ALLPCB
ALLPCB


Overview
Companies are using both evolutionary and revolutionary techniques to significantly improve performance at the same or lower power, marking a shift from process-driven design to architecture-driven semiconductor design.
From Process Nodes to Architecture Innovation
Historically, most chips incorporated one or two advanced technologies primarily to follow lithography improvements of new process nodes, delivering predictable but modest gains. That model is changing under pressure from explosive growth in large language models and sensor data, increased competition among companies designing their own chips, and intensified international competition in artificial intelligence.
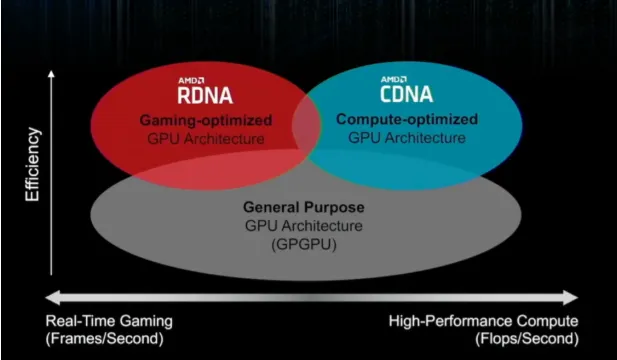
Progress now combines incremental improvements with large performance jumps. These changes lift compute and analytics capabilities to new levels but require new trade-offs. At the core are highly customized chip architectures developed on leading-edge process nodes. Parallelism is increasingly essential, and accelerators targeted at specific data types and operations are common. In some cases, these specialized systems are not intended for commercial sale but to provide a competitive advantage in data centers.
Emerging Components and Co-Packaging
Designs may also integrate other commercial technologies such as processing cores, accelerators, in-memory or near-memory compute to reduce latency, alternative caching strategies, co-packaged optical devices, and faster interconnects. Many of these advances have been researched or shelved for years and are now seeing broad deployment.
