ALLPCB
ALLPCB


Overview
Rapid growth in the Internet of Things and industrial IoT has driven a shift from cloud-based to edge AI processing. Increasingly, devices must run AI tasks locally to reduce security risks, data transfer costs, and latency. When selecting SoCs or MCUs for IoT and industrial IoT applications, the ability to execute AI/ML workloads is becoming a key requirement.
Challenge and Approach
Embedded devices typically face constrained resources, making efficient execution of AI algorithms on embedded platforms a challenge. The engineering team examined both software and hardware approaches to simplify this task. Using the Codasip L31 RISC-V core and Codasip Studio, they explored and customized a compact AI accelerator that is tightly coupled with the CPU pipeline.
Framework and Benchmark
TensorFlow Lite for Microcontrollers (TF Lite Micro) was used as the AI framework. The L31 RISC-V core was customized and benchmarked to compare performance of the standard ISA L31 against a customized L31 augmented with AI accelerator instructions. The accelerator was implemented in under 200 lines of CodAL code, yielding more than 5x performance improvement and over 3x reduction in power consumption for the evaluated workload. These results illustrate the design flexibility of Codasip Studio and the conciseness of CodAL descriptions for processor extensions, significantly improving neural network performance on an embedded RISC-V core.
Neural Network and Test Setup
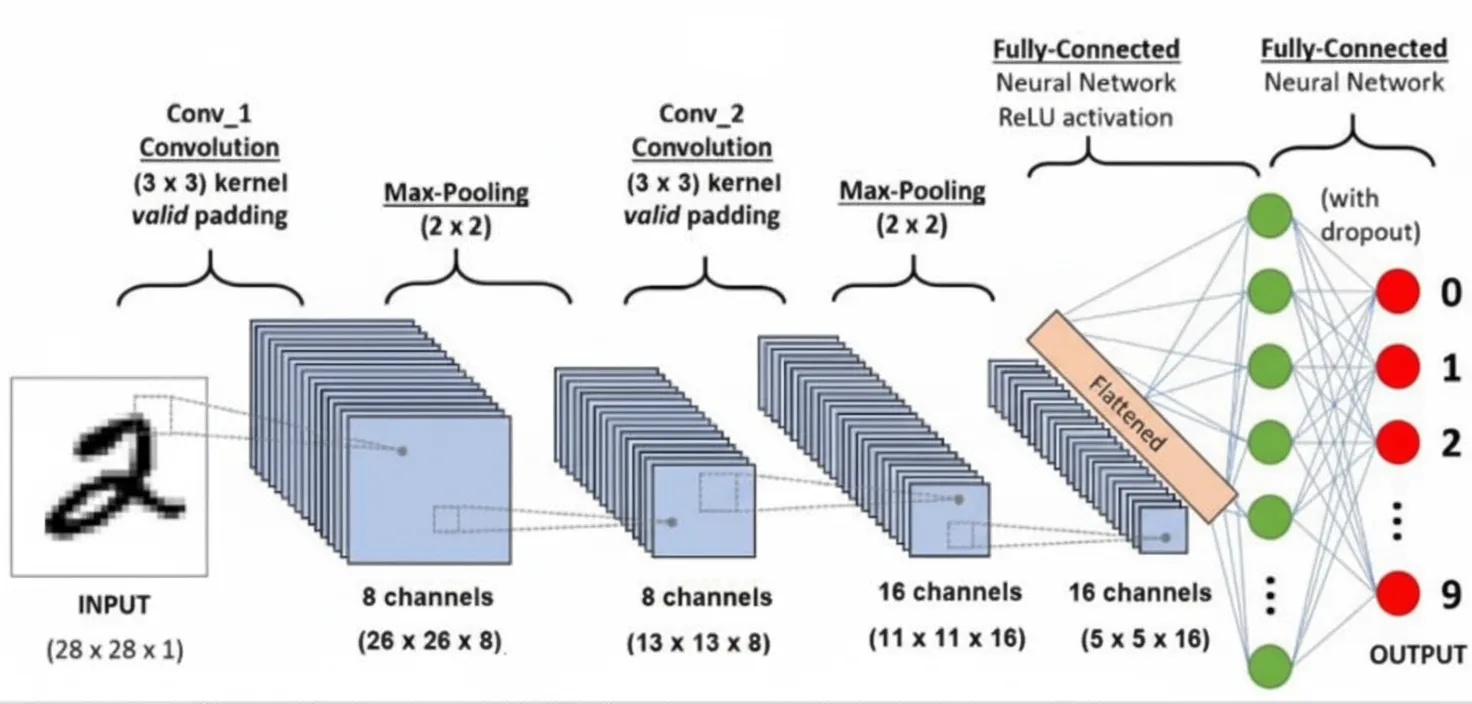
A convolutional neural network was executed with TensorFlow Lite Micro on the L31 core to perform image classification. The NN architecture includes two convolutional and pooling layers, at least one fully connected layer, vectorized nonlinear functions, resizing, and normalization operations (see Figure 1).
