 ALLPCB
ALLPCB


Introduction
Since the ChatGPT-driven artificial intelligence boom, GPUs have become the foundation for large AI model training platforms. To understand why GPUs outperform CPUs and have become central to modern AI workloads, it helps to review the core technologies behind current AI systems.
Artificial Intelligence and Deep Learning
Artificial intelligence is a long-standing field that has seen multiple waves of progress and setbacks since the 1950s. One important branch of modern AI is deep learning, which grew out of earlier attempts to model brain-like computation using artificial neural networks.
Inspired by biological neurons, an artificial neuron computes an output by weighting and summing its inputs and then applying an activation function. Each weight is a model parameter.
Connecting many such neurons produces an artificial neural network. Typical networks consist of an input layer, multiple hidden layers, and an output layer. Like a newborn brain, these networks have no innate knowledge and must be trained on large amounts of data to learn useful representations. This training process is called deep learning, a subset of machine learning.
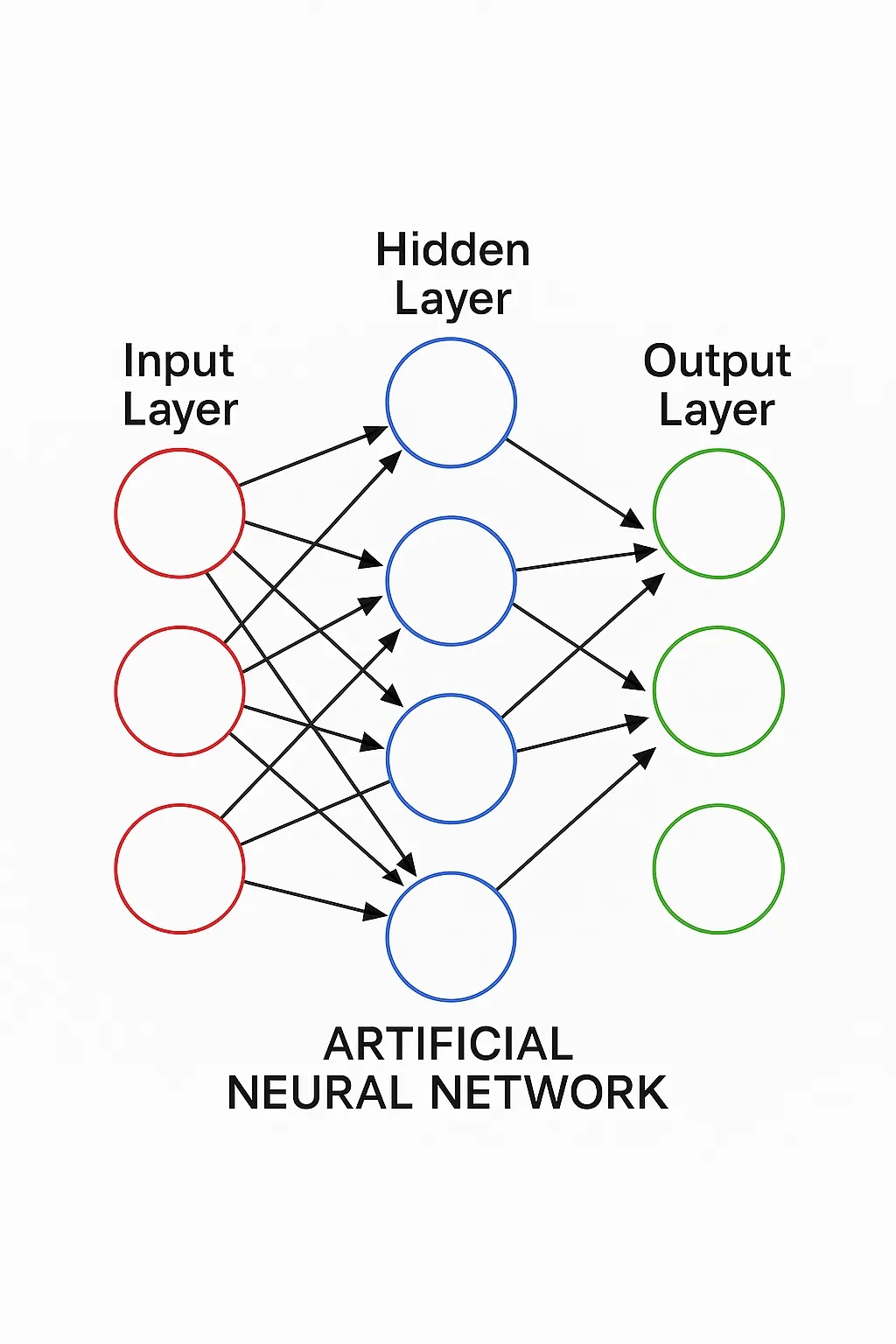
In supervised learning, the training data includes inputs paired with correct outputs. For example, to train a model to detect cats in images, you supply many labeled images showing whether a cat is present. The model computes an output using initial weights, compares it to the correct label, and then updates the weights to reduce the error. This forward-and-backward process is repeated until the model's predictions closely match the labels.