Compute Demand and System Redesign
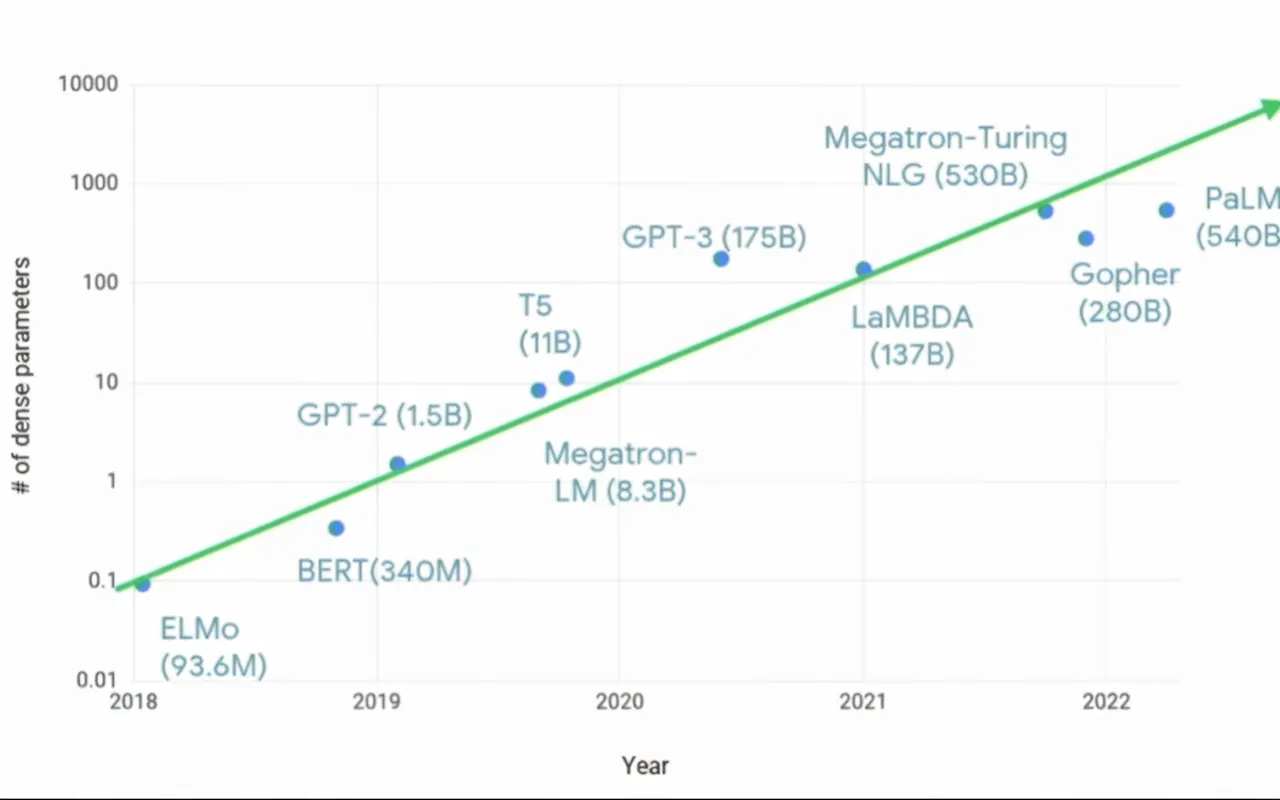
At Hot Chips 2023, Amin Vahdat of Google Research noted that modern chips solve problems that were unimaginable a decade ago, with machine learning taking on more tasks. The rapid growth in compute demand over the past five to seven years has been striking. Despite innovations in algorithmic sparsity, model parameter counts increased roughly tenfold in some cases, and compute costs rise superlinearly with parameter count. Meeting this challenge requires different compute infrastructure and a departure from some conventional design wisdom developed over the last 50 to 60 years.
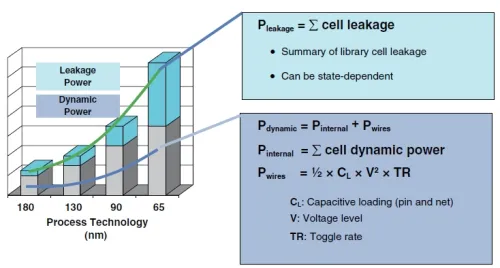
Power, Thermal Limits, and Efficiency
Power consumption and thermal management remain central design constraints and grow more difficult as clock speeds and core counts increase. Beyond roughly 3 GHz, higher thermal density and cooling limits mean simply increasing clock frequency is no longer a straightforward option. Sparse models and hardware-software co-design improve software efficiency across processing elements and allow more data per compute cycle, but per-watt performance no longer improves by a single knob. The economics shift as data volume and architectural innovations change workloads, a theme evident at Hot Chips.