Profiling Results
Benchmarking showed that approximately 84% of cycles were spent in the image convolution function, which is implemented with deeply nested for loops. A 3x3 convolution on a general-purpose RISC-V processor requires 9 load instructions, 9 multiplications, and 8 additions, with additional pipeline stall overhead. Therefore, convolution was identified as the primary optimization target.
Convolution Accelerator Design
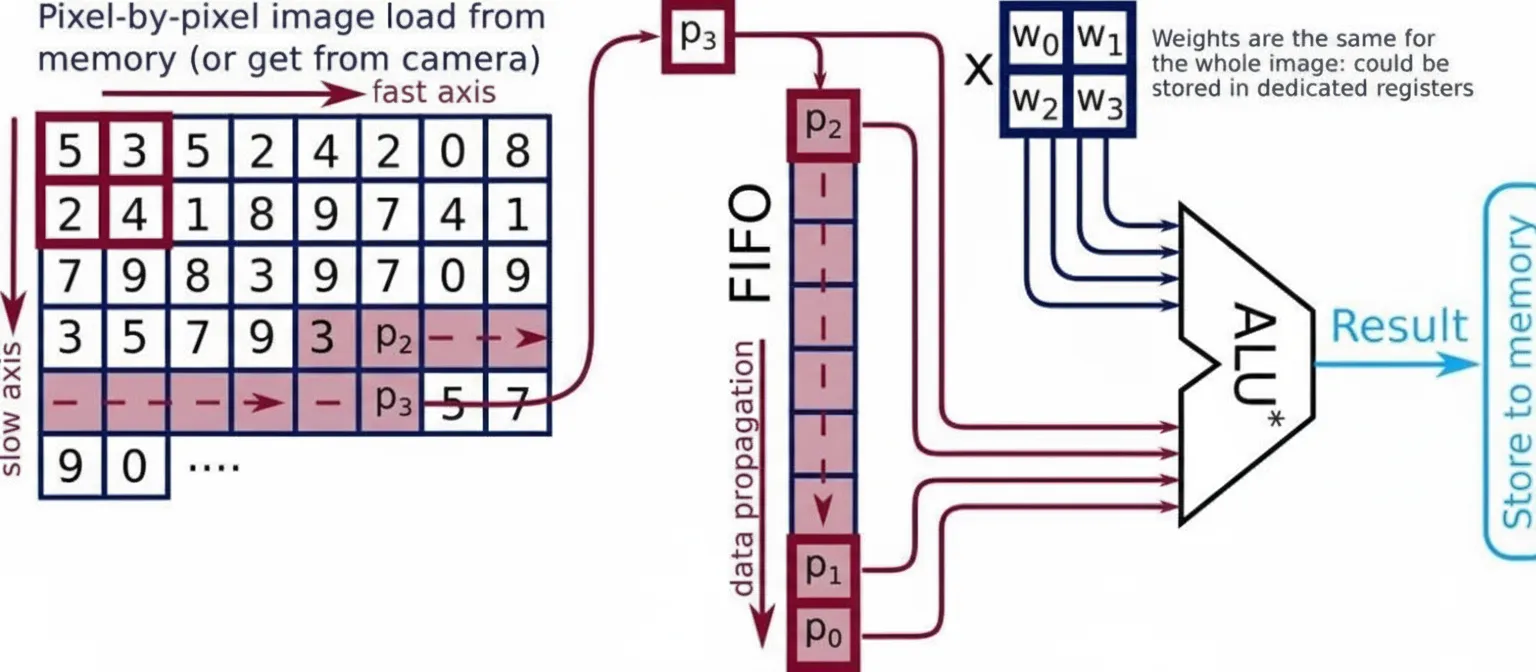
The proposed convolution accelerator is tightly coupled to the core pipeline and is based on a FIFO register chain capable of storing multiple image rows (see Figure 3). By pushing image pixels into the FIFO and reading specific FIFO elements, all data required for a single convolution can be accessed within a single processor clock cycle, avoiding repeated loads from memory. The modified ALU performs parallel multiplications of image pixels and convolution weights, accumulating the results. The accelerator is controlled by a set of custom instructions and can produce a convolution result in a single clock cycle, significantly reducing the time required for an entire image convolution.