This iterative adjustment of parameters is called training. Successful training is judged by the model's ability to generalize to unseen data, i.e., to produce correct outputs for inputs not seen during training.
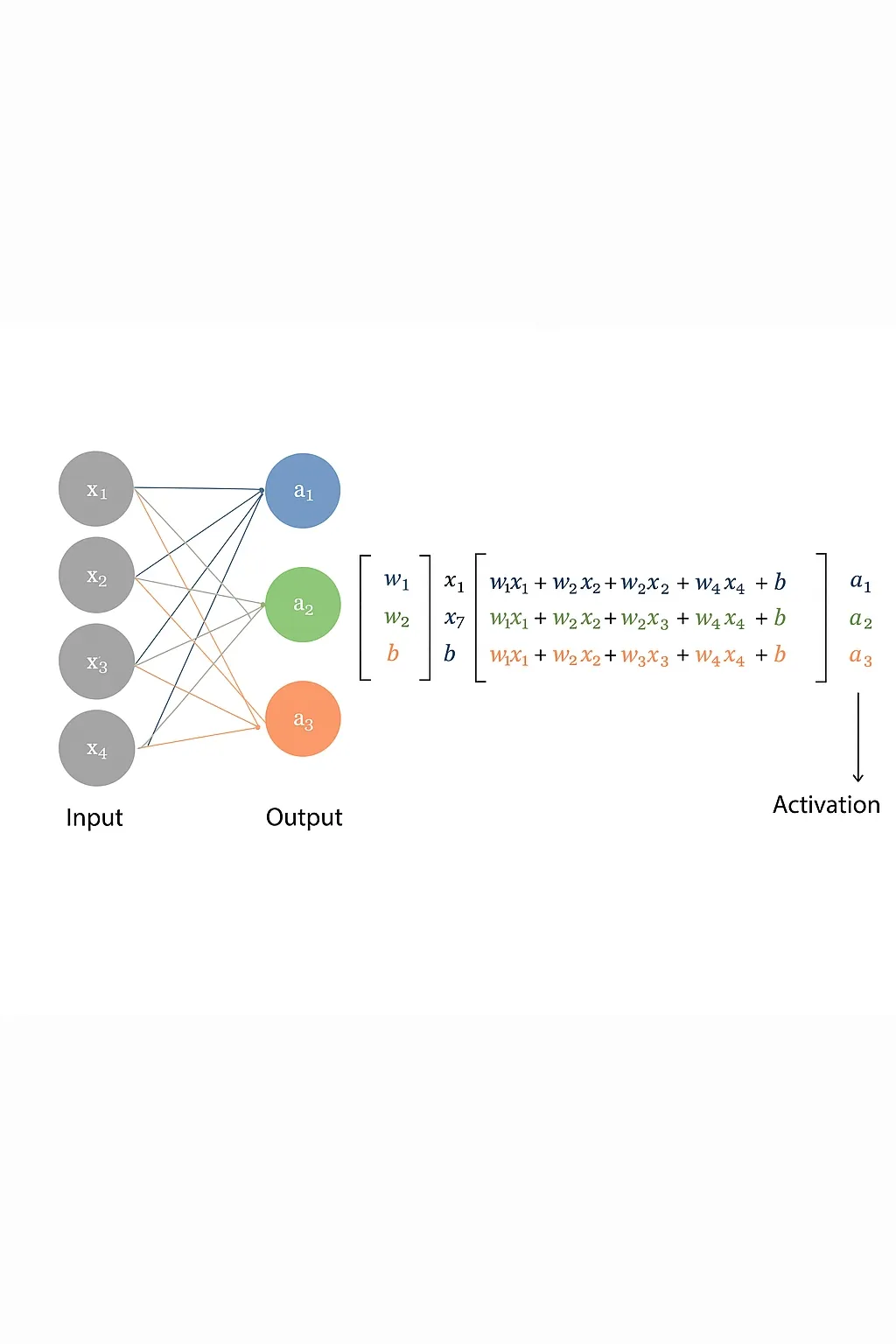
At its core, passing data from one layer to the next in a neural network is matrix multiplication and addition. As model size increases, so does the volume of these matrix operations. State-of-the-art deep learning models can have millions to trillions of parameters and require massive amounts of training data and computation. Because neural networks consist of many identical neurons, their computations are inherently highly parallel. Given this scale, which is better suited to perform these operations: CPUs or GPUs?
CPU: the Control-Oriented Processor
The CPU, or central processing unit, is the general-purpose processor and the primary control element in a computer. A CPU typically contains arithmetic logic units (ALUs), a control unit (CU), registers, and caches.