Data Movement and Near-Source Processing
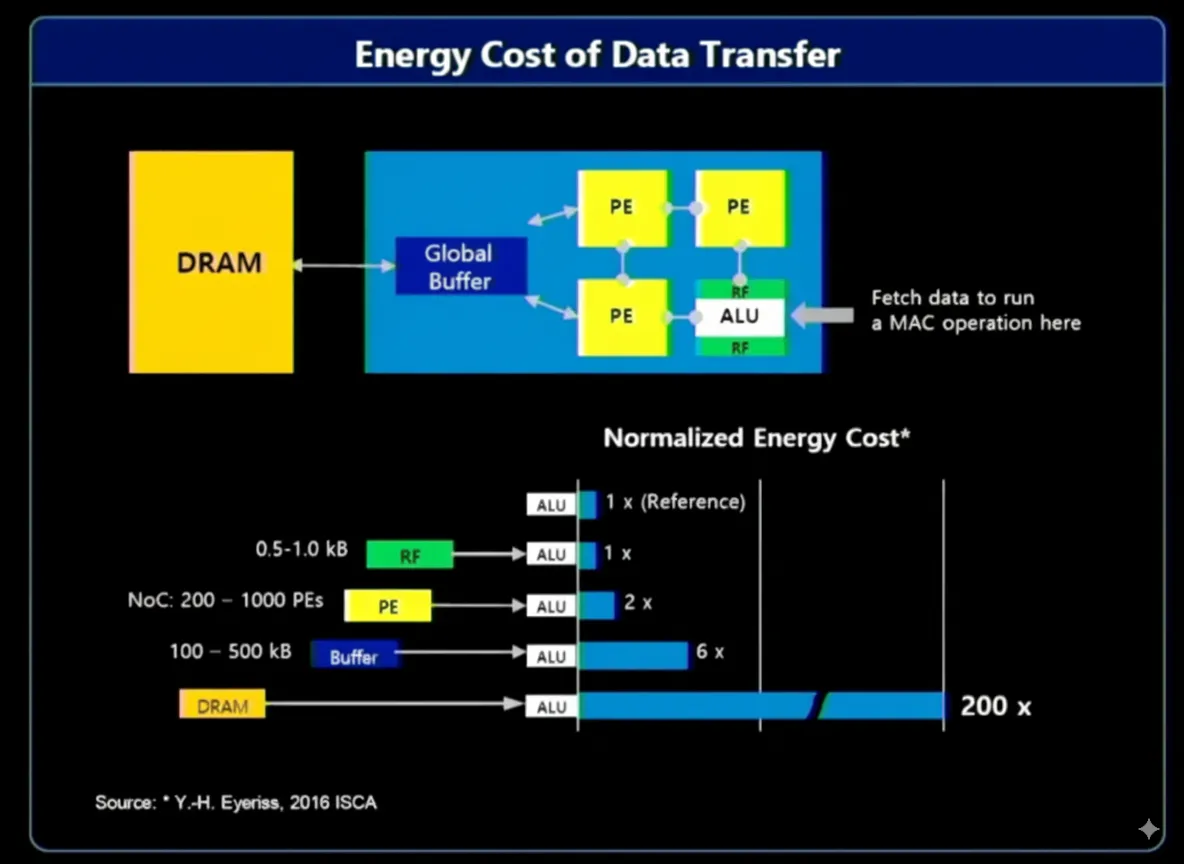
Solutions include in-memory and near-memory processing, and processing closer to the data source. Moving large amounts of data consumes bandwidth, power, and time, directly affecting compute economics. Much of collected data is irrelevant; for example, meaningful events in vehicle or security video may last only a second or two while hours of footage must be scanned. Preprocessing near the source and using AI to filter interesting events means only a small subset of data must be sent for further processing and storage.
Memory-Centric Approaches
Samsung chief engineer Jin Hyun Kim summarized three approaches to improve efficiency and performance: using HBM for very high bandwidth and power-efficient memory processing; using LPDDR for high-capacity, low-power devices; and using CXL for near-memory processing to achieve high capacity at moderate cost.
In-memory processing has been developing for years and has recently seen significant progress, driven in part by large language models. Much computation on large datasets is sparse, meaning many values are zero. Exploiting sparsity requires processing elements that are faster and more energy-efficient than general-purpose units. General-purpose processors remain necessary for diverse workload demands.
Memory acceleration is especially useful for AI/ML multiply-accumulate operations as the volume of data requiring fast access grows rapidly. Loading data for models such as GPT-3 and GPT-4 consumes substantial bandwidth. Challenges include achieving high performance and throughput efficiently, scaling to rapidly growing model parameter counts, and maintaining flexibility for future changes.