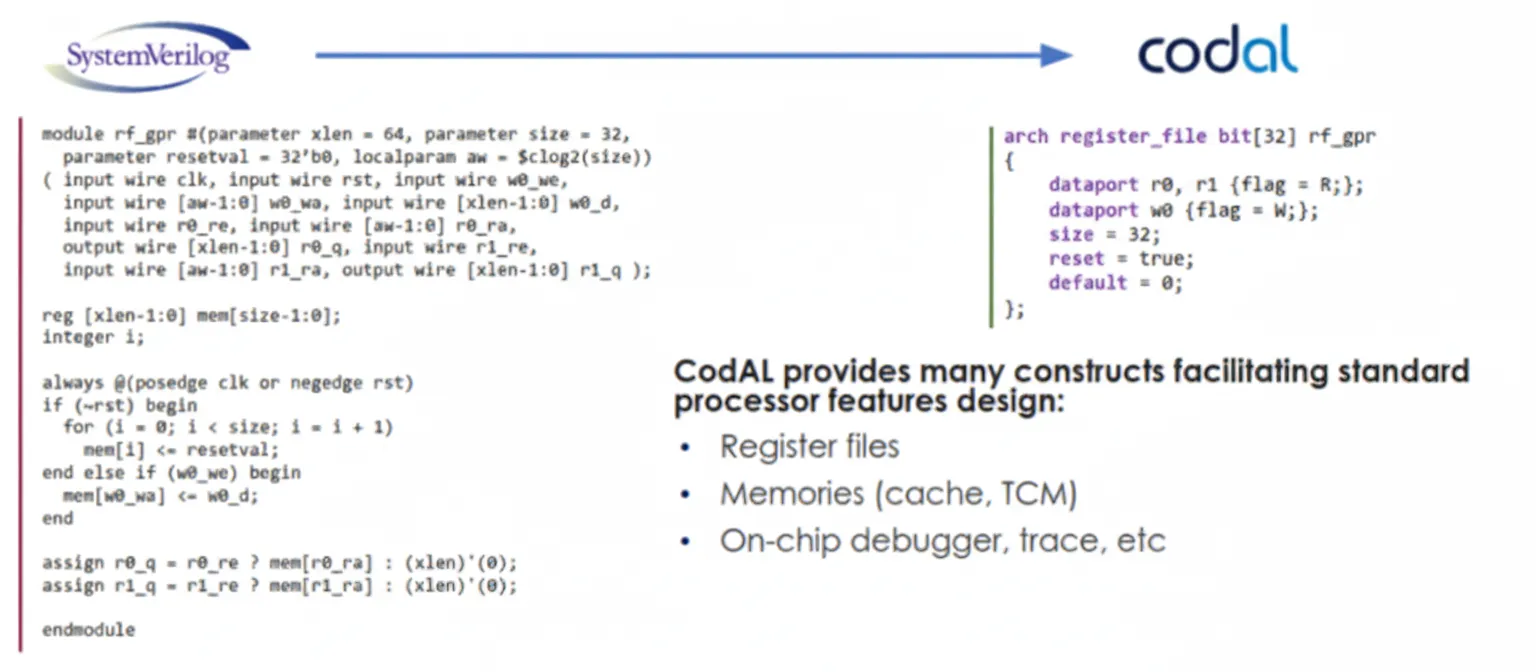
CodAL Implementation
CodAL is a high-level language designed for processor description. It simplifies the definition of standard processor features such as register files, caches, tightly coupled memories, and on-chip debuggers. CodAL descriptions are more compact than equivalent HDL code.
