 ALLPCB
ALLPCB


Overview
In today's rapidly evolving artificial intelligence field, computing power is one of the key factors that determine model training and inference speed. To improve computational efficiency, multiple numeric precision formats have emerged, including FP64, FP32, FP16, TF32, BF16, int8, and mixed precision. This article gives a concise, easy-to-understand introduction to these precision formats and their differences.
What is precision?
Precision is an important attribute of data representation that determines numerical accuracy. In computer science, precision is commonly related to the number of bits used to represent a value. For floating-point numbers, precision depends on the storage format: the more bits used, the higher the precision.
To illustrate more intuitively, consider an example: if you earn 1 unit per second, your monthly income is 1 * 60 * 60 * 24 * 30 = 216,000. If you earn 1.1 units per second, the monthly income becomes 237,600. That 0.1 unit difference in the per-second value leads to a monthly difference of over 10,000 units, which shows how different precision can affect results.
Another common example is pi. It is often represented as 3.14, but higher precision uses many more digits after the decimal point.
Why use different precisions?
The need for different precisions comes down to cost and accuracy trade-offs.
Higher precision generally yields more accurate results but increases computation and storage costs. Lower precision reduces numerical fidelity but can significantly improve computational efficiency and throughput. Having multiple precision options allows selection of the most appropriate format for a given scenario. In artificial intelligence, different application scenarios have different precision requirements. For example, during deep learning training, a large amount of computation is required; using excessively high precision can greatly increase computation and training time, while using excessively low precision can harm model accuracy. Therefore, different precisions are used to balance accuracy and efficiency.
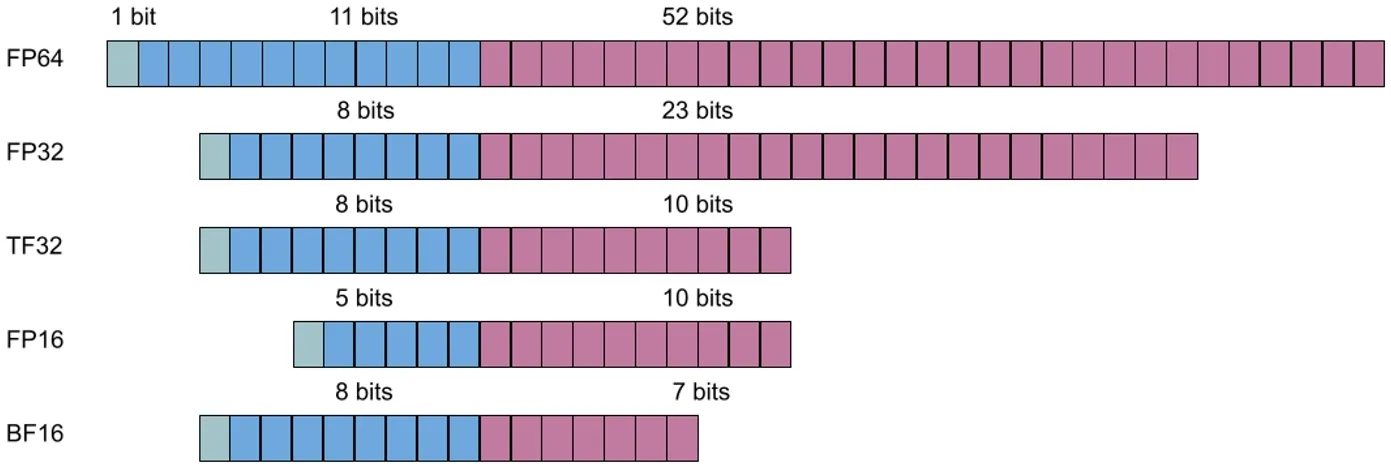
Precision categories and comparison
Computational precision refers to the numeric format used during calculations. It includes floating-point formats (half precision, single precision, double precision) and integer formats. Different precisions use different bit widths, which affects computation speed, numerical accuracy, and energy consumption.
FP64
Double-precision floating point occupying 64 bits. Commonly used in large-scale scientific computing, engineering simulations, financial analysis, and other domains that require strict numerical accuracy.
FP32
Single-precision floating point occupying 32 bits. Compared with double precision, it uses less storage and provides slightly lower accuracy. FP32 is widely used in scientific computing, graphics rendering, and deep learning training and inference. It offers a good balance between performance and precision for many general-purpose computation tasks.
FP16
Half-precision floating point occupying 16 bits. It significantly reduces storage requirements and further lowers precision. FP16 is commonly used for parameters and gradient computations during model training, in deep learning inference, graphics rendering, and some embedded systems, especially when memory and compute resources need to be conserved.
TF32
TF32 is a format introduced by NVIDIA for deep learning computations, used as an internal format for Tensor Core operations. It performs computations with precision characteristics similar to FP32 while benefiting from reduced storage and communication precision similar to FP16.
INT8
8-bit integer arithmetic, typically used for quantized deep learning model inference. INT8 has a much smaller representable range, but its computation is very fast and it can significantly reduce energy consumption and memory usage. INT8 is widely used in scenarios that require high efficiency and power-performance ratio, such as edge computing and AI inference on vehicles and mobile devices.
In training and inference of artificial intelligence models, choose the appropriate numeric precision based on model complexity and performance requirements. For models that do not require very high numerical accuracy, half precision (FP16) or single precision (FP32) can speed up computation; for workloads that demand very high accuracy, double precision (FP64) may be necessary.