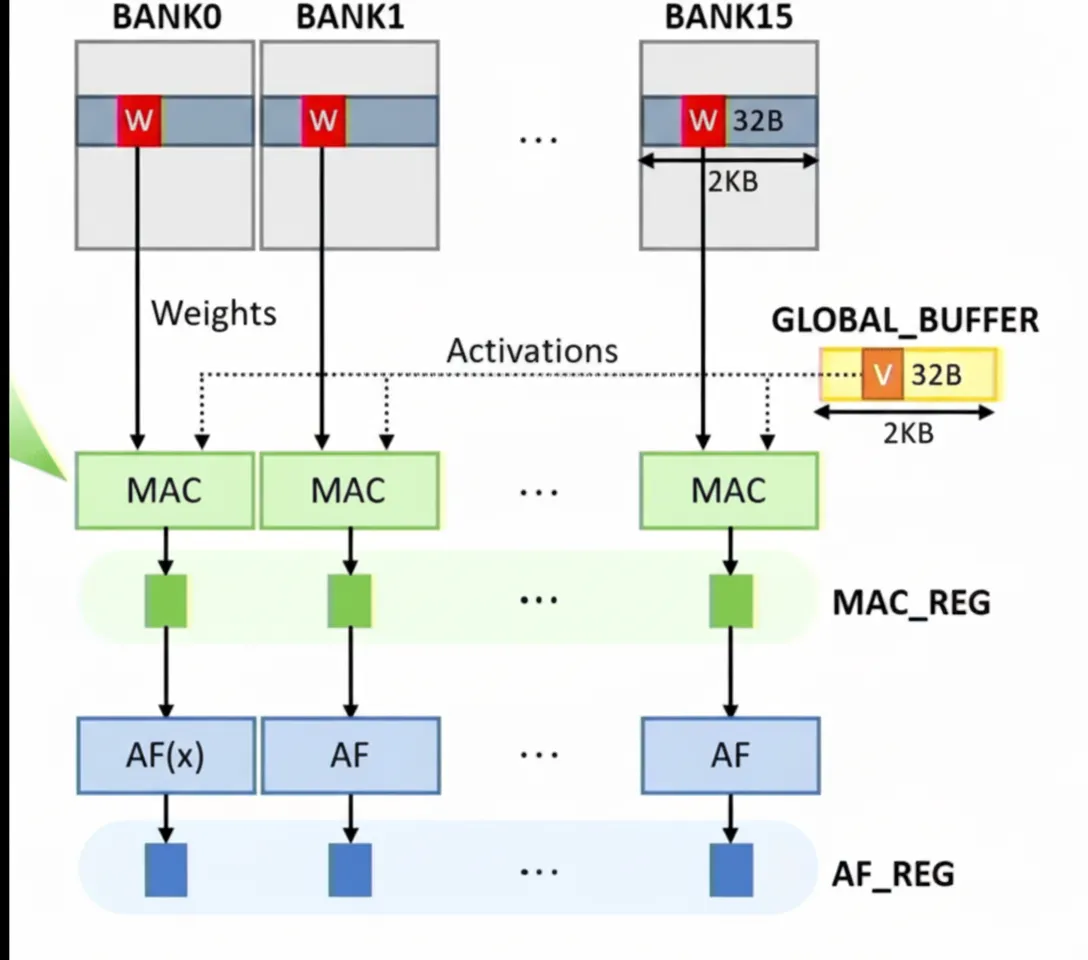
Interconnects and Scalability
Compute elements consume significant energy, and as data grows, the number of processing elements increases. Connecting these elements requires extensive interconnects, which add cost, power, or both. Moving data between computing workload cores necessitates interconnects that are highly scalable and capable of transporting large volumes of data with low power. This requires more complex network topologies and system-level management to handle large-scale data movement.
Conclusion
Chip designers face both challenges and opportunities as data and compute demands rise. Innovators are exploring new ways to increase performance, reduce power, and improve energy efficiency while optimizing data processing and analysis. Meeting future needs will require moving beyond traditional compute models and adopting more customized and innovative architectural solutions.