Owing to this conciseness, the convolution accelerator was implemented in about 200 lines of CodAL. The implementation includes hardware resource coverage and custom control instruction definitions. The resulting accelerator design supports images up to 64 x 64 and convolutions up to 5 x 5. The toolchain automatically generates compiler and analyzer support, simplifying evaluation of the accelerator's performance.
Performance and Area Trade-offs
By adding the convolution accelerator and custom instructions, the customized L31 core achieved significantly higher performance and lower power consumption than the standard L31 RISC-V core.
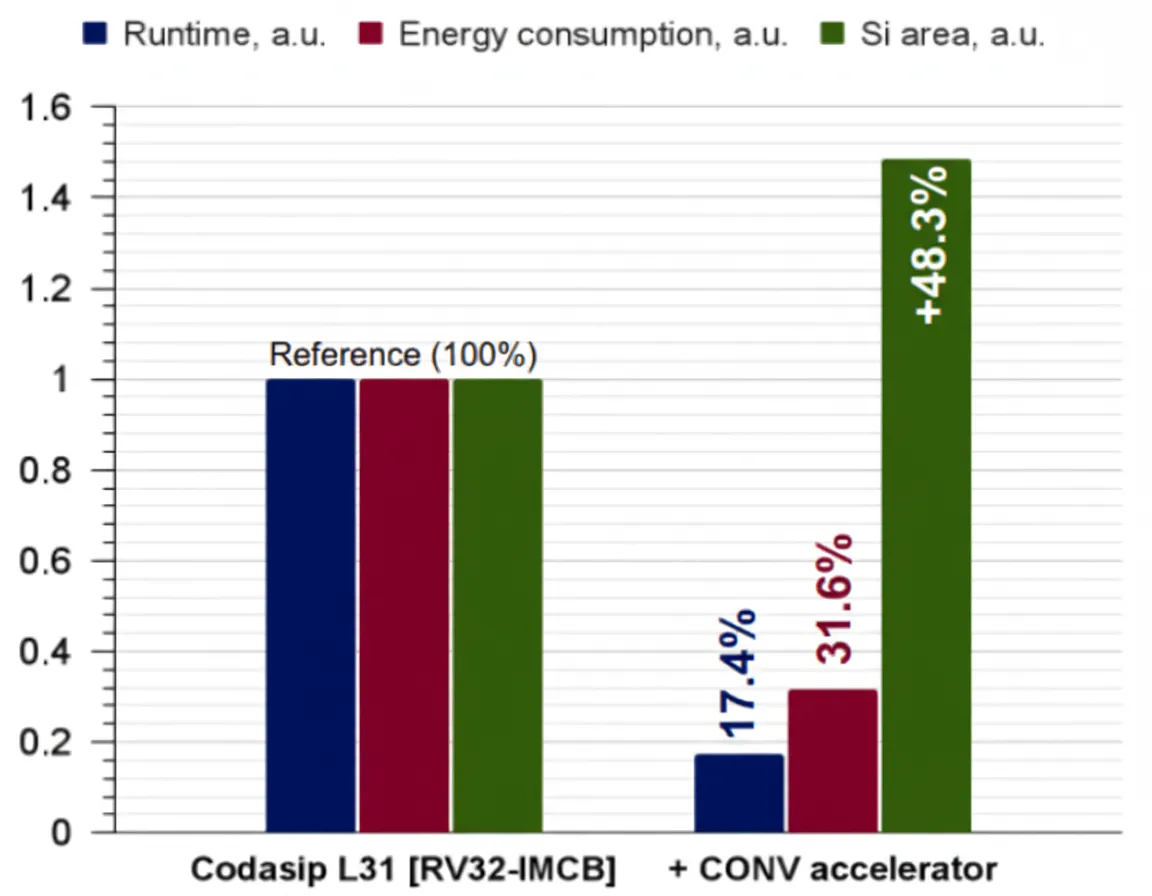
The number of clock cycles required for image classification was reduced by more than 5x, while power consumption was reduced by more than 3x. The reduction in power consumption directly affects battery life, enabling roughly three times more image classifications per charge. These improvements come with increased silicon area: the RISC-V core area increased by 48% due to additional parallel multipliers inside the convolution accelerator. For the presented workload, the area increase is justified by the performance and power benefits.
Note
AI and ML application compute requirements vary. The presented customization serves as an illustrative example and is not a complete or optimal solution for all use cases. Further PPA improvements may be achieved with alternative custom instructions or accelerator designs.