 ALLPCB
ALLPCB



Overview
Large language models (LLMs) are reshaping how we interact with technology. However, their size often makes them resource intensive, increasing both cost and energy consumption. This article examines the relationship between model scale, hardware requirements, and financial impact, reviews current LLM trends, and discusses how smaller, more efficient models can support a more sustainable artificial intelligence ecosystem.
Understanding Model Scale: Parameters and Performance
Think of an LLM as a brain composed of billions of components called parameters. Generally, more parameters enable richer understanding and broader knowledge, much like a larger brain with greater memory and reasoning capacity. Large models can therefore behave like highly knowledgeable experts. However, that capability comes with higher computational demands and energy use, which raises operational costs and environmental impact.
Classifying models by scale helps clarify required resources. The following diagram shows model categories with representative parameter counts and examples:

Based on publicly available information where possible and industry estimates for closed models.
LLM Trends: Higher Efficiency at Smaller Sizes
The evolution of Llama models illustrates an important trend in AI: a focus on efficiency and performance rather than raw parameter count.
In August 2023, Llama 2 with 70 billion parameters was regarded as a leading base model, but its size required high-end accelerators such as the NVIDIA H100. Less than nine months later, Meta released a version of Llama 3 with 8 billion parameters, nearly a ninefold reduction. That optimization enabled the model to run on smaller AI accelerators and, in some optimized cases, on CPU-based systems, reducing both hardware cost and power draw. Notably, the 8B variant matched or exceeded predecessor performance on many accuracy benchmarks.
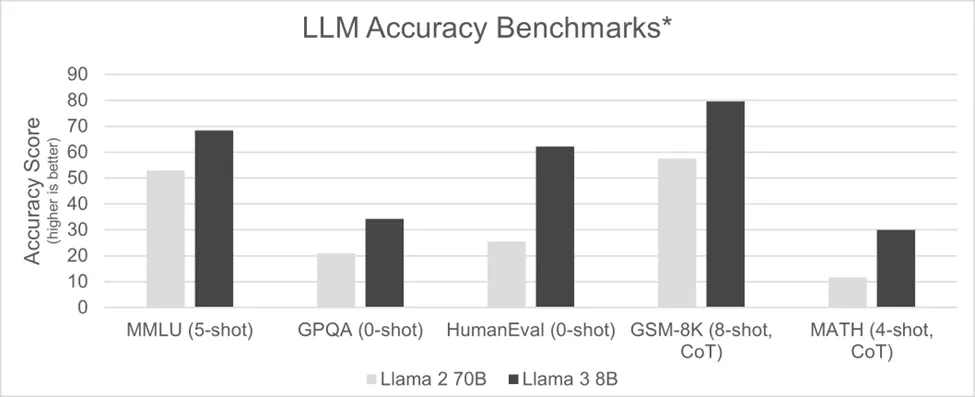
The trend continued with Llama 3.2 in September 2024, which introduced 1B and 3B variants for different application needs, and with subsequent releases that compressed larger-model capabilities into smaller parameter counts. For example, Llama 3.3 70B achieved an MMLU score of 86.0, close to the 88.6 obtained by a much larger 405B variant of an earlier release.
These results indicate that smaller model classes today can deliver comparable accuracy to previous-generation larger models while consuming fewer compute resources. This shift toward smaller, more efficient models helps broaden access to AI and improves sustainability.
Models Tailored to Specific Applications
There is a growing practice of creating specialized models through knowledge distillation. This process extracts and condenses the most relevant knowledge from a larger model and often fine-tunes it for a particular task.
In practice, many organizations do not require a generalist model with broad capabilities. For example, a sales analytics team does not need a model trained to write poetry, and an engineering team seeking coding assistance does not need a model optimized for ornithology. Distilled, domain-specific models are leaner, faster, and more efficient because they omit irrelevant knowledge.
Benefits of this approach include:
- Improved accuracy: Task-focused models can achieve higher accuracy within their domain.
- Lower resource consumption: Smaller, targeted models typically require less compute and memory, reducing cost and energy use.
- Better deployability: Domain-specific models are easier to deploy across a wider range of hardware, including optimized CPUs.
As AI systems evolve, we can expect many specialized models to appear across fields such as customer service, medical diagnosis, financial analysis, and scientific research.
Is Your AI Running Faster Than Necessary?
There is a tendency to optimize for maximum inference speed, but a more practical approach considers user needs. Extremely fast generation may be unnecessary for typical human interaction. Average reading speed for English is about 200 to 300 words per minute. Based on platform experience, an output rate of roughly 450 words per minute is often sufficient for a good user experience.
Pursuing absolute peak speed can drive up costs and increase system complexity. A balanced approach prioritizes responsive interactions without excessive resource consumption.
Cloud-Native Processors: A Flexible Option for Inference
Cloud-native CPUs offer flexibility for inference workloads through core partitioning, allowing multiple concurrent inference sessions on the same socket. In contrast, GPUs are commonly used to process a single larger session at a time. High?core-count CPUs can be partitioned to handle many smaller tasks concurrently, which can be efficient for running smaller model classes.
For many common AI applications, CPUs provide a cost-effective and scalable alternative to GPUs, particularly when models are smaller and workloads consist of many concurrent, low-latency queries.
Maximizing Per-Rack LLM Efficiency Through Compute Planning
Reducing cost per inference is key to broadening access to AI. Choosing smaller models and running them on efficient hardware increases the number of concurrent inference sessions per rack.
Most data centers limit power per rack to between 10 kW and 20 kW. Optimizing model size and hardware allows higher inference density per rack while maintaining a satisfactory user experience.
The example below assumes a 42U rack with a 12.5 kW power budget and estimates the number of inference sessions that can be run while sustaining at least 10 tokens per second (TPS):
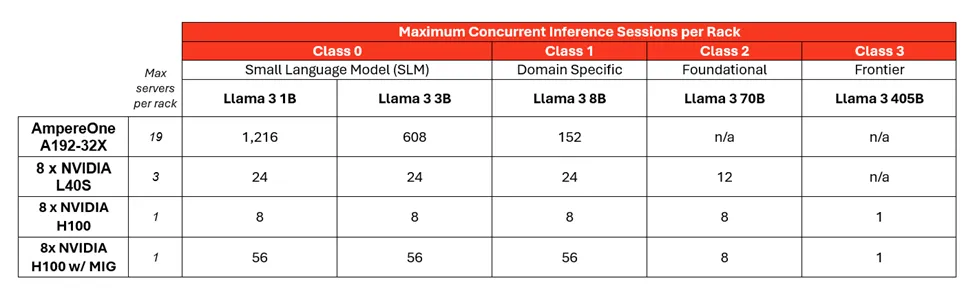
Key reasons smaller models increase the number of simultaneous inference tasks per rack:
- Energy considerations: Some cloud-native processors are designed to enable a high number of servers within a standard rack power envelope.
- Partitioning capability: CPUs with large core counts allow multiple concurrent inference sessions on a single socket.
- Software optimizations: AI optimization libraries can improve the performance of models such as Llama 3 on CPU platforms.
Building a More Sustainable AI Compute System
Optimizing models for specific applications reduces model size and complexity. Targeted models require less compute and can run on more accessible cloud-native hardware, lowering both cost and energy consumption. This approach enables individuals, researchers, and organizations of various sizes to adopt AI while supporting sustainability goals.





