 ALLPCB
ALLPCB


Abstract
Key-value (KV) caches are widely used to accelerate large language model (LLM) autoregressive generation. However, cache memory grows with sequence length, turning LLM inference into a memory-constrained problem and limiting system throughput. Existing approaches either drop low-importance tokens or uniformly quantize all entries, which often incurs large approximation error when representing the compressed matrices. Error accumulation across autoregressive decoding steps further amplifies per-step errors, causing severe generation drift and degraded performance. To address this, the authors propose GEAR, an efficient KV cache compression framework that achieves high-ratio, near-lossless compression. GEAR first applies ultra-low-precision quantization to the majority of similarly scaled entries, then uses a low-rank matrix to approximate quantization residuals and a sparse matrix to correct individual outlier errors. By combining these three techniques, GEAR leverages their complementary strengths. Experiments show that, compared to alternatives, GEAR achieves near-lossless 4-bit KV cache compression, improves throughput by 2.38x, and reduces peak memory by 2.29x.
Q1: What problem does this paper address?
The paper introduces GEAR (Generative Inference with Approximation Error Reduction), a KV cache compression framework that targets the memory bottleneck in LLM inference. As model sizes and sequence lengths increase, KV cache memory consumption grows rapidly and becomes the main constraint on throughput. Existing methods that drop tokens or uniformly quantize entries typically introduce significant approximation error when compressing the cache. In autoregressive decoding, such errors accumulate over steps and can cause critical generation deviations.
GEAR addresses this challenge by combining three complementary techniques: ultra-low-precision quantization for the majority of entries, low-rank approximation to model quantization residuals, and a sparse correction matrix for outlier entries. Integrating these methods allows GEAR to maintain near-lossless accuracy while substantially increasing throughput and reducing peak memory usage. Reported results indicate up to 2.38x throughput improvement and up to 2.29x peak memory reduction compared with prior alternatives.
Q2: Related work
The paper cites several related areas:
- LLM weight compression: Methods that compress model weights to reduce memory and data transfer. Examples include GPTQ and SqueezeLLM, which use quantization to significantly reduce weight memory footprint.
- LLM activations and KV cache compression: Compressing activations and KV caches is more challenging because they are input-dependent and sensitive. Methods such as SmoothQuant and Atom adjust quantization schemes to reduce outlier errors and achieve near-lossless compression on simple generation tasks.
- KV cache pruning: Token-dropping approaches reduce cache size by pruning entries based on attention scores. Examples include H2O and FastGen, which propose attention-score-based KV pruning methods.
- KV cache quantization: Some works combine pruning and quantization to reduce KV cache size, for example SparQ.
- Low-precision quantization for weights and activations: Research on representing weights and activations in low precision to improve inference efficiency, such as Q8BERT and ZeroQuant for 8-bit and 4-bit quantization schemes.
These lines of work provide context and motivation for GEAR. GEAR builds on them and introduces a hybrid approach that attains efficient KV cache compression while preserving generation quality.
Q3: How does the paper solve the problem?
GEAR minimizes approximation error during compression by integrating three complementary components:
- Quantization: Apply ultra-low-precision quantization (for example, 4-bit) to most KV cache entries. This leverages the similar magnitudes present across most entries to compress them aggressively.
- Low-rank approximation: Use a low-rank matrix to approximate the residual error introduced by quantization. Implemented via singular value decomposition (SVD), this low-rank component captures shared information across tokens.
- Sparse correction matrix: Introduce a sparse matrix to store and correct errors for high-magnitude outlier entries that suffer large quantization error.
Streaming strategy: To improve inference speed, GEAR uses a streaming strategy: KV vectors for newly generated tokens are first stored in a small buffer and the compression of the KV cache is triggered when the buffer fills. This approach reduces additional memory overhead while maintaining high inference speed.
By combining quantization, low-rank residual approximation, and sparse corrections, GEAR achieves high compression ratios with near-lossless performance, leading to substantial throughput and peak memory improvements.
Q4: What experiments were conducted?
