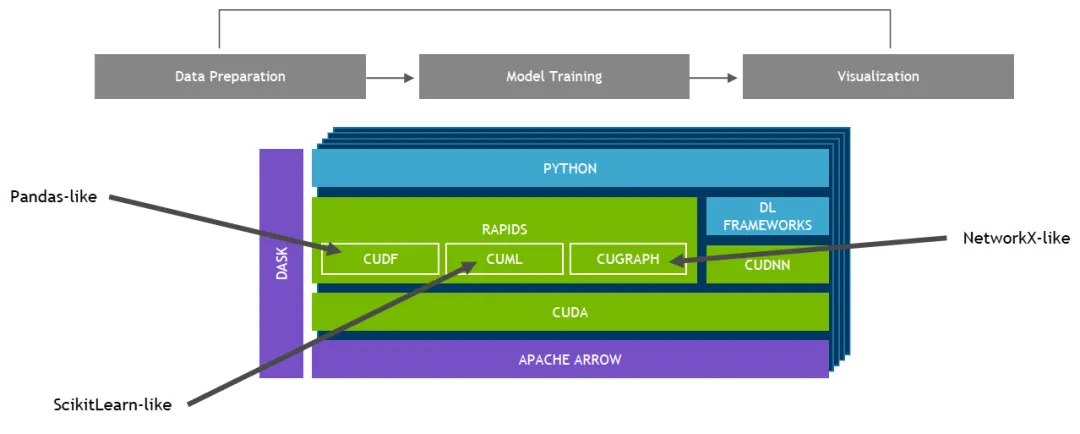
With RAPIDS cuDF, data can be loaded onto the GPU using a pandas-like interface and then used by connected machine learning and graph analytics algorithms without leaving the GPU. This level of interoperability is enabled by libraries such as Apache Arrow and can accelerate end-to-end workflows from data preparation to machine learning and deep learning.
RAPIDS machine learning algorithms and numerical primitives follow a scikit-learn-like API. Single-GPU and large data-center deployments support common tools such as XGBoost and random forest. For large datasets, GPU-based implementations can run 10x to 50x faster than equivalent CPU implementations.
The RAPIDS team has collaborated with the DMLC XGBoost project to provide GPU-accelerated XGBoost, offering embedded GPU acceleration that can significantly speed up model training and improve iteration time. Tests running XGBoost on systems with NVIDIA P100 accelerators and 32 Intel Xeon E5-2698 CPU cores showed up to a 4x speed increase compared with non-GPU systems at similar output quality. This speedup is valuable because data scientists often run XGBoost multiple times while tuning hyperparameters to improve accuracy.
Tags
- cpu(206166)
- gpu(126255)
- AI(263628)
- machine learning(130423)
- decision trees(13339)





