ALLPCB
ALLPCB


Overview
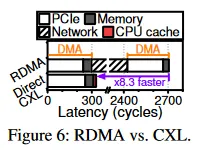
This article summarizes a presentation from ATC 22. Emerging cache-coherent interconnect protocols such as CXL have attracted attention for their hardware heterogeneity management and resource disaggregation capabilities. The authors propose DirectCXL, a directly-accessible disaggregated memory approach, and implement a CXL memory controller, CXL-capable processors, and a supporting software runtime to realize it. DirectCXL connects the host processor complex to remote memory via the CXL memory protocol (CXL.mem). Because DirectCXL avoids any data copy between host memory and remote memory, it can expose the native performance of remote disaggregated memory. Compared with RDMA-based disaggregated memory access, it achieves up to an 8.3x reduction in access time in microbenchmarks and up to 3.7x improvement on some real workloads.
Background
Disaggregated memory can improve memory utilization. Existing approaches fall into two broad categories: page-based and object-based. Page-based methods rely on virtual memory and swap remote pages on page faults without modifying application code. Object-based methods require applications to use a database (for example, a key-value store) to manage memory objects and necessitate source-code changes. All existing methods use network-based mechanisms such as RDMA to move data from remote memory into host memory. These data movements and the associated software operations (for example, page-cache management) introduce redundancy and software overhead, causing disaggregated memory latency to be orders of magnitude higher than local DRAM.
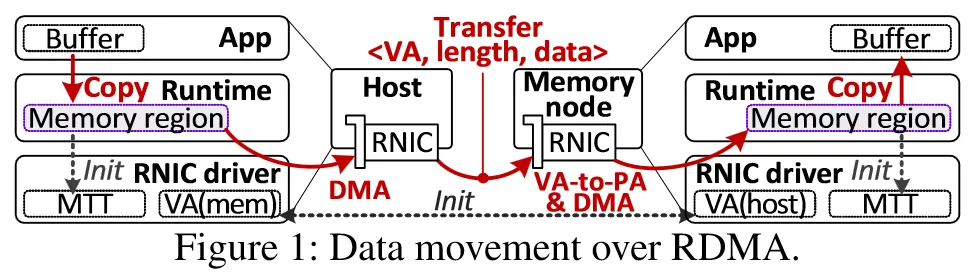
CXL (Compute Express Link) is an industry-supported cache-coherent interconnect protocol consisting of three sub-protocols. CXL.io runs on the standard PCIe physical layer; PCIe 5.0 bandwidth (about 63 GB/s) is sufficient for remote memory access. CXL.cache allows devices to cache host memory. CXL.mem allows the host to access device memory with load/store semantics as if it were local memory. These properties make CXL a promising foundation for disaggregated memory.
DirectCXL Approach
Because network-based data copies in current systems significantly degrade performance, DirectCXL connects remote memory resources directly to the CPU compute complex and enables applications to access remote memory with ordinary load/store instructions.
1. Connecting Host and Memory via CXL
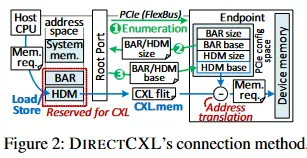
Conventional disaggregated-memory designs generally require compute resources on the remote side because traditional DRAM modules and their interfaces are designed as passive peripherals that need control logic. In contrast, CXL.mem enables host compute resources to access underlying memory over the PCIe bus (FlexBus) with semantics similar to local DRAM attached to the system bus.
In the DirectCXL model, a device-side CXL controller parses incoming PCIe-based CXL packets (CXL flits), extracts address and length information, converts them to DRAM requests, and uses a DRAM controller to service the underlying DRAM. On the host side, the CPU system includes multiple CXL Root Ports (RPs) that connect one or more CXL devices as endpoints. The host driver enumerates CXL devices at boot by querying their base address registers (BARs) and host-managed memory (HDM) sizes. The kernel driver then maps the BAR and HDM into a reserved host address region and notifies the CXL device of the mapping. When the host issues load/store instructions, requests arrive at the corresponding RP, which converts them into CXL flits. The CXL memory controller translates the target address to a device-local DRAM address and issues the DRAM access. Results return to the host via the CXL switch and FlexBus. Because this path avoids data copies and software intervention, DirectCXL can provide low-latency remote memory access. DirectCXL can also scale via CXL switches, which play a role similar to network switches within the CXL standard.
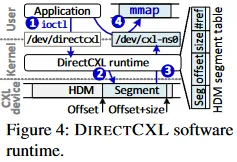
2. DirectCXL Software Runtime
Unlike RDMA, after a virtual hierarchy between the host and CXL devices is established, application processes running on the host can directly access device HDM. However, a runtime or driver is required to manage the underlying CXL devices and expose HDM into application address spaces. The authors provide a DIRECTCXL runtime that divides the HDM address space into multiple segments called CXL namespaces. The runtime allows applications to access each CXL namespace via memory mapping (mmap).
Prototype Implementation
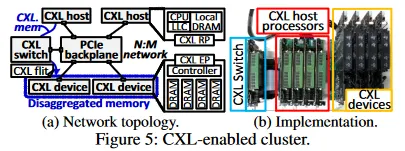
Because commercial processors, devices, and operating systems with full CXL support were not available at the time, the authors implemented a prototype. Each CXL device is implemented as a custom add-in card CXL memory blade based on a 16 nm FPGA and eight DDR4 DRAM modules. The FPGA implements a CXL controller and eight DRAM controllers to manage the endpoint and internal DRAM channels. The host processor is implemented as an in-system RISC-V-based processor supporting CXL; it has four out-of-order cores and a last-level cache (LLC) that implements a CXL Root Port. Each CXL-capable host processor runs on a high-performance accelerator card and can run Linux 5.13 and the DIRECTCXL runtime. A PCIe backplane exposes four CXL devices to four hosts (a total of 32 DRAM modules in the testbed).
Experiments
The latency breakdown for 64-byte reads shows that RDMA requires two DMA operations, and InfiniBand network overhead accounts for 78.7% of total latency. By avoiding the network and data copies, DirectCXL is about 8.3x faster in this microbenchmark.
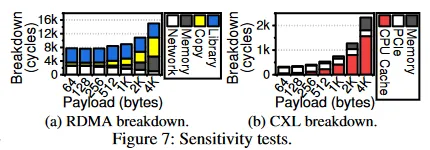
The RDMA access latency breakdown attributes time to the RDMA library, data copies, memory access, and network. At low load, RDMA library overhead dominates; as load increases, copies to registered memory regions grow and dominate. Network overhead does not decrease because network transfer and memory access overlap; the overlapping portion is accounted for as memory access. The DirectCXL latency breakdown attributes time to CPU cache, PCIe, and memory access. As load increases, CPU cache behavior slows access due to a limited miss-status-holding-register (MSHR) capacity in the prototype CPU implementation: the MSHR can only handle 16 concurrent memory misses, causing CPU stalls when simultaneous 64-byte requests increase.
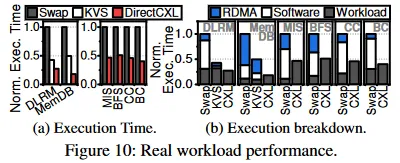
On real application workloads, DirectCXL achieved performance improvements up to about 3.0x and 2.2x in the reported experiments.
Conclusion
The authors present DirectCXL, which uses the CXL memory protocol (CXL.mem) to directly connect host processor complexes to remote memory resources. System evaluation shows that when workloads can take advantage of host processor caching, DirectCXL disaggregated memory can exhibit performance similar to DRAM. For real application processes, performance is on average about 3x higher than RDMA-based approaches.