The paper includes a comprehensive set of experiments validating GEAR's effectiveness:
- Chain-of-thought (CoT) reasoning: Evaluations on LLaMA2-7B, LLaMA2-13B, and Mistral-7B across challenging generation tasks such as mathematical reasoning (GSM8k), multi-task language understanding (MMLU), and symbolic reasoning (BigBench Hard). Results show GEAR maintains accuracy close to an FP16 baseline while delivering high compression.
- Zero-shot generation: Zero-shot evaluations on GSM8k and MMLU for LLaMA2-7B, LLaMA2-7B-chat, and Mistral-7B. GEAR performs as well as or better than baselines across compression ratios tested.
- System performance analysis: Measurement of memory usage and system throughput during inference. GEAR substantially reduces peak memory usage, enabling larger batch sizes or longer generation lengths, and reduces memory bandwidth usage to increase throughput on limited-GPU-memory systems.
- Performance across compression ratios: Results on GSM8k and MMLU demonstrate that GEAR maintains near-lossless performance even at high compression ratios.
- Comparison to token-dropping methods: Evaluation against H2O on GSM8k shows that token-dropping cannot achieve similarly high compression without loss in performance.
- Application to fine-tuned models: Tests on fine-tuned LLaMA2-7B show GEAR still outperforms baseline methods.
- Hyperparameter sensitivity: Analysis of sparsity ratio (s) and low-rank ratio (rho) shows that small sparse and low-rank components are sufficient to achieve near-lossless accuracy.
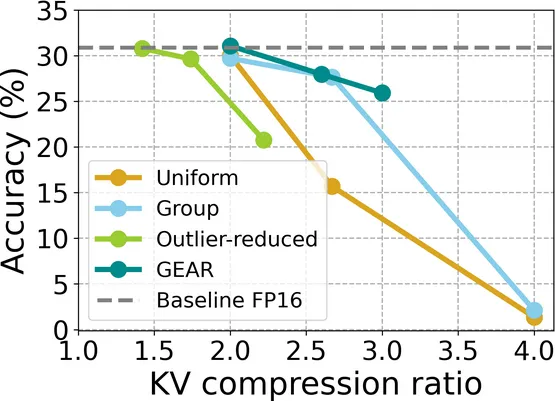
- Compatibility with different KV quantization schemes: GEAR improves performance when combined with various KV quantization schemes, including uniform and grouped quantization.
- Application with quantized weights: When model weights are already quantized to 8 bits, GEAR still significantly improves KV cache performance.
Overall, experiments demonstrate GEAR's effectiveness across tasks, models, and system constraints.
Q5: What directions are left for future exploration?
Potential directions suggested by the authors include:
- More fine-grained quantization strategies, such as content-aware quantization where quantization parameters adapt to data statistics.
- Evaluation of GEAR in multi-task and transfer learning settings, including cross-domain and cross-model transfer.
- Integration of GEAR into real-time inference systems to support low-latency, high-throughput online services.
- Hardware acceleration: use of FPGA, ASIC, or custom accelerators to speed up compression and decompression.
- Adapting compression strategies to different model architectures beyond transformers.
- Studying GEAR's behavior on tasks with long-range dependencies and complex reasoning.
- Exploring compressed sensing and sparse representations to further reduce memory footprint.
- Evaluating cross-model and cross-dataset generalization and improving robustness.
- Security and privacy considerations for compressed caches in cloud and edge deployments.
- Open-source implementation and community contributions to foster adoption and further improvements.
Q6: Summary of the paper
The paper presents GEAR (Generative Inference with Approximation Error Reduction), a hybrid KV cache compression framework for LLM inference. Key points:
- Problem: KV cache memory increases with model and sequence size, limiting throughput. Existing token-dropping or uniform quantization methods introduce significant approximation error that accumulates during autoregressive decoding.
- Approach: GEAR combines ultra-low-precision quantization for most entries, low-rank approximation for quantization residuals, and a sparse correction matrix for outliers. A streaming strategy minimizes memory overhead during online generation.
- Results: GEAR achieves near-lossless 4-bit KV cache compression, improves throughput, and reduces peak memory usage across multiple LLMs and generation tasks.
- Implication: GEAR provides a practical memory-compression strategy for LLM inference that increases system throughput while preserving generation quality.