In basic operation, data is loaded from memory, the control unit fetches instructions and data, and the arithmetic units perform computation before storing results back to memory. Early CPUs had a single set of these components and could handle one task at a time. To run multiple tasks concurrently, context switching was used, which permitted time-sharing of the single core. This is the single-core CPU model.
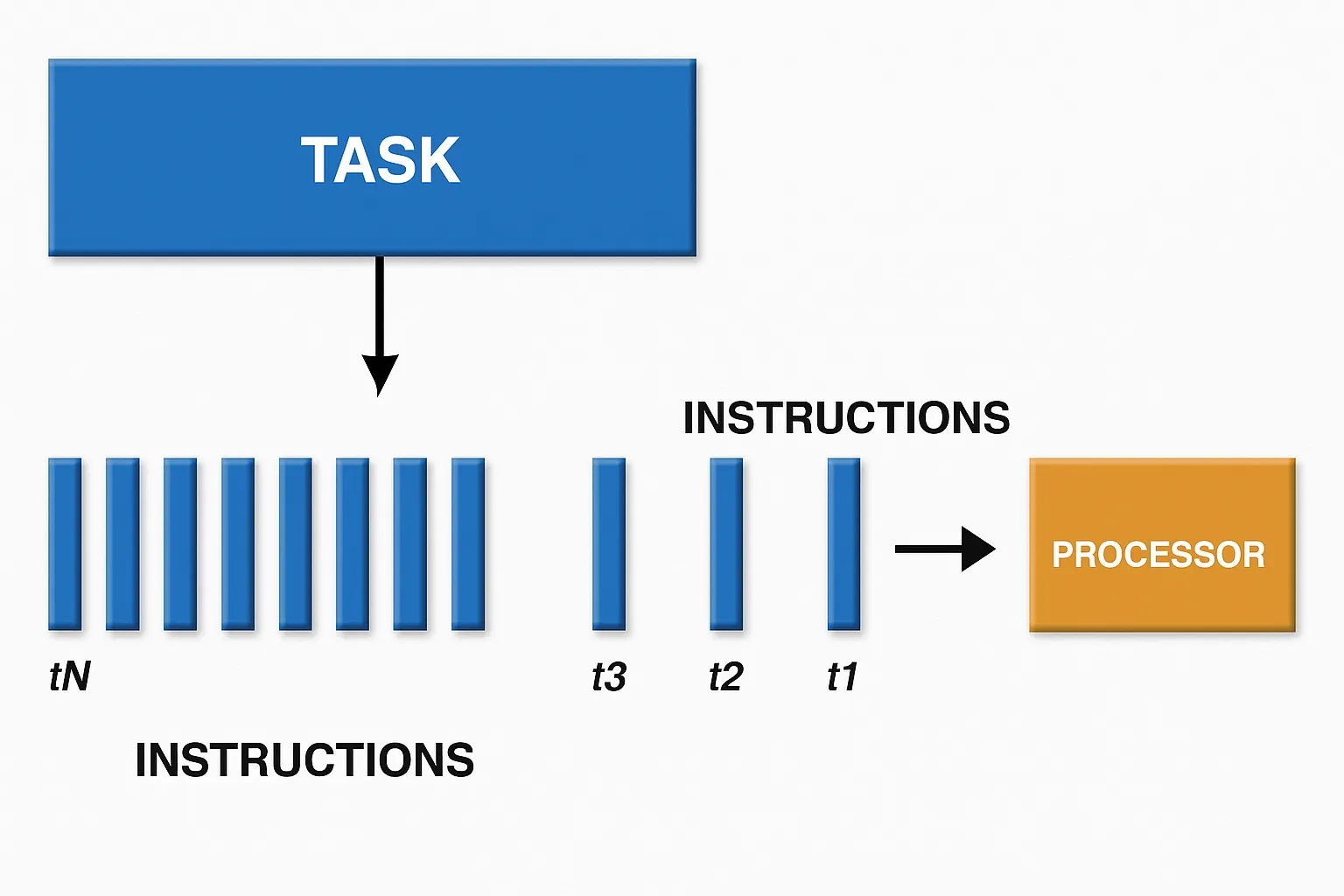
As designs evolved, multiple sets of ALUs, control units, and caches were integrated into one chip to create multicore CPUs, enabling real parallelism at the core level.
Typical multicore CPUs range from a few cores to dozens. During the early smartphone era, manufacturers emphasized core counts as a differentiator, but simply increasing cores has limits. CPUs are general-purpose processors that must handle diverse tasks and interactive workloads. This requires complex control logic, large caches, and sophisticated scheduling to minimize latency when switching tasks. Adding more cores increases inter-core communication and coordination overhead, which can reduce per-core performance and increase power consumption. If workload distribution is uneven, overall performance may not improve and can even worsen.
GPU: the Parallel Compute Specialist
The GPU, or graphics processing unit, was originally designed to offload graphics rendering from the CPU, accelerating 3D transformations, lighting, and other pixel-based computations. Images naturally map to matrices, where each pixel corresponds to matrix elements, making graphics tasks highly parallel and math-intensive.

The term GPU became popular after Nvidia introduced the GeForce 256 in 1999, a product that processed many pixels simultaneously by applying parallel mathematical operations. GPUs are effective at dense parallel computations because their architecture differs significantly from CPUs.
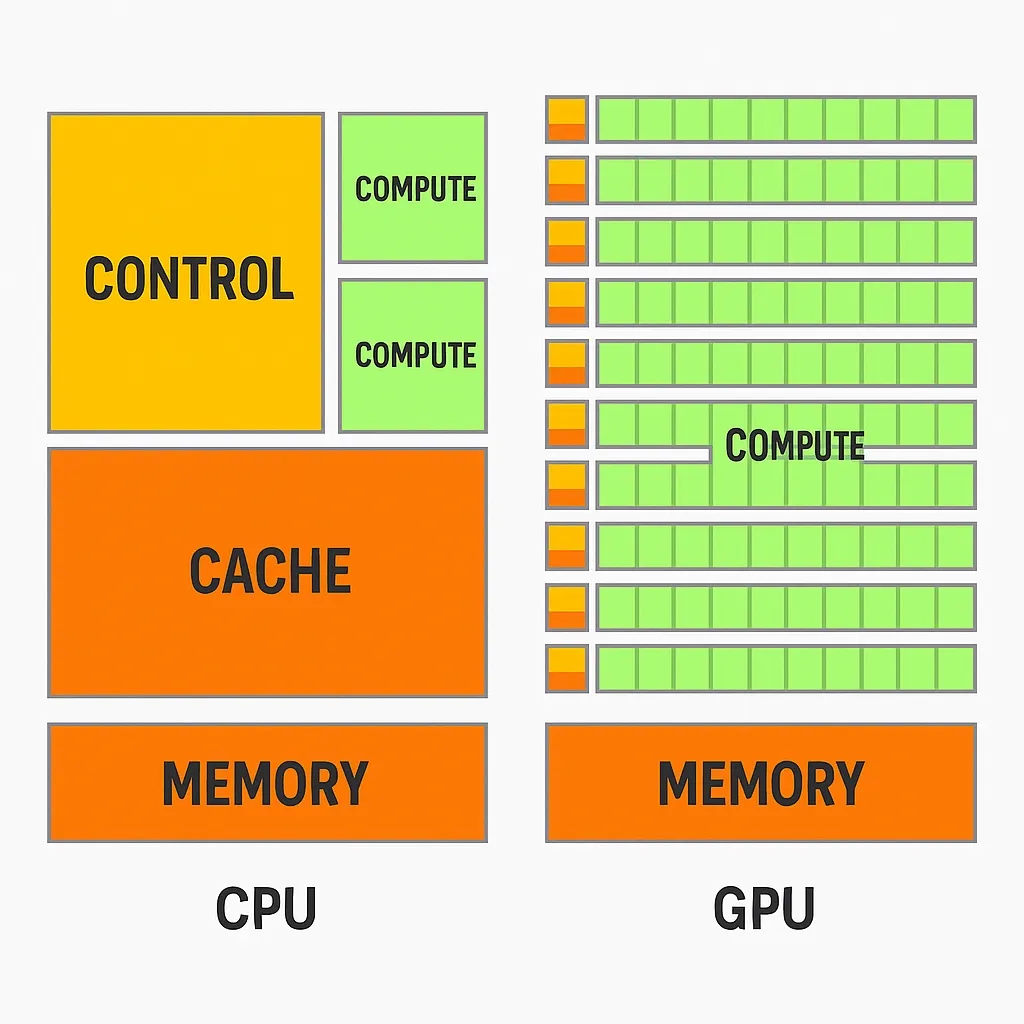
CPUs have relatively few cores, each with large caches and powerful control logic for handling complex tasks. GPUs, by contrast, use many simpler cores with smaller caches and less control overhead. The aggregate performance comes from having a large number of cores working in parallel on simple, repeatable computations.
Over time, GPUs have become more programmable and flexible, extending their use beyond graphics into high-performance computing and deep learning. This alignment between GPUs and the parallel nature of AI workloads has moved GPUs from a supporting role to the primary platform for training large neural networks. The approach of using GPUs for general-purpose computation is known as GPGPU.
Mapping AI training to GPU hardware yields substantial speedups compared with CPU-only training and makes GPUs the preferred platform for training large, complex neural systems. The parallel nature of inference operations is also well suited to GPU execution. The compute capacity provided by GPUs is sometimes referred to as intelligent computing